Dear @mrshenli,
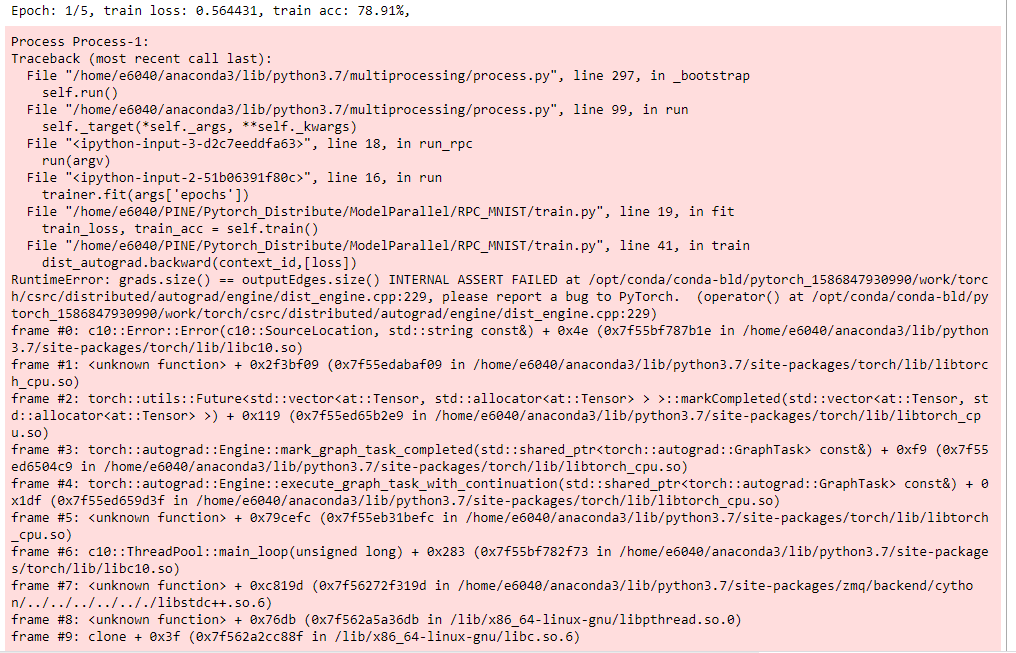
I tested the RPC framework with two nodes for a model parallelism implementation. The distributed Autograd and Optimizer can work successfully as the way I constructed them following the template in the RPC tutorial https://pytorch.org/tutorials/intermediate/rpc_tutorial.html. However, I do see the memory problem in the GPU and the memory usage grows with the number of epochs. I wonder if you could let me know what could be the problem.
I constructed a very simple CNN for the classification of the FashionMNIST dataset. Then I divided it into two submodels, one for convolutional layers and the other for fully-connected layers as below:
class ConvNet(nn.Module):
def __init__(self, device):
super().__init__()
self.device = device
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5).to(self.device)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5).to(self.device)
def forward(self, rref):
t = rref.to_here().to(self.device)
# conv 1
t = self.conv1(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
# conv 2
t = self.conv2(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2)
return t.cpu()
class FCNet(nn.Module):
def __init__(self,device):
super().__init__()
self.device = device
self.fc1 = nn.Linear(in_features=12*4*4, out_features=120).to(self.device)
self.fc2 = nn.Linear(in_features=120, out_features=60).to(self.device)
self.out = nn.Linear(in_features=60, out_features=10).to(self.device)
def forward(self, rref):
t = rref.to_here().to(self.device)
# fc1
t = t.reshape(-1, 12*4*4)
t = self.fc1(t)
t = F.relu(t)
# fc2
t = self.fc2(t)
t = F.relu(t)
# output
t = self.out(t)
