Hello everyone,
I am pretty sure this question has been asked hundreds of times. However, I failed to find an answer to my problem.
Context: I’ve trained the ResNet18 model on 2 classes. In training 2700/3100 images per class, on validation: 680/770. The model trained well, I ended up with the accuracy of around 99% and loss around 0.01 - 0.02. Fine tuning, pretrained.
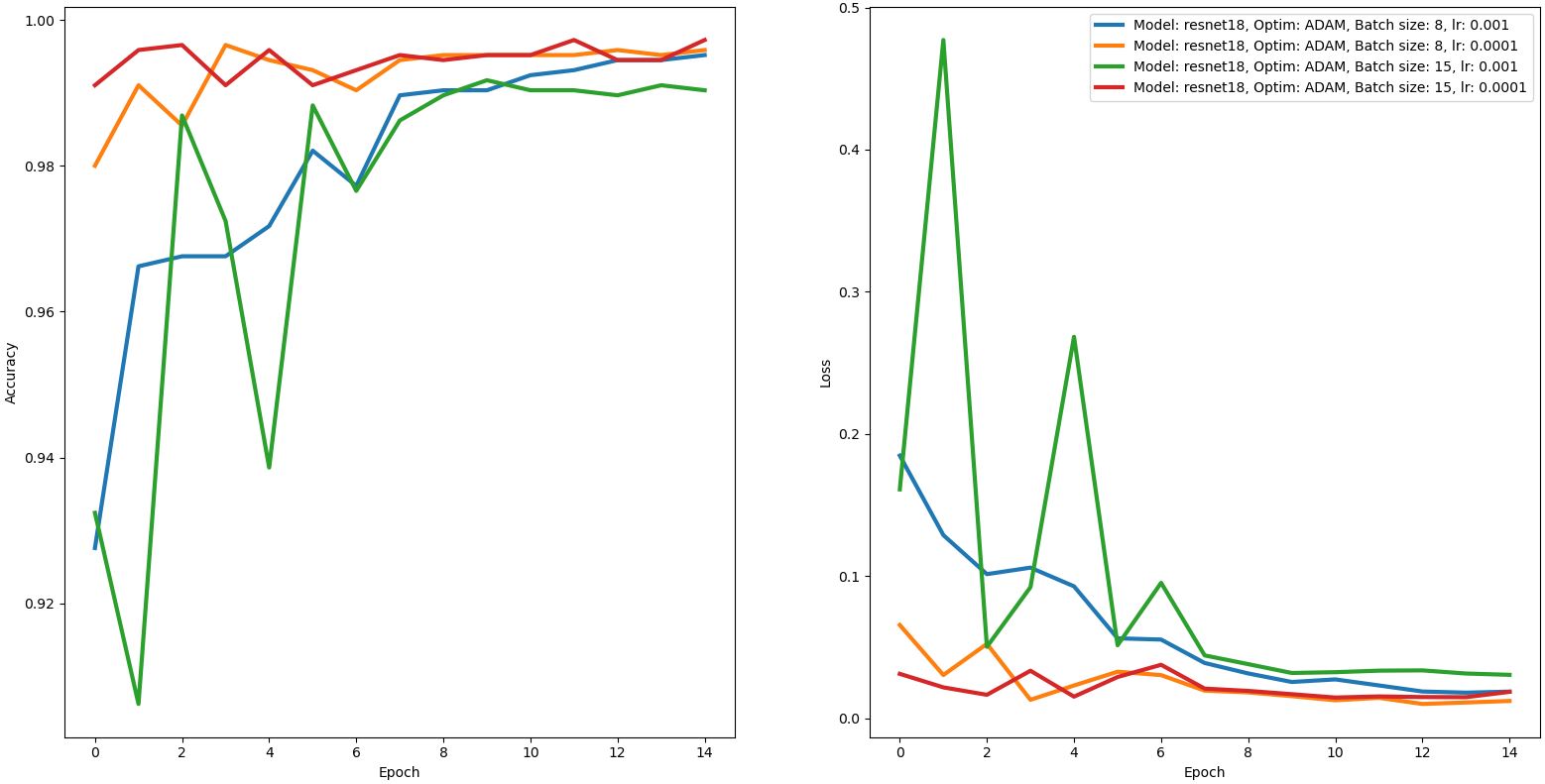
However, when we integrated the model in our system we quickly noticed it is half not as good as on validation data even though the data we’ve been feeding to the model is pretty much the same. I am 99% sure the problem is in preprocessing, however I am unable to find where I made a mistake. I’ve been staring in the code for too long, if anyone could have a quick glance please. Probably you could spot what I did wrong.
