Hey folks,
I am new to pytorch and I am trying to parallelize my network. Using nn.DataParallel seems to work as expected for the nn.modules living inside my class, however, it looks like the nn.ParameterLists that I’m defining as class members are listed as sitting in (GPU 0) only, when I print out the module’s parameters:
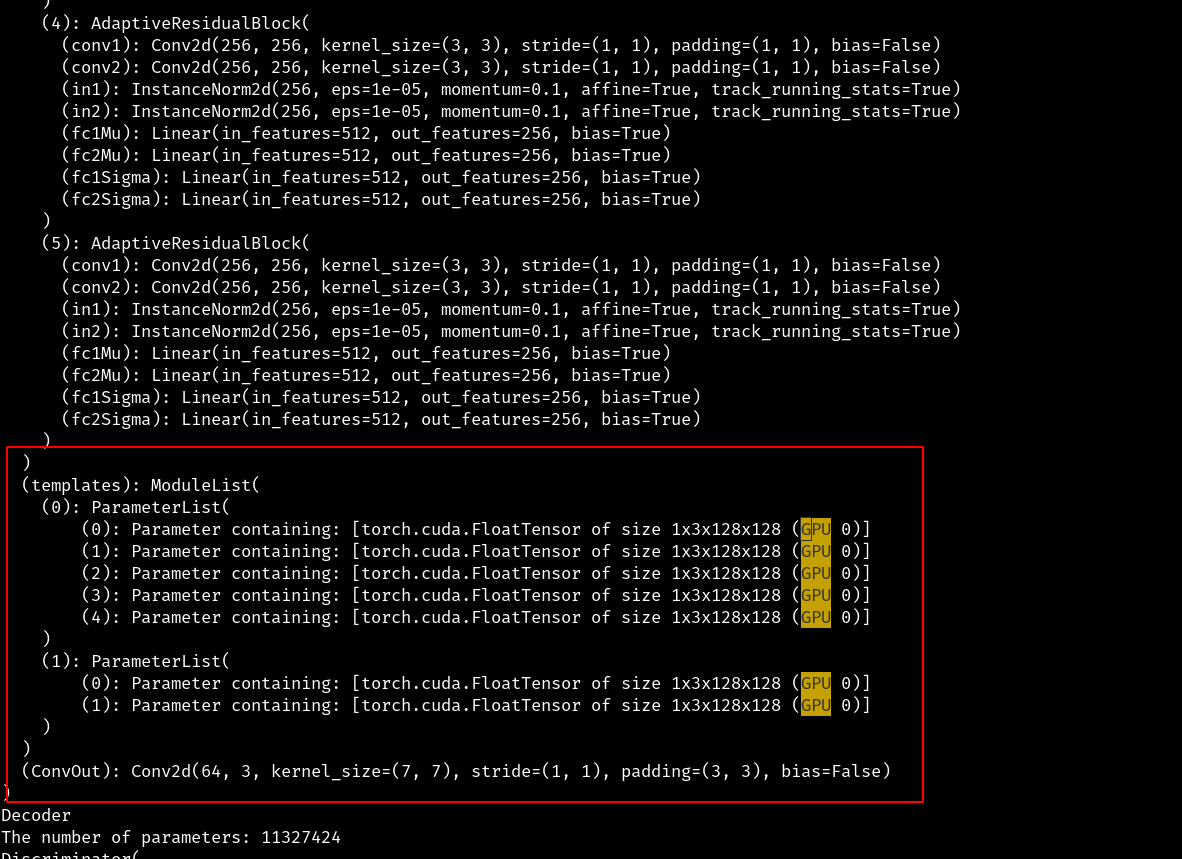
Is this expected behaviour and why are they not listed on both of the GPUs I’m using? Could somebody please explain what is going on here?
torch.cuda.device_countreturns2as expected.
My code looks something like the following:
class Network(nn.Module):
def __init__(self):
...
self.templates = nn.ModuleList([nn.ParameterList([nn.Parameter(template_init, requires_grad=True) for i in range(n)]) for n in self.num_t])
...
self.Network = nn.DataParallel(self.Network)
self.Network.to(self.device)