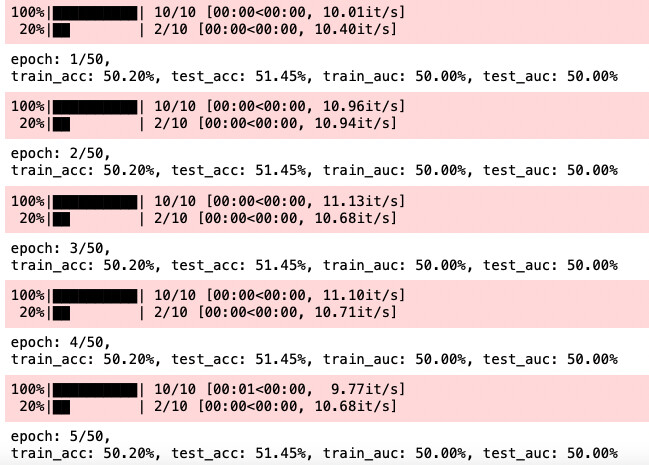
When training with random data, the loss and model parameters do not change in the for loop.
So, the accuracy is always the same. What’s wrong with my code? Thank you for checking it out.
random data
import torch
X_train = torch.randn(10000, 20, 4)
y_train = (torch.rand(10000) > 0.5).float()
X_test = torch.randn(2000, 20, 4)
y_test = (torch.rand(2000) > 0.5).float()
Dataset
import torch
from torch.utils.data import TensorDataset
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
DataLoader
from torch.utils.data import DataLoader
BATCH_SIZE = 1024
train_loader = DataLoader(train_dataset, batch_size = BATCH_SIZE, shuffle = True)
test_loader = DataLoader(test_dataset, batch_size = BATCH_SIZE, shuffle = False)
Model
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model, self).__init__()
self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_size,
num_layers=2, batch_first=True)
self.linear1 = nn.Linear(hidden_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x, _ = self.gru(x)
x = x[:, -1, :]
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
return x
x = torch.randn(10, 20, 4)
model = Model(input_size=4, hidden_size=32, output_size=1)
print(model(x))
Train
import torch
import torch.nn as nn
import torch.nn.functional as F
import tqdm
import time
import copy
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.metrics import accuracy_score, roc_auc_score
class Trainer:
def __init__(self, net, train_loader, test_loader, criterion, optimizer,
epochs=100, lr = 0.001, l2=0, cutoff=0.5, device=None):
self.net = net
self.train_loader = train_loader
self.test_loader = test_loader
self.criterion = criterion
self.optimizer = optimizer(self.net.parameters(), lr=lr, weight_decay=l2)
self.epochs = epochs
self.lr = lr
self.cutoff = cutoff
if device is not None:
self.device = device
else:
self.device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
self.train_auc = []
self.train_acc = []
self.val_auc = []
self.val_acc = []
self.best_model_wts = copy.deepcopy(self.net.state_dict())
self.best_acc = 0.
def fit(self):
since = time.time()
for epoch in range(self.epochs):
running_loss = 0.
self.net.train()
ys = []
y_preds = []
for i, (X_batch, y_batch) in enumerate(tqdm.tqdm(self.train_loader, total = len(self.train_loader))):
X_batch = X_batch.to(self.device, dtype=torch.float)
y_batch = y_batch.to(self.device, dtype=torch.float)
y_pred_batch = self.net(X_batch).reshape(-1,)
loss = self.criterion(y_pred_batch, y_batch)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
running_loss += loss.item()
y_pred_batch = (y_pred_batch > self.cutoff).float()
ys.append(y_batch)
y_preds.append(y_pred_batch)
ys = torch.cat(ys)
y_preds = torch.cat(y_preds)
train_acc_ = accuracy_score(ys.to('cpu'), y_preds.to('cpu'))
train_auc_ = roc_auc_score(ys.to('cpu'), y_preds.to('cpu'))
self.train_acc.append(train_acc_)
self.train_auc.append(train_auc_)
# 검증 데이터의 예측 정확도
val_acc_, val_auc_ = self.eval_net(self.test_loader, self.device)
self.val_acc.append(val_acc_)
self.val_auc.append(val_auc_)
# epoch 결과 표시
print('epoch: {}/{}, \ntrain_acc: {:.2f}%, test_acc: {:.2f}%, train_auc: {:.2f}%, test_auc: {:.2f}%'.format(epoch + 1, self.epochs,
self.train_acc[-1] * 100, self.val_acc[-1] * 100, self.train_auc[-1]*100, self.val_auc[-1]*100))
print('best acc : {:.2f}%'.format(self.best_acc * 100))
def eval_net(self, data_loader, device):
self.net.eval()
ys = []
y_preds = []
for X_batch, y_batch in data_loader:
X_batch = X_batch.to(device, dtype=torch.float)
y_batch = y_batch.to(device, dtype=torch.float)
with torch.no_grad():
y_pred_batch = self.net(X_batch).reshape(-1,)
y_pred_batch = (y_pred_batch > self.cutoff).float()
ys.append(y_batch)
y_preds.append(y_pred_batch)
ys = torch.cat(ys)
y_preds = torch.cat(y_preds)
acc = accuracy_score(ys.to('cpu'), y_preds.to('cpu'))
auc = roc_auc_score(ys.to('cpu'), y_preds.to('cpu'))
if acc.item() > self.best_acc:
self.best_acc = acc
self.best_model_wts = copy.deepcopy(self.net.state_dict())
return acc.item(), auc
from torch import optim
loss = nn.BCEWithLogitsLoss()
optimizer = optim.Adam
trainer = Trainer(model, train_loader, test_loader,
criterion=loss, optimizer=optimizer,
epochs=10, cutoff=0.5, lr=0.001)
trainer.fit()