Hi,
I have a stack of images (B x 1 x W x H) where B ist the number of image.
I want to optimize translation pararameter txand ty for each image.
For some reason only the last element of tx and ty converge in an expected result.
The Gradients are converge faster to 0 for the other elements. And resulting values are not as expected.
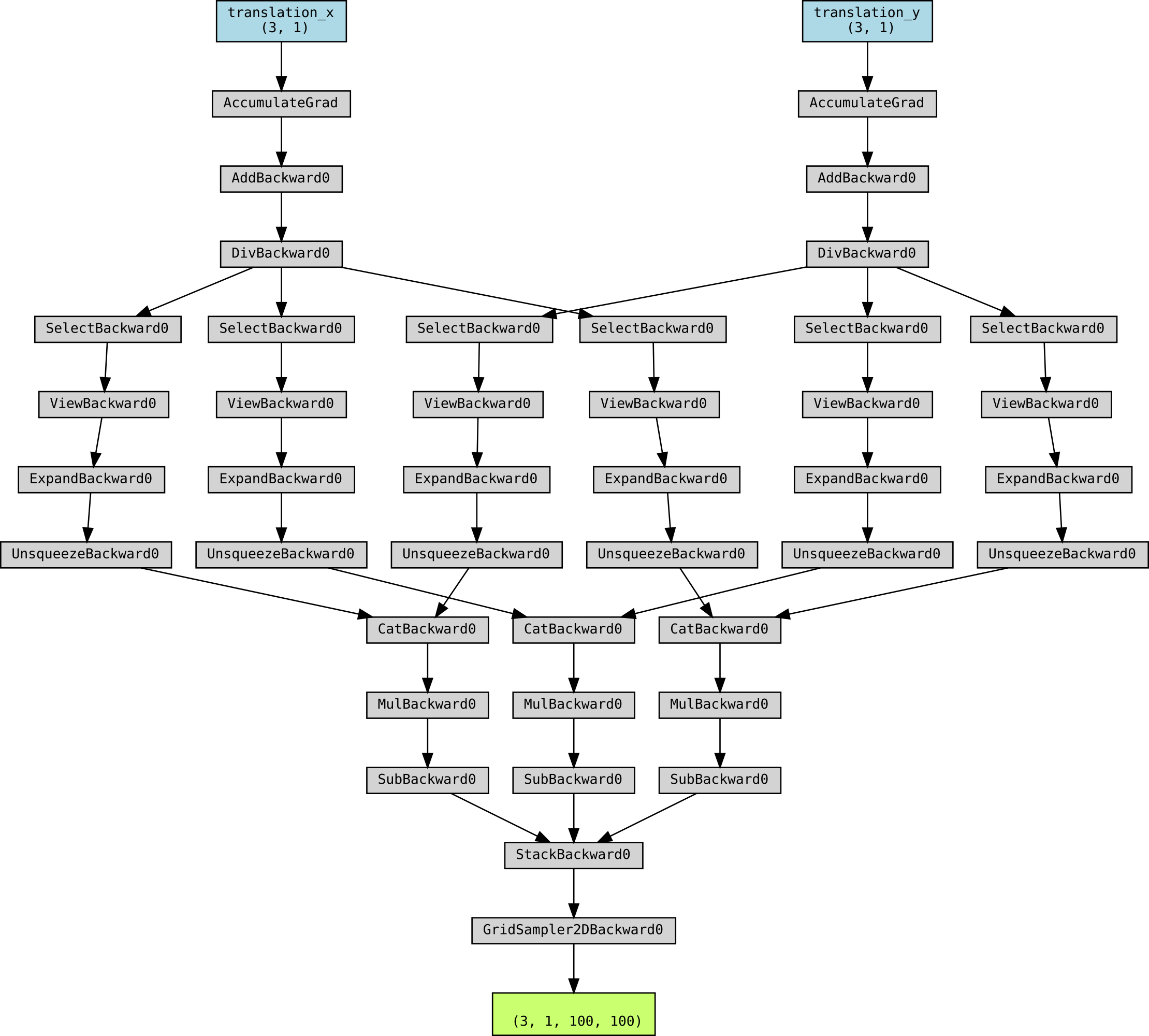
At the end I attached an pytrochvz visualisation of the gradient flow.
Can anyone tell me or point me in the direction what I miss here?
Do I have to split gradient calculation? And if so, how would I do that?
Thanks a lot in advance,
N.
#!/usr/bin/env python
import torch
from torch import nn
import torch.nn.functional as TF
import torchvision.transforms.functional as TTF
import numpy as np
import matplotlib.pyplot as plt
import imageio
import cv2
from torchviz import make_dot, make_dot_from_trace
torch.autograd.set_detect_anomaly(True)
class Translation2D(nn.Module):
def __init__(self, translation_x, translation_y):
super(Translation2D, self).__init__()
self.translation_x = nn.Parameter(translation_x)
self.translation_y = nn.Parameter(translation_y)
def forward(self, input):
b, c, w, h = input.shape
x = (torch.arange(w).repeat((b,1)) + self.translation_x)/(w-1)
y = (torch.arange(h).repeat((b,1)) + self.translation_y)/(h-1)
ddf = [torch.dstack(torch.meshgrid(x[i], y[i], indexing='xy'))*2-1 for i in range(b)]
out = TF.grid_sample(input, torch.stack(ddf)) #needs input=b,c,d,h,w, grid=b,h,w,2 #2d
return out
#constants for testing
out_path = f'./pytorch/'
b0, w0, h0 = 3, 100, 100
#get and prepare image
ex = imageio.imread(
'https://nickelquilts.files.wordpress.com/2018/04/1-half-square-triangle-block-with-copyright.jpg') / 255.
sa = cv2.resize(ex, (w0, h0)).astype(np.float32)
sa = cv2.cvtColor(sa, cv2.COLOR_BGR2GRAY)
sa = torch.tensor(sa).unsqueeze(0).repeat((b0,1,1,1))
sa_in = torch.empty(tuple(sa.shape))
#augment test input
sa_in[0] = TTF.crop(TF.pad(sa[0], [10, 0, 0, 0], 'constant', 0), 0, 0, w0, h0).clone()
sa_in[1] = TTF.crop(TF.pad(sa[1], [0, 10, 0, 0], 'constant', 0), 0, 10, w0, h0).clone()
sa_in[2] = TTF.crop(TF.pad(sa[2], [5, 0, 0, 0], 'constant', 0), 0, 0, w0, h0).clone()
b, c, w, h = sa_in.shape
tx = torch.tensor([0], dtype=torch.float32).repeat(b).reshape((b,1))
ty = torch.tensor([0], dtype=torch.float32).repeat(b).reshape((b,1))
# instantiate model
model = Translation2D(translation_x=tx, translation_y=ty)
# Instantiate optimizer
config = {'lr': 6.12693}
optimizer = torch.optim.SGD(model.parameters(), **config)
max_epochs = 50
losses = []
# dot = make_dot(model(sa_in), params=dict(model.named_parameters()), show_attrs=True, show_saved=True)
# dot.view()
for i in range(max_epochs):
optimizer.zero_grad()
pred = model(sa_in)
loss = TF.mse_loss(sa, pred).sqrt()
loss.backward()
losses.append(loss.item())
print(f'train Values x: {model.translation_x.data.T}\ny: {model.translation_y.data.T}')
print(f'train Grad x: {model.translation_x.grad.T}\ny: {model.translation_y.grad.T}')
print('---------------')
optimizer.step()
Gradient flow visualization