Is there a way to specify the GPU to use when using a DataLoader with pin_memory = True?
I’ve tried using
torch.cuda.set_device(device)
and
with torch.cuda.device(gpu_id):
#DataLoader
but nvidia-smi shows that the GPU used is always the first available.
I think I could use:
CUDA_VISIBLE_DEVICES=x
to make the target GPU be the only one available in the notebook but I’d rather not.
1 Like
afaik, pinned memory is not specific to any GPU. It just puts data in the locked page in host CPU memory. The destination is specified by .cuda(device)
1 Like
I thought that too but I’ve noticed that when I pin it, some stuff get loaded on the GPU according to nvidia-smi.
I’ve tried changing the device before pinning it as in:
import torch
x_tensor = torch.FloatTensor(1)
with torch.cuda.device(2):
x_tensor.pin_memory()
and I got this:
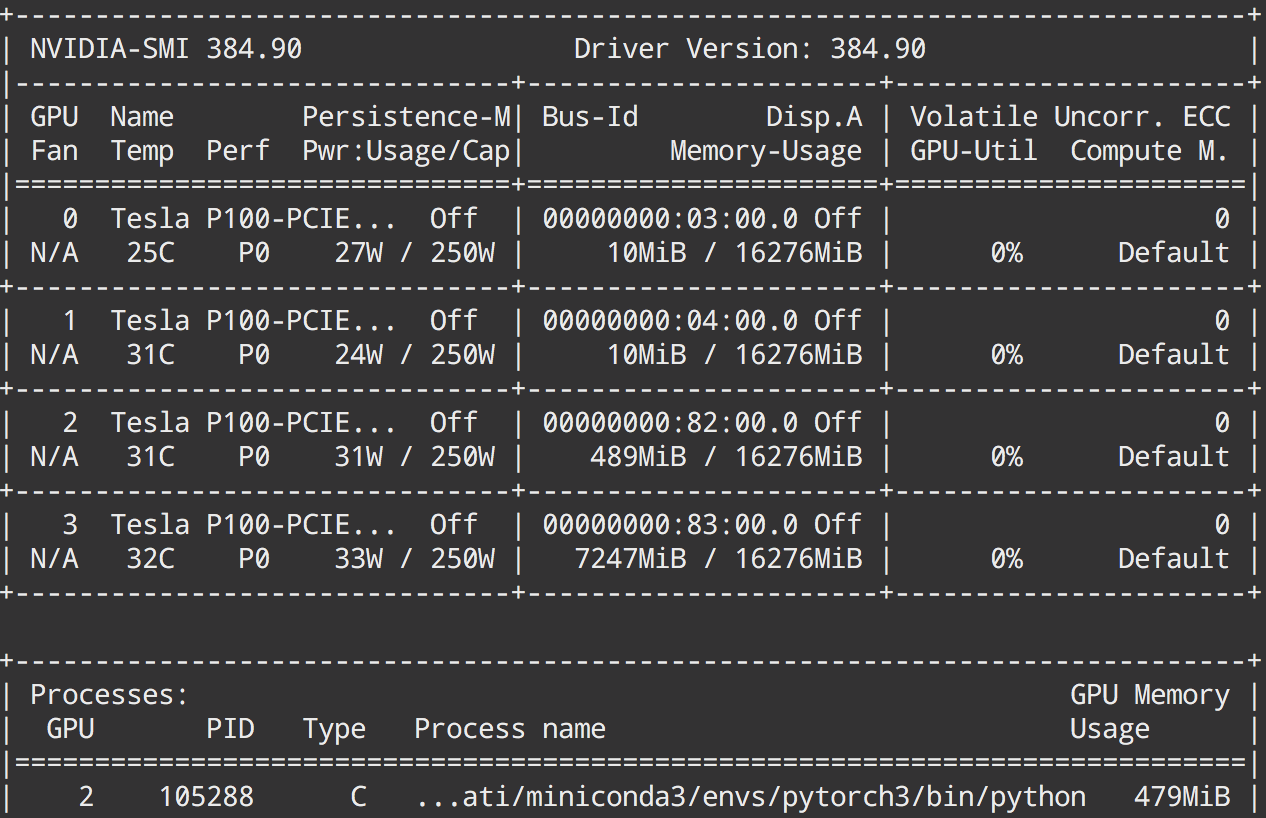
I don’t know the inner working of pinning memory but this led me to believe some preparations take place on the GPU as well (setting the device before starting a DataLoader doesn’t seem to affect it).
If I set the .cuda(device) on model/inputs they get sent to the correct GPU but that memory usage from pinning persists until I finish so I decided to ask on here for some opinions
I played with different sized tensors, the allocated memory is always constant. It is very likely that some context is created when you do so. So don’t worry too much about it.
What pytorch version are you using? Pinning to specific GPU was merged recently https://github.com/pytorch/pytorch/pull/4196, before that context was always initialized on device 0.
It is not such a small deal, on an 8 GPU system 7 unnecessary contexts can be created, each taking ~ 400 MB, together taking ~ 3 GB of memory.
1 Like
You are right @ngimel , my problem was that from conda I got the latest release 0.3.0 but the docs I was reading were already about version 0.4.0 
This commit should fix my problem:
I am having the same issue with torch-1.10.2+cu113, is this fixed?
Yes, the initialization of the CUDA context on the default device when pinned memory is used, was fixed in late 2017.