Hi everyone,
my team and I are developing a framework to train pytorch models through predictive coding instead of relying on backpropagation. One of the main advantages of doing this is that every layer can run independently and in parallel with the others. However we are struggling to understand how to implement this true parallelization using Pytorch.
The basic architecture is composed by several linear layers, each of which can perform its forward pass, compute their error and backpropagate it. The only synchronization step required is when computing the error (as every layer requires the data from the previous one). In pseudocode what we are aiming is the following:
def forward_and_backward(x):
# Run in parallel:
layer1.forward() # saves the output in layer1.output
...
layerN.forward()
# Run in parallel
layer1.loss(x)
layer2.loss(layer1.output)
...
layerN.loss(layerN-1.output)
# Run in parallel
layer1.backward()
layer2.backward()
...
layerN.backward()
The following pictures shows the approach clearly:
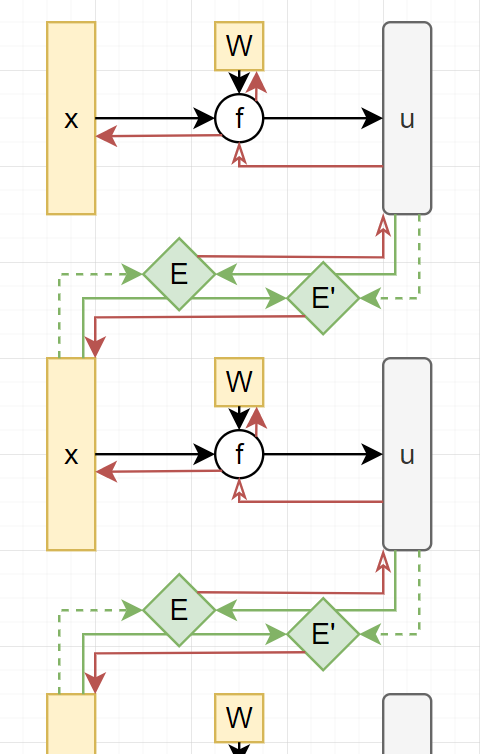
First we compute all the black arrows (forward), then the green ones (loss) and then the red ones (backward). I put two energies so I should be able to compute each x loss from the current layer and from the next layer in two steps (the dotted arrows represent detached copies of tensors) by calling first backward on all E and then on all E’. The only approach I’ve tried is with cuda streams but without getting any gains. Right now I’m simply experimenting with a fully connected nn with x independent layers that I try to run in parallel. However doesn’t matter the layers’ width or batch size I always get a linear growing in x for the execution time.
Any help on how to achieve this would be incredibly appreciated as we are starting to do heavy research on Predictive Coding and we could speed up our training/inference time by at least 10x by managing to do this. (of course also the optim step should be parallelized if it’s not already in the normal pytorch framework)