I am a newbie. Now I try to train 2 different model on single GPU, in parallel.
I use the multithreads. I compare to sequential models.
The time to training with multithreads is longer than sequential models.(same dataset)
I dont know why using multithreads is longer?
I think it is faster.
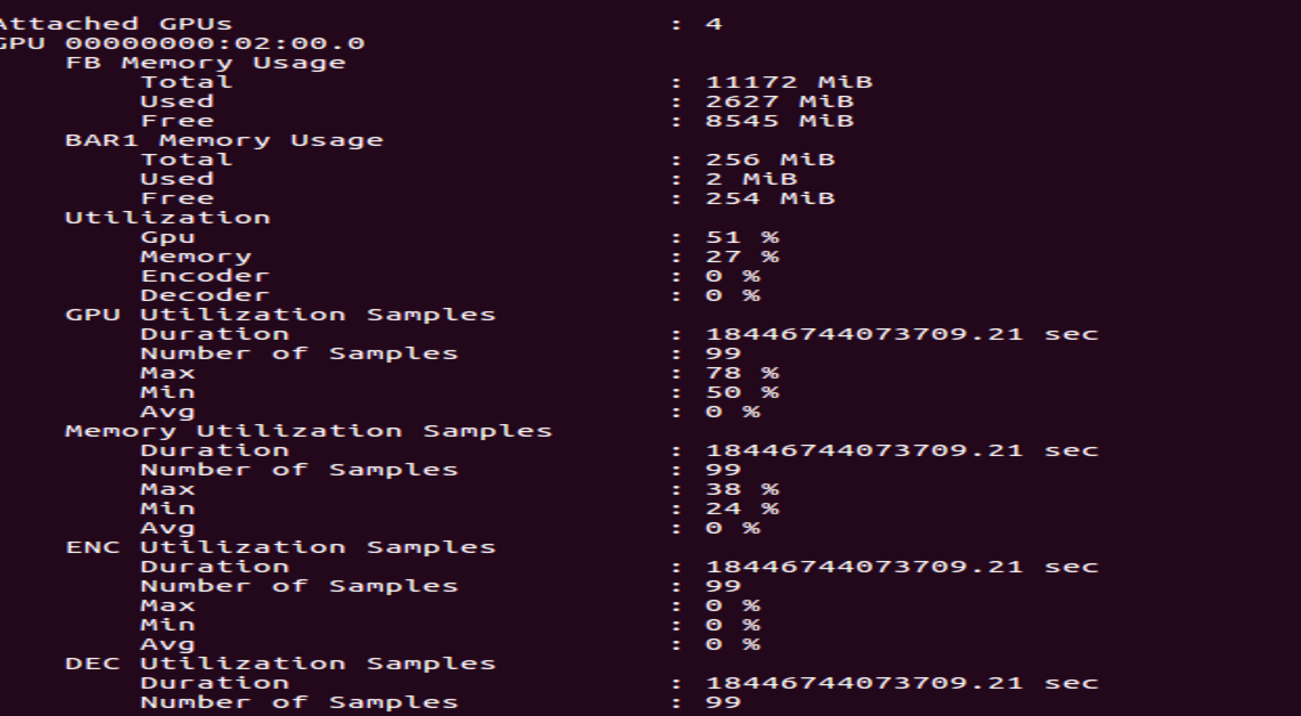
If the GPU is already fully used by a single model, trying to train a second model at the same time will just have to wait for the first one to finish and will slow things down by having to switch from one problem to the other all the time.
My point above is that even if there is some memory left, the processor is already being used fully, so you cannot do more computation: you can’t run more things at the same time.
Thank you so much!
but I still have a quuestion.
Is there any method (or function) to see the number of processor on GPU which is running?
I will run with smaller models and make a feedback later.