Is it generally good practice to make weights linearly related to the number of related label pixels? ie. If you have 10 of class 1, 10 of class 2, and 20 of class 3, your weights would be [1,1,2]? I am facing a segmentation problem where there are many orders of magnitude difference between the each class and not sure what loss function/weights to handle this with.
2 Likes
Usually you increase the weight for minority classes, so that their loss also increases and forces the model to learn these samples. This could be done by e.g. the inverse class count (class frequency).
5 Likes
Hi @ptrblck,
I am looking into using multiple ignore_indices for loss computations. ignore_index argument expects an integer so I cannot use that.
Will it be equivalent to making the loss per pixel (for example) 0 for all those indices after the loss computation?
You could try to zero out the losses at all indices which should be ignored.
Would setting all these indices to a specific index value work as an alternative?
If so, you could still use the ignore_index argument and wouldn’t have to implement a manual approach.
Is there a paper on the use of weights to handle class imbalance? Can someone post a link to a reference?
I got crossentropyloss working without weights on a dataset with 98.8% unlabeled 1.1% labeled data and got relatively good results, so I assumed adding weights to the training would improve results. When I added weights the results were totally messed up, though. I made the weights inversely proportional to the label frequencies as well. ie. weights: [0.01172171 0.98827829].
Here is a gif showing: input labels, output of my crossentropyloss training without weights, output of my crossentropyloss training with weights (in that order)
Any ideas?
Kyle
How did you use nn.CrossEntropyLoss for unlabeled data? Did you skip the training samples without a target? Also, how should the weight counter this behavior?
Sorry my wording was confusing, by unlabelled I meant label 0, labeled meaning label 1. I hope this makes sense.
Thanks for the clarification.
How “good” were the original results, i.e. did you create the confusion matrix and checked the per-class accuracy or did you visually inspect the outputs?
I would assume that a prediction, which overfits on the majority class, might look quite good as these would cover 98% of all pixels.
Is your training and validation loss decreasing “properly” for the weighted use case or do you see that the model gets stuck?
This gif showing input labels, label results of training with no weights, then label results of training with weights was my visual inspection of the [0,1] label segmentations.
Here are results from my [0,1] label training with no weights- the one I considered ‘good’:
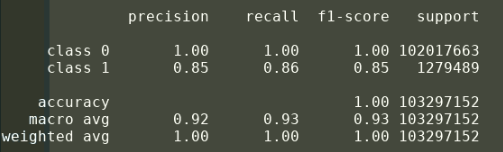
And here are results from my [0,1] label training with weights inversely proportional to label frequency:
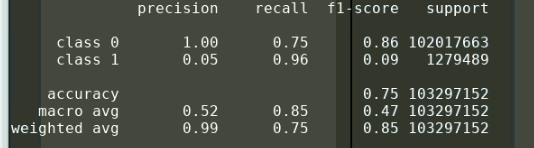
This can be seen in the last frames of the gif where the label 1(green) is far overrepresented. You asked about loss for this training example. I checked, and it appears validation loss got to about 0.13 in the second epoch and never got better from there (training ended in 4th epoch at 0.15)
I also recently did a training example on a non binarized version of my data with no weights (labels [0,1…,8]) which had these results:
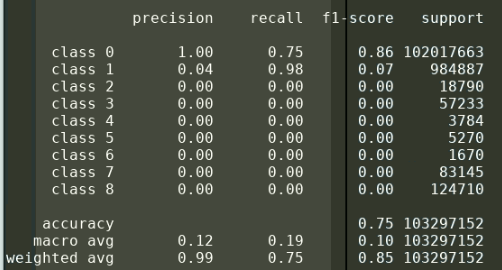
Here the largest label was underrepresented and smaller structures went unrecognized. My ultimate goal is to have the multi-label segmentation work, I was just using a simplified version where labels [1,2,…8] were all set to 1 for testing purposes.
It may be of note that my ‘successful’ training ran for 6 epochs whereas the other two only went for 4. Not sure if this may be ‘convergence’ related.
Hello!
The link provided leads to a general documentation page, not a concrete passage.
The current documentation of the NLLLoss still generates a vague understanding of how the weights for classes are perceived.
