Hi, I am working on a classification problem. I want to use age and sex features from metadata and concatenate these with features extracted from CNN. Since CNN accepts only numerical data, how can I use sex and age (present in format 89Y, 55Y, 45Y and so on)? I looked into nn.Embedding and tried the following code:
However, every time I run the code, different embedding is generated for the specified key, if embedding for the same key (say F) is different every time, then how it will help the classifier layer when used in combination with CNN features? Moreover, since sex has only two categories and age has 5 categories, in this case, nn.embedding should be used?
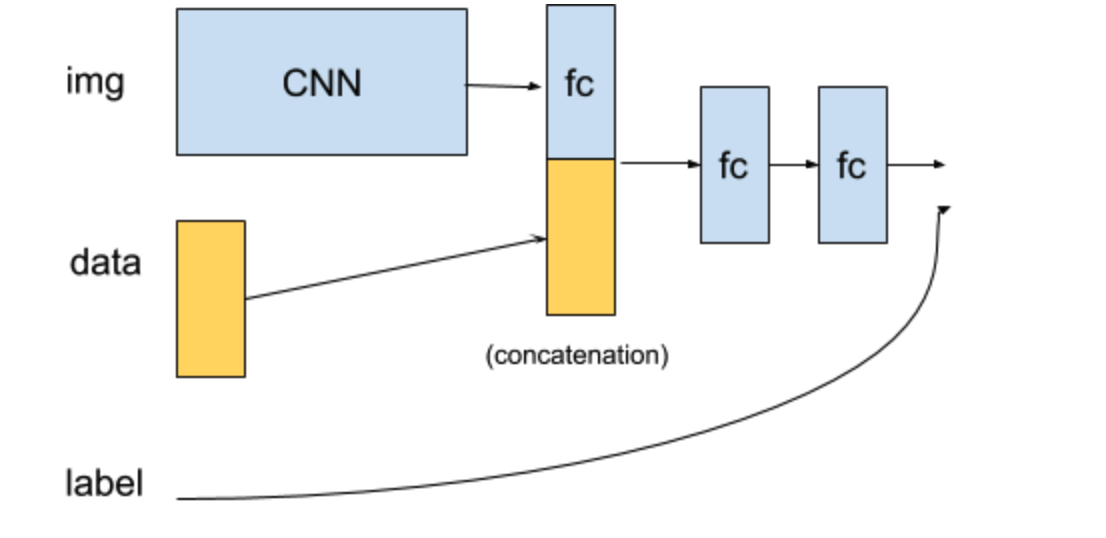
Hi @tom, this is an image classification problem. Images have metadata consisting of categorical data. Since the categories are fixed, I just want to encode them and concatenate them with the learned CNN features and finally pass them to the final classifier. In this case, do I need to train the embeddings too? I feel it’s not required, since it’s not NLP problem, I want to use encoded vector of fixed categories in metadata to be used as a feature to aid the final image classification.
What I am doing is:
torch.manual_seed(1)
embed_dict = {}
word_to_ix = {"F": 0, "M": 1}
embeds = nn.Embedding(2, 5) # 2 words in vocab, 5 dimensional embeddings
for i, value in enumerate(word_to_ix.keys()):
lookup_tensor = torch.tensor([word_to_ix[value]], dtype=torch.long)
embed_dict[value] = embeds(lookup_tensor)
print(hello_embed)
I have created the embedding vectors for the sex category, is it the correct way? I plan to concatenate these embeddings with respective features now.
I’m not entirely sure I understand what your setup is, but really, categorical data wants to be embedded to feed into a neural network. One way to look at the embeddings is that it is one-hot encoding followed by a linear layer.
@tom this is what my problem looks like. I have images and they have categorical data (sex: F, M, and age in the format: 55Y, 65Y, 85Y and so on) associated with them. I want to extract features from images using CNN, and after that concatenate the categorical features with extracted features.
Now since the neural network only accepts numeric values, I am using the Embedding layer to convert the categorical features to vectors. I do not want the network to learn the embeddings since my final problem is image classification. I just want to use both image features and metadata features to aid classification.
So basically my objective is to just use embedding once to give me numeric vectors for sex and age features. I am quite not sure how do I need the Embedding layer for that, I am not from NLP background and I am not sure the Embedding layer is returning me what I want.
Naive question, what’s wrong with just using a series of increasingly larger fully-connected layers to include the age and sex data as well? Age data is already numeric (I don’t think it’s quite categorical since proximity matters, i.e. 88 and 89 are closer together than 1 and 88 are, so this data is more continuous than categorical). Sex is categorical and can be represented by a one-hot encoding (i.e. a length-2 Tensor with a 1 and a 0 depending on the sex).
So I think I’m discussing something not quite like your setup but related in my How many models is ResNet blog post.
The gist of it is that very likely, you could either use one-hot encoding and not train or you should just train the embeddings. A more detailed option could be to use randomly initialized embeddings or randomly initialized and then orthogonalized ones. What you should avoid is to re-initialize the layer with new random embeddings at every forward (your code snippets seems and discussion in the initial post hint towards this).
@Andrei_Cristea , I used one-hot vector for sex and scaled age as well, however, there was not much improvement in prediction. Before it was 74.2, now it’s 74.9.
@aleemsidra sorry to hear you didn’t get any meaningful improvement
A handful of things I can think of that could be worth trying:
Make sure there’s not an arbitrary dependency of model performance on the scale of these additional inputs. We don’t want the exact representation of the information to impact your training, but in practice it almost certainly will. The one-hot encoding of sex feels pretty standard, but you might want to normalize the age variable across your data (the same way you’d normalize pixel representations) such that it has an average of 0 and stdev of 1.
Make sure the optimizer you’re using can support different / adaptive learning rates for different parameters. In other words, if your attempt so far used vanilla SGD, definitely try Adam optimizer. This is a good idea on typical computer vision tasks, but even moreso in this case I would imagine, since you have very different types of inputs coexisting in the same network, and you’d like each of them to be able to learn at the appropriate rate.
Try logging the age variable (and then normalizing it). A deep enough model trained on enough data probably wouldn’t care if you log the input or not, but in a shallow model it might help. The idea here is to represent your age input in a way that acknowledges that e.g. a 5 year age difference is more important at low ages (going from age 1 to age 6, for example) than at high ages (going from 55 to 60).