# don't need softmax here since we'll use cross-entropy as activation.
return t.cpu()
To wrap them up, I created another CNNModel class for the purpose and perform the forward pass:
class CNNModel(nn.Module):
def __init__(self, connet_wk, fcnet_wk, device):
super(CNNModel, self).__init__()
# setup embedding table remotely
self.device = device
self.convnet_rref = rpc.remote(connet_wk, ConvNet,args=(device,))
# setup LSTM locally
print(self.convnet_rref.to_here())
self.fcnet_rref = rpc.remote(fcnet_wk, FCNet,args=(device,))
print(self.fcnet_rref.to_here())
print('CNN model constructed: ' + 'owner')
def forward(self, inputreff):
convnet_forward_rref = rpc.remote(self.convnet_rref.owner(), _call_method, args=(ConvNet.forward, self.convnet_rref, inputreff))
fcnet_forward_rref = rpc.remote(self.fcnet_rref.owner(), _call_method, args=(FCNet.forward, self.fcnet_rref, convnet_forward_rref))
return fcnet_forward_rref
def parameter_rrefs(self):
remote_params = []
remote_params.extend(_remote_method(_parameter_rrefs, self.convnet_rref))
remote_params.extend(_remote_method(_parameter_rrefs, self.fcnet_rref))
return remote_params
For training, I have a trainer to do that using Distributed Autograd and Optimiser:
class Trainer(object):
def __init__(self, model, optimizer, train_loader, test_loader, device):
self.model = model
self.optimizer = optimizer
self.train_loader = train_loader
self.test_loader = test_loader
self.device = device
def fit(self, epochs):
for epoch in range(1, epochs + 1):
train_loss, train_acc = self.train()
test_loss, test_acc = self.evaluate()
print(
'Epoch: {}/{},'.format(epoch, epochs),
'train loss: {}, train acc: {},'.format(train_loss, train_acc),
'test loss: {}, test acc: {}.'.format(test_loss, test_acc),
)
def train(self):
train_loss = Average()
train_acc = Accuracy()
for data, target in self.train_loader:
with dist_autograd.context() as context_id:
data_ref = RRef(data)
output_ref = self.model(data_ref)
output = output_ref.to_here()
loss = F.cross_entropy(output, target)
dist_autograd.backward([loss])
self.optimizer.step()
train_loss.update(loss.item(), data.size(0))
train_acc.update(output, target)
return train_loss, train_acc
def evaluate(self):
self.model.eval()
test_loss = Average()
test_acc = Accuracy()
with torch.no_grad():
for data, target in self.test_loader:
with dist_autograd.context() as context_id:
data_ref = RRef(data)
output_ref = self.model(data_ref)
output = output_ref.to_here()
loss = F.cross_entropy(output, target)
test_loss.update(loss.item(), data.size(0))
test_acc.update(output, target)
return test_loss, test_acc
At the top level, I created a CNNModel, initialized the RPC framework and passed the Distributed Optimizer to the trainer:
**#Worker 0**
def run(args):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
model = CNNModel(args['host'], args['worker'],device)
# setup distributed optimizer
opt = DistributedOptimizer(
optim.Adam,
model.parameter_rrefs(),
lr=args['lr'],
)
train_loader = MNISTDataLoader(args['root'], args['batch_size'], train=True)
test_loader = MNISTDataLoader(args['root'], args['batch_size'], train=False)
trainer = Trainer(model, opt, train_loader, test_loader, device)
trainer.fit(args['epochs'])
def main():
argv = {'world_size': int(2),
'rank': int(0),
'host': "worker0",
'worker': "worker1",
'epochs': int(10),
'lr': float(1e-3),
'root': 'data',
'batch_size': int(32)
}
print(argv)
rpc.init_rpc(argv['host'], rank=argv['rank'], world_size=argv['world_size'])
print('Start Run', argv['rank'])
run(argv)
rpc.shutdown()
os.environ['MASTER_ADDR'] = '10.142.0.13'#Google Cloud
#os.environ['MASTER_ADDR'] = 'localhost' #local
os.environ['MASTER_PORT'] = '29505'
main()
**#Worker 1**
def main():
argv = {'world_size': int(2),
'rank': int(1),
'host': 'worker0',
'worker': 'worker1',
'epochs': int(10),
'lr': float(1e-3),
'root': 'data',
'batch_size': int(32)
}
print(argv)
rpc.init_rpc(argv['worker'], rank=argv['rank'], world_size=argv['world_size'])
print('Start Run', argv['rank'])
rpc.shutdown()
os.environ['MASTER_ADDR'] = '10.142.0.13'#Google Cloud
#os.environ['MASTER_ADDR'] = 'localhost' #local
os.environ['MASTER_PORT'] = '29505'
main()
The dataloader is as the following:
from torch.utils import data
from torchvision import datasets, transforms
class MNISTDataLoader(data.DataLoader):
def __init__(self, root, batch_size, train=True):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
])
dataset = datasets.FashionMNIST(root, train=train, transform=transform, download=True)
super(MNISTDataLoader, self).__init__(
dataset,
batch_size=batch_size,
shuffle=train,
)
I showed all the details above but I guess the problem could be the way I constructed the CNNModel for the ConvNet and FCNet. I wonder if you could take a look at the code and give some hints on where could be the problems?
Thank you very much for your time!
Best,
Ziyi