On step 1, we read N frames of a video (or just 1 photo) and load it to GPU. No preprocessing done. Just original images:
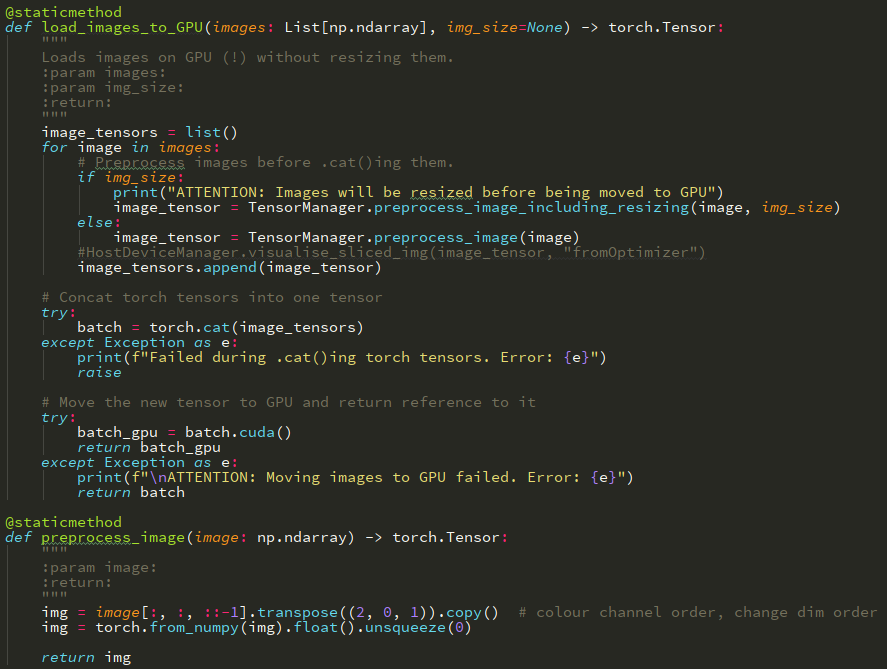
Then we have the YOLO net that finds objects for us. Using the coordinates of detected objects, we slice torch tensors on GPU and accumulate them in a list and send to our classification ResNet model. The model will need to do all necessary preprocessing because uploaded to GPU images underwent none.
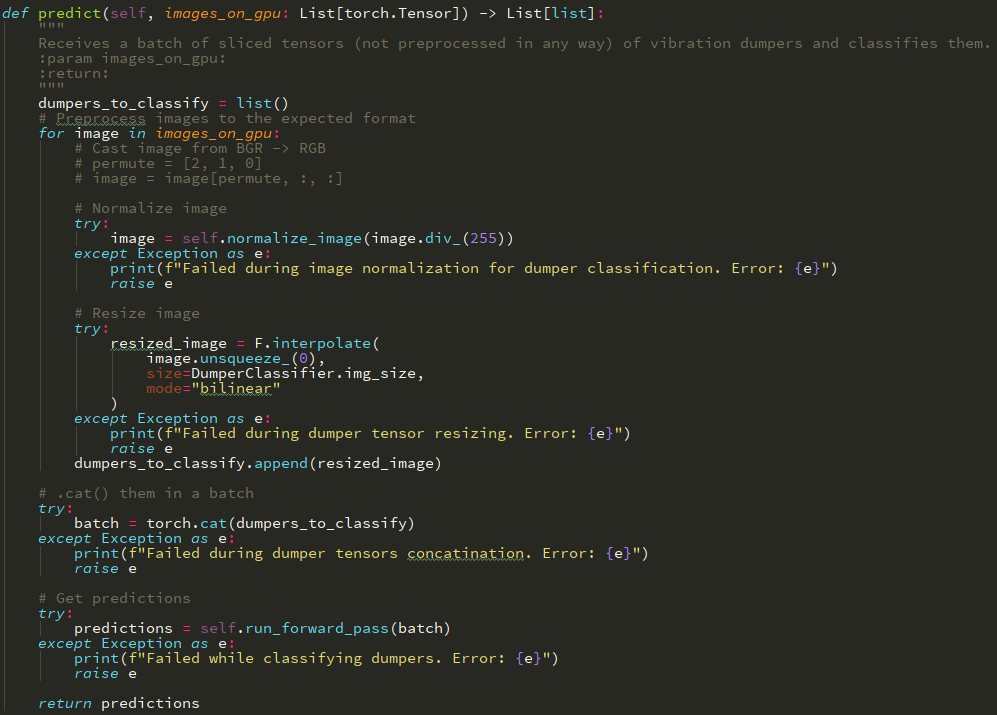
The normalization function:

I do understand that I must have failed to follow the preprocessing I used during training. Which is here:
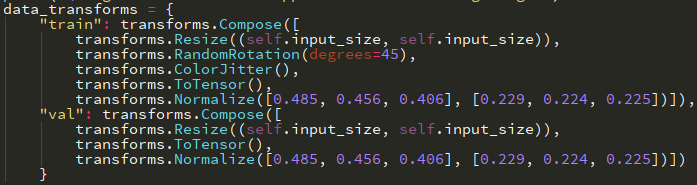
If anyone could please have a look and let me know what I did wrong because I cannot find the problem.
I’ve studied what happens with validation images under the hood in Resize(), ToTensor() and Normalize() steps. What I’m doing seems to be identical, however I am getting much more errors than on validation data, which is very very similar to what the model’s been dealing with after integration.
Thank you very much in advance.
Regards,
Eugene
