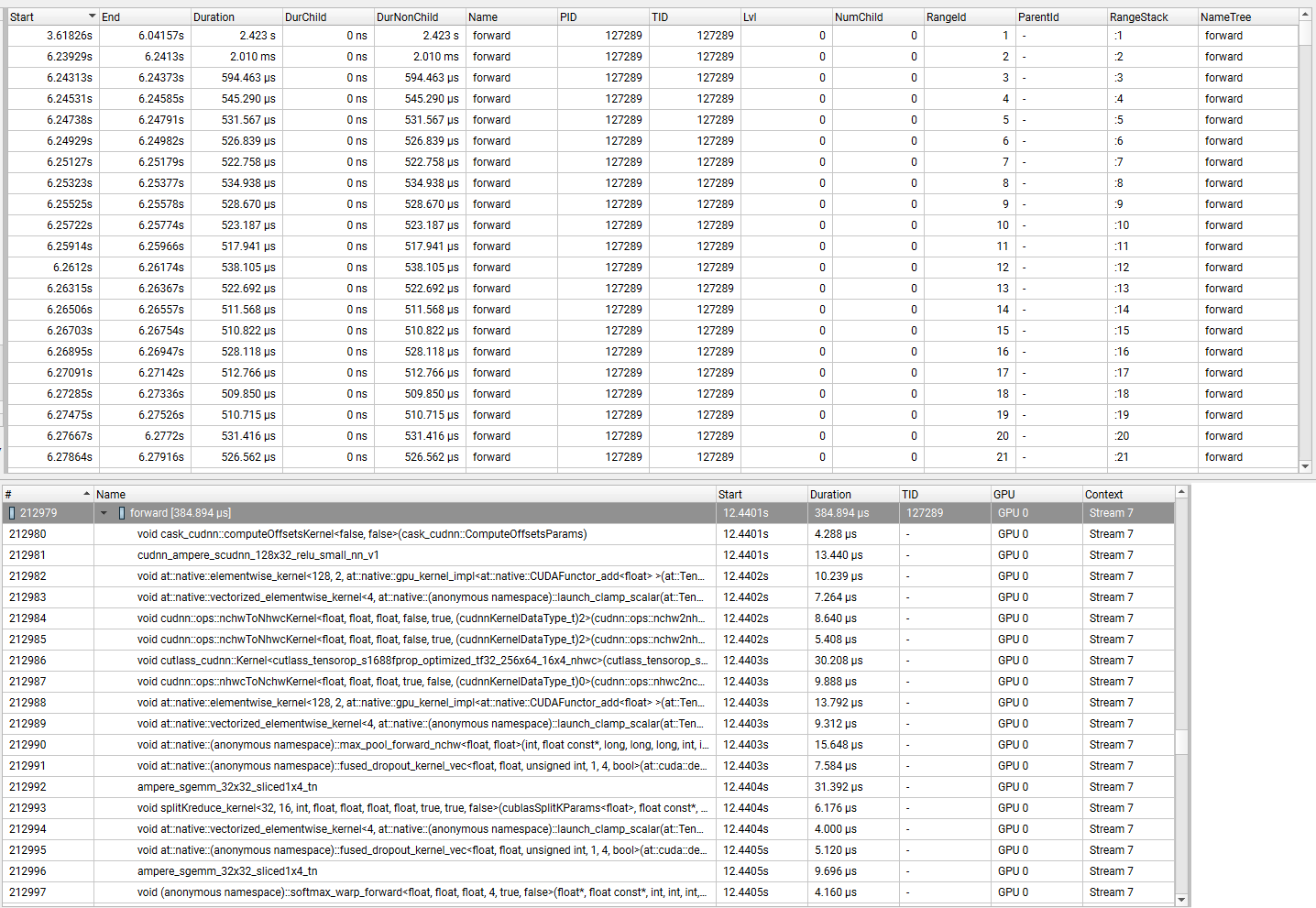
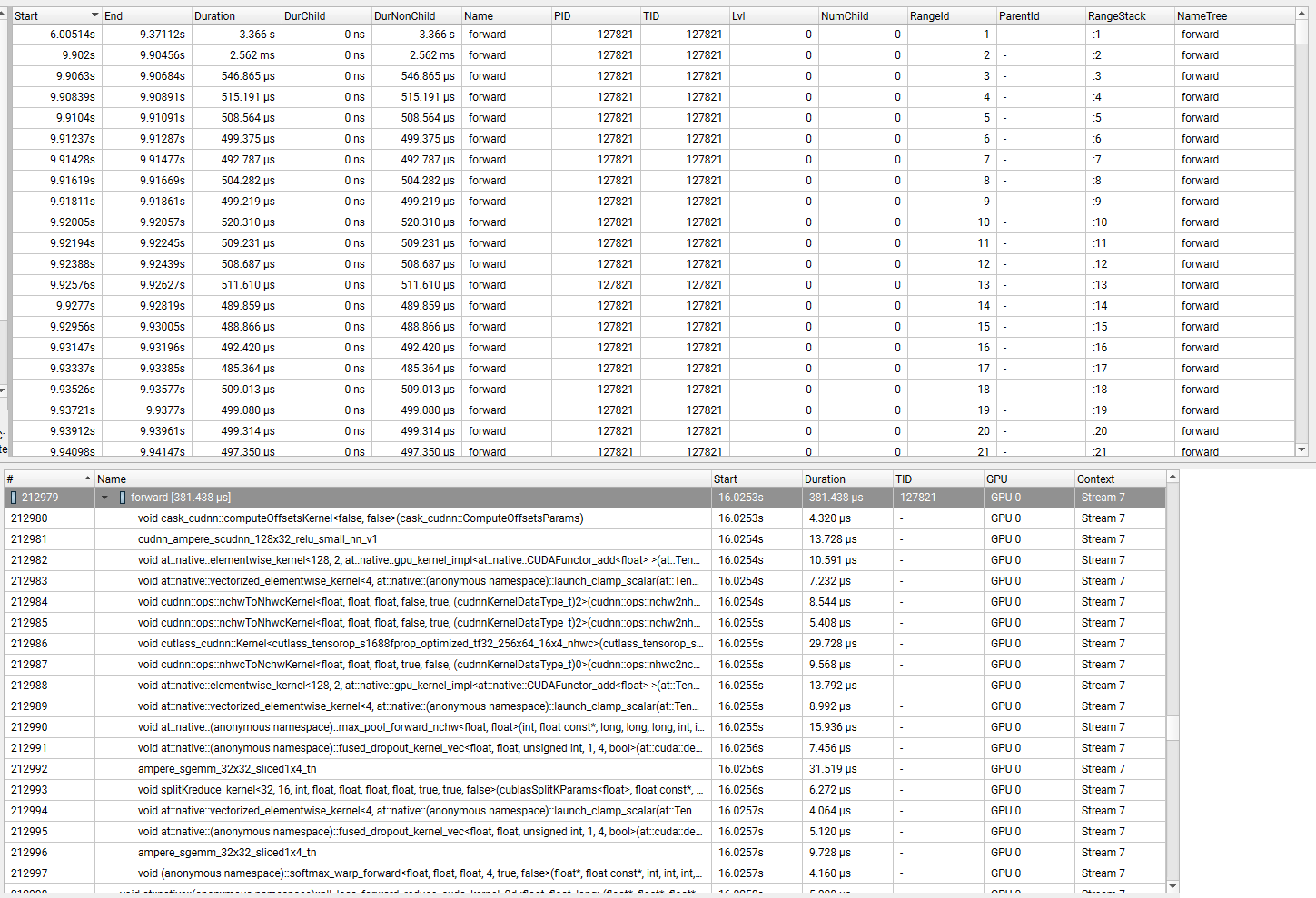
I found that the pytorch I compiled myself has a performance difference with the pytorch obtained by conda install: using the mnist example on A100, the forward time increased by 5%.
What commit did you build from source with and were you able to verify that e.g., all library versions (cuDNN, cuBLAS, etc.) were the same between your source build and the upstream wheels?
Would you also be able to share how you are benchmarking MNIST?
The specific commit is c263bd4 (the v2.0.0 tag). The torch.__version__ returns 2.0.0a0+gitc263bd4.
I could confirm that the cuDNN is the same (cuDNN v8.5.0, installed according to the script in pytorch/builder, both returns 8500 for torch.backends.cudnn.version()). The other CUDA libraries (e.g., cuBlas) should be shipped with CUDA 11.7.0. NCCL is installed automatically by setup.py when setting USE_STATIC_NCCL=1 in my case while it may be not relevant.
Interesting, does profiling with e.g., nsys nvprof show the same kernels for both the source build vs. the prebuilt binaries? If so then we can basically rule out differences due to math libraries.
Another interesting thing is the cold start overhead between the compiled and the installed differs from each other greatly and could be stably reproduced. Therefore, I believe there should be some differences between them.
Are the differences present only on cold-start and with just a single layer? I’m curious if it could be caused by e.g., lazy module loading: CUDA C++ Programming Guide which was introduced in 11.7.
Thanks for the explanation. I suppose I am not using lazy loading since I only upgrade CUDA to 11.7, without a R515+ driver.
Leaving the cold start difference back, my primary concern is that are there any differences (e.g., compiling args) between building PyTorch from source with wheels (e.g., from conda)? I believe that if I understand the scripts in pytorch/builder right, the scripts and envs above should exactly match the building procedure, thus producing the same artifact (not including version). Or if there is something I have already missed?