Hi, i’m a student and currently working on pipelining models on edge devices.
My current setup is: 1 Master linux machine, 2 Jetson Nano as workers.
I used the example on:
https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html
But the difference is I trained the DenseNet(small) model with CIFAR10 dataset.
I split the model as follows:
class Shard1(nn.Module):
def __init__(self, *args, **kwargs):
super(Shard1, self).__init__()
block = Bottleneck
nblocks = [6,12,24,16]
growth_rate = 12
reduction = 0.5
num_classes = 10
self.growth_rate = growth_rate
self._lock = threading.Lock()
self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(f"Using device: {torch.cuda.get_device_name(self.device)}")
num_planes = 2*growth_rate
self.conv1 = nn.Conv2d(3, num_planes, kernel_size=3, padding=1, bias=False).to(self.device)
self.dense1 = self._make_dense_layers(block, num_planes, nblocks[0]).to(self.device)
num_planes += nblocks[0]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans1 = Transition(num_planes, out_planes).to(self.device)
num_planes = out_planes
self.dense2 = self._make_dense_layers(block, num_planes, nblocks[1]).to(self.device)
num_planes += nblocks[1]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans2 = Transition(num_planes, out_planes).to(self.device)
def _make_dense_layers(self, block, in_planes, nblock):
layers = []
for i in range(nblock):
layers.append(block(in_planes, self.growth_rate))
in_planes += self.growth_rate
return nn.Sequential(*layers)
def forward(self, x_rref):
x = x_rref.to_here().to(self.device)
with self._lock:
out = self.conv1(x)
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
return out.cpu()
def parameter_rrefs(self):
r"""
Create one RRef for each parameter in the given local module, and return a
list of RRefs.
"""
return [RRef(p) for p in self.parameters()]
class Shard2(nn.Module):
def __init__(self, *args, **kwargs):
super(Shard2, self).__init__()
block = Bottleneck
nblocks = [6,12,24,16]
growth_rate = 12
reduction = 0.5
num_classes = 10
self.growth_rate = growth_rate
self._lock = threading.Lock()
self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(f"Using device: {torch.cuda.get_device_name(self.device)}")
num_planes = 8*growth_rate
self.dense3 = self._make_dense_layers(block, num_planes, nblocks[2]).to(self.device)
num_planes += nblocks[2]*growth_rate
out_planes = int(math.floor(num_planes*reduction))
self.trans3 = Transition(num_planes, out_planes).to(self.device)
num_planes = out_planes
self.dense4 = self._make_dense_layers(block, num_planes, nblocks[3]).to(self.device)
num_planes += nblocks[3]*growth_rate
self.bn = nn.BatchNorm2d(num_planes).to(self.device)
self.linear = nn.Linear(num_planes, num_classes).to(self.device)
def _make_dense_layers(self, block, in_planes, nblock):
layers = []
for i in range(nblock):
layers.append(block(in_planes, self.growth_rate))
in_planes += self.growth_rate
return nn.Sequential(*layers)
def forward(self, x_rref):
x = x_rref.to_here().to(self.device)
with self._lock:
out = self.trans3(self.dense3(x))
out = self.dense4(out)
out = F.avg_pool2d(F.relu(self.bn(out)), 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out.cpu()
def parameter_rrefs(self):
r"""
Create one RRef for each parameter in the given local module, and return a
list of RRefs.
"""
return [RRef(p) for p in self.parameters()]
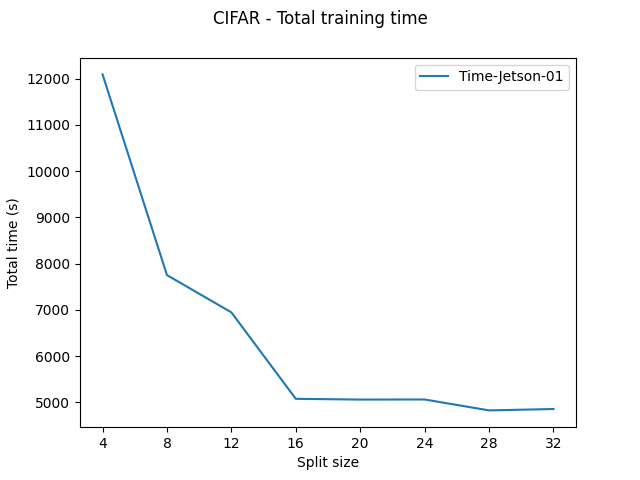
I also trying to investigate the impact of split size (for parallel execution) on the performance.
Here is the plot of average GPU usage (recorded with tegrastats) on 2 Jetson devices:
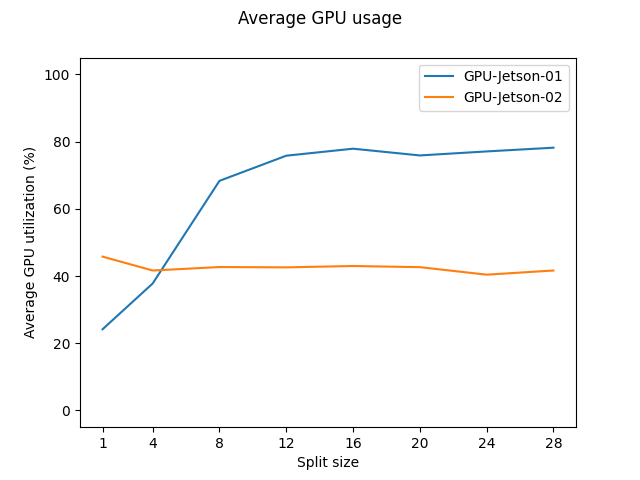
In Pipeline Parallelism — PyTorch 2.1 documentation, ideally, the smaller the split size, the higher the number of microbatches, thus should increase the GPU utilization. However, the figure above tell the opposite. Even for the 2nd Jetson Nano, the result is unexpected. So i suspect that there are definitely some kind of a bottleneck. One possible cause is the network bandwidth and another one is the CPU when we keep changing tensor’s device.
How can I address these problems?
Thank you very much.