For instance, as per text on this docspage, NLLLoss — PyTorch 2.1 documentation
the function is calculated from input with |C| rows whose values are purportedly softmax probabilities for each of the |C| classes. It is natural to suppose that the i_th element of the weights vector passed to
loss would match the values i_th column of input. But the torch NN modules do not explicitly indicate which final layer units (i.e. which columns of input to the loss) are related to which classes.
So which principle does torch utilise to map the weights onto classes in an arbitrary problem setup?
In my case, the weights are [0, 1] and after some trials it is now self-evident to me that the first element in weights pertains to class 0 and the second element pertains to class 1. But that’s probably the most simple case with the least ambiguity.
The reply of @done1892 in this post
gives an example for the classification problem with classes [0…4] and the author of the current post considered an example of classification with classes [0…10].
But here, the classes do not contain negative values and they are well ordered.
In a more general situation (e.g. with classes [-11, 0, 4]) would torch assign the weights to classes in an ascending manner, i.e. w1 to ‘’-11", w2 to “0”, w3 to “4”?
Thanks in advance for your response.
Thank you @ptrblck!
How can we ensure the mapping between labels and weights? e.g. if I have two classes (0 and 1) with class frequencies of 70% (class 0) and 30% (class 1), what should I choose between:
weights = torch.tensor([.7, .3])
and
weights = torch.tensor([.3, .7])
Thanks a lot in advance 
1 Like
The weights are using the same class index, i.e. the loss is using weight[class_index_of_sample] to calculate the weighted loss. In your first example class0 would get a weight of 0.7 while class1 would use 0.3.
In case your question was targeting the use case of “balancing” the loss given an imbalanced dataset, you should use the higher weight for the minority class, so the second approach.
2 Likes
Thanks @ptrblck for your reply!
Yes, I would like to weight more the minority class, so [0.3, 0.7] would be the correct weighting.
But the question was more…
how can I be sure that the first weight value (0.3) gets assigned to class 0 and not to class 1?
Are the label values sorted in increasing order somewhere in the pipeline? Because maybe I have 6 samples with labels [1,0,0,0,1,0] and in this case the first label value would be 1.
thank you very much again
1 Like
The order of weights corresponds to the class index values as described here:
For a target of [1, 0, 0, 0, 1, 0] the weights would then be indexed as [0.7, 0.3, 0.3, 0.3, 0.7, 0.3].
1 Like
Ok, thank you very much for clarifying!
Question about the above, but in the case of soft targets (the target for each sample is a distribution over all C classes, not just a single class index):
I notice from the documentation for nn.CrossEntropyLoss that the noted normalization for the full batch is NOT performed in the case of the soft target version of this loss.
(I was drawn to this forum because I am getting results very heavily weighted towards the minority class when I use the same class weights for the soft target version and one-hot vectors for the targets, where it works as expected with hard targets, and I think I have it tracked down to the lack of normalization in the case of soft targets - batches that contain the minority class have much higher weights when backward is performed, i.e. there is effectively a much larger step taken, whereas with normalization for the batch in place, it is the direction of the step, but not its magnitude, that is impacted by the class weights.)
Note that performing the normalization seems straightforward for the case of soft targets - the normalization becomes the sum of [class weight] * [target probability] for each sample, rather than just [class weight of target class] for each sample.
Can you confirm that not performing normalization for the batch in the case of the ‘soft target’ version of nn.CrossEntropyLoss is a limitation and that my reasoning above is correct?
Thanks!
Hi @ptrblck !
Sorry for coming back to this, but it’s still not 100% clear to me:
Are the label values somewhere sorted in increasing order by nn.CrossEntropyLoss? Because for instance I now have a classification problem with 3 classes (values 1,2,3) for which I would like the corresponding weights
class_weights = [0.3, 0.2, 0.5]
class_weights = torch.Tensor(class_weights).to(device) # convert to tensor
loss = torch.nn.CrossEntropyLoss(weight=class_weights) # define loss function
this would work though I never specified a mapping, so how can I be sure that weight 0.3 will be assigned to class 1, 0.2 to class 2, and 0.5 to class 3?
Indeed, as @ivan-bilan initially said, wouldn’t it be easier to just have a dictionary as class_weight so that we are sure of the mapping?
Thank you very much in advance!
The class indices are used for the weights in the same way they are used for the logits, i.e. model outputs.
output[:, 0] corresponds to the logits for class0 for all samples. The same applies to weights[0], which corresponds to the class0 weight. There is no need to specify a mapping or dictionary as you are already assuming the order in the model output.