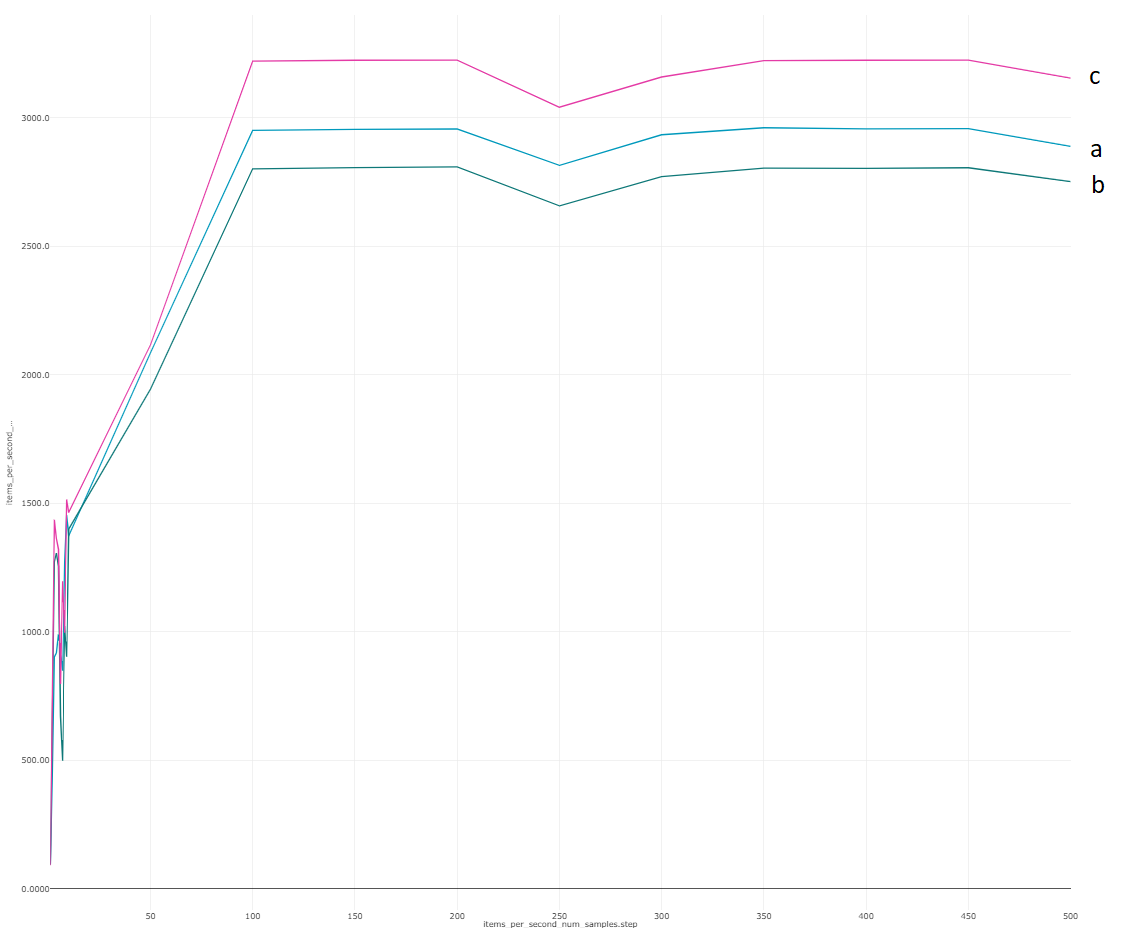
I want to know why the following three cases give different performance (trianing speed).
a. module with bfloat16 parameter
b. module with bfloat16 parameter + autocast(dtype=torch.bfloat16)
c. module with float32 parameter + autocast(dtype=torch.bfloat16)
Here is the performance (training speed) for each case
I am using A100 with torch 1.12, cuda 11.6. In both “a” and “b”, I convert the model parameters to bfloat16 by calling module.to(torch.bfloat16).
It is very strange that there is a large difference betweena “a” and “c”. I think the datatypes for computation (inside autocast block) are the same.
I don’t know what b would be doing as autocast expects to use float32 inputs and parameters. If you are manually calling bfloat16() on both then I would assume that autocast would be a no-op.
In any case, profile the code and check which operations are responsible for the difference in the times.
If autocast is mainly for float32, I think the result makes sense to me. Thanks for the reply.
autocast will use the float32 inputs and parameters and will cast them to the desired dtype in the forward/backward for safe operations.
While this could explain why a and b are close (b might add a small overhead even if it’s a no-op), it would not explain why c is the fastest mode, as it would perform the actual transformations.