Thank you, again.
Not following how the argmax relates CrossEntropyLoss. Please elaborate.
You are correct, somehow the “mean” nullifies the weight bias.
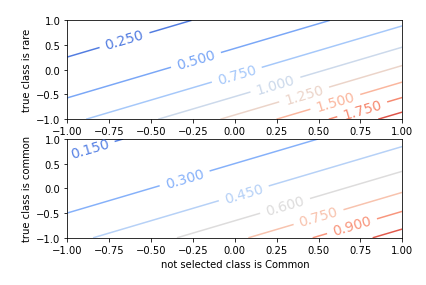
Experiment 1 shows an error on any logit when classes are balanced results in the same loss.
Experiment 2 shows if the rare class is the true class, the losses are amplified when any error occurs.
Experiment 1:
- balanced 2 classes,
- batch of 2 samples,
- introduce a single logit error and observe loss for true class = 0, 0 and 1, 1
loss = torch.nn.CrossEntropyLoss(weight=torch.tensor([1.,1.]),reduction=‘sum’)
print(“2 balanced class, reduction=sum”)
true_class_index = torch.tensor([0,0]) # so perfect prediction is [1,-1], [1,-1]
incorrect_sample_0_class_0 = loss(torch.tensor([[-1., -1],[1.,-1]]), true_class_index)
incorrect_sample_0_class_1 = loss(torch.tensor([[1., 1],[1.,-1]]), true_class_index)
incorrect_sample_1_class_0 = loss(torch.tensor([[1., -1],[-1.,-1]]), true_class_index)
incorrect_sample_1_class_1 = loss(torch.tensor([[1., -1],[1.,1]]), true_class_index)
print(f"all have one logit wrong {incorrect_sample_0_class_0:0.2f}, {incorrect_sample_0_class_1:0.2f}, {incorrect_sample_1_class_0:0.2f}, {incorrect_sample_1_class_1:0.2f}")
- all have one logit wrong 0.82, 0.82, 0.82, 0.82
true_class_index = torch.tensor([1,1]) # so perfect prediction is [1,-1], [1,-1]
incorrect_sample_0_class_0 = loss(torch.tensor([[1., 1],[-1.,1]]), true_class_index)
incorrect_sample_0_class_1 = loss(torch.tensor([[-1., -1],[-1.,1]]), true_class_index)
incorrect_sample_1_class_0 = loss(torch.tensor([[-1., 1],[1.,1]]), true_class_index)
incorrect_sample_1_class_1 = loss(torch.tensor([[-1., 1],[-1.,-1]]), true_class_index)
print(f"all have one logit wrong {incorrect_sample_0_class_0:0.2f}, {incorrect_sample_0_class_1:0.2f}, {incorrect_sample_1_class_0:0.2f}, {incorrect_sample_1_class_1:0.2f}")
- all have one logit wrong 0.82, 0.82, 0.82, 0.82
Experiment 2:
- unbalanced 2 classes,
- batch of 2 samples,
- introduce a single logit error and observe loss for true class = 0, 0 and 1, 1
loss = torch.nn.CrossEntropyLoss(weight=torch.tensor([10000.,1.]),reduction=‘sum’)
print(“2 unbalanced class, reduction=sum”)
true_class_index = torch.tensor([0,0]) # so perfect prediction is [1,-1], [1,-1]
incorrect_sample_0_class_0 = loss(torch.tensor([[-1., -1],[1.,-1]]), true_class_index)
incorrect_sample_0_class_1 = loss(torch.tensor([[1., 1],[1.,-1]]), true_class_index)
incorrect_sample_1_class_0 = loss(torch.tensor([[1., -1],[-1.,-1]]), true_class_index)
incorrect_sample_1_class_1 = loss(torch.tensor([[1., -1],[1.,1]]), true_class_index)
print(f"all have one logit wrong {incorrect_sample_0_class_0:0.2f}, {incorrect_sample_0_class_1:0.2f}, {incorrect_sample_1_class_0:0.2f}, {incorrect_sample_1_class_1:0.2f}")
> - all have one logit wrong 8200.75, 8200.75, 8200.75, 8200.75
true_class_index = torch.tensor([1,1]) # so perfect prediction is [1,-1], [1,-1]
incorrect_sample_0_class_0 = loss(torch.tensor([[1., 1],[-1.,1]]), true_class_index)
incorrect_sample_0_class_1 = loss(torch.tensor([[-1., -1],[-1.,1]]), true_class_index)
incorrect_sample_1_class_0 = loss(torch.tensor([[-1., 1],[1.,1]]), true_class_index)
incorrect_sample_1_class_1 = loss(torch.tensor([[-1., 1],[-1.,-1]]), true_class_index)
print(f"all have one logit wrong {incorrect_sample_0_class_0:0.2f}, {incorrect_sample_0_class_1:0.2f}, {incorrect_sample_1_class_0:0.2f}, {incorrect_sample_1_class_1:0.2f}")
- all have one logit wrong 0.82, 0.82, 0.82, 0.82
btw, is there a way to post code snippets and not loose indentation on this site?