Hi all.
I am trying to convert ultralytics YOLOv11 to tensorRT. I get a parity mismatch (the output tensors from the torch model do not match the output tensors from the tensorrt model).
Has anybody encountered this issue in the past?
Experimentation:
I am using torch.compile to convert the torch model to tensorrt. (in the past, I have tried using torch.onnx.export to convert the model to onnx, and I observe similar parity mismatch there as well [issue LINK])
Minimum Code for reproducibility:
Step 1: modification to the ultralytics codebase to output tensors from every layer:
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True.
visualize (bool): Save the feature maps of the model if True.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
layer_outputs = [None] * (len(self.model)-1) #-------> store the output for every layer. used for parity comparison
for layer_idx, m in enumerate(self.model):
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(torch.nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
if layer_idx < (len(self.model)-1):
layer_outputs[layer_idx] = x.clone()
return x, tuple(layer_outputs)
Step2:
Running the model compilation + parity test:
import torch
from ultralytics import YOLO
import torch_tensorrt
if __name__ == "__main__":
torch.cuda.synchronize()
model_torch = YOLO("yolo11n.pt").model.to(device='cuda')
input_tensor = torch.randint(0, 255, (1, 3, 480, 640), device='cuda').float() / 255.0
layers = list(model_torch.children())[0]
trt_model = torch.compile(model_torch, backend="tensorrt")
with torch.no_grad():
trt_out = trt_model(input_tensor)
torch_out = model_torch(input_tensor)
for i in range(len(torch_out[1])):
print(f"max_delta[{i}] - [{type(layers[i])}] = {torch.max(torch.abs(trt_out[1][i] - torch_out[1][i]))}")
print(f"max_delta[{i+1}] - [{type(layers[-1])}] = {torch.max(torch.abs(trt_out[0][0] - torch_out[0][0]))}")
On running this test, I get the max-delta for each layer to look something like this:
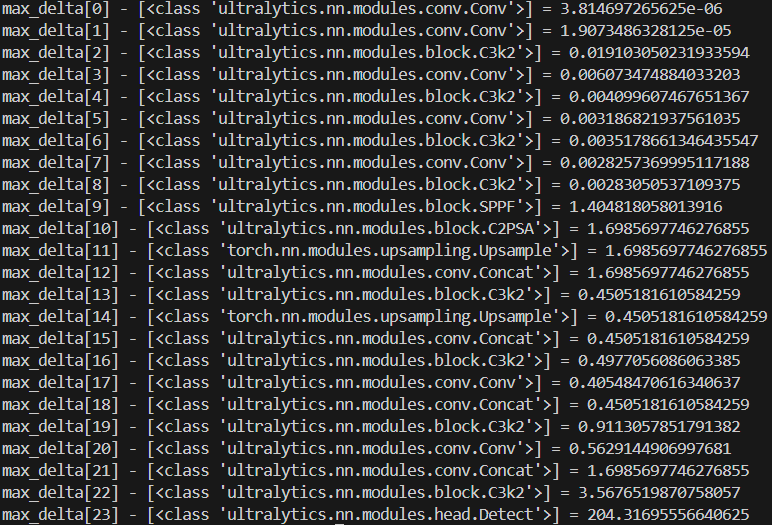
as we can see here, the max delta for some of the layers is very high. can anybody help me figure this out?