@vdw,
Thank you for putting in the time to create those examples. Unfortunately, the use of the “embedded” layer has made things even more confusing for me. I truly am lost, and each additional example I see, including that one adds even more confusion.
I feel that part of the problem is that my questions are too general to be understood. This is my fault. Therefore, I’m making a final attempt: Below is some code from my attempt to work alongside this tutorial.
I have taken a page from your book and added lots of print statements for various layers outputs. Below the outputs I have listed specific questions that I have.
class flightLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.hidden = None
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
print(f'input original shape: {x.shape}')
# format input to shape (batch_size, seq_len, input_size)
x = x.view(1, len(x), 1)
print(f'input reshaped for LSTM: {x.shape} \n')
out, self.hidden = self.lstm(x, self.hidden)
print(f'output shape from LSTM layer: {out.shape}')
print(f'output = \n {out}')
print()
# flatten output to (batch_size, hidden_size)
out = out.view(-1, self.hidden_size)
print(f'out reshaped for FC layer: {out.shape} \n')
out = self.fc(out)
print(f'Fully connected output shape: {out.shape}')
print(f'output = \n {out}')
return out
input_size = 1
hidden_size = 3
num_layers = 1
output_size = 1
model = flightLSTM(input_size, hidden_size, num_layers, output_size)
# loads a Pandas dataframe
data = sns.load_dataset("flights")
data.passengers = data.passengers.astype(np.float32)
# reserve the last 12 months as test data.
train_data = data.passengers[:-12].to_numpy()
test_data = data.passengers[-12:].to_numpy()
# scale and convert training data to tensor
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_train_data = scaler.fit_transform(train_data.reshape(-1, 1))
scaled_train_data = torch.tensor(scaled_train_data, dtype=torch.float32)
# get target data from known sequence
def get_targets(data, window):
sequences = []
L = len(data)
for i in range(L - window):
sequence = data[i:i + window]
label = data[i + window: i + window + 1]
sequences.append((sequence, label))
return sequences
seq_len = 12
seq_data = get_targets(scaled_train_data, 12)
Okay, here are the results of a forward pass through the network:
model(seq_data[0][0])
>>>
input original shape: torch.Size([12, 1])
input reshaped for LSTM: torch.Size([1, 12, 1])
output shape from LSTM layer: torch.Size([1, 12, 3])
output =
tensor([[[ 0.1085, 0.0436, -0.0182],
[ 0.1245, 0.0547, -0.0299],
[ 0.1277, 0.0552, -0.0445],
[ 0.1289, 0.0555, -0.0494],
[ 0.1298, 0.0570, -0.0462],
[ 0.1298, 0.0550, -0.0541],
[ 0.1292, 0.0518, -0.0669],
[ 0.1295, 0.0504, -0.0733],
[ 0.1304, 0.0520, -0.0682],
[ 0.1311, 0.0558, -0.0542],
[ 0.1313, 0.0602, -0.0369],
[ 0.1306, 0.0595, -0.0377]]], grad_fn=<TransposeBackward0>)
out reshaped for FC layer: torch.Size([12, 3])
Fully connected output shape: torch.Size([12, 1])
output =
tensor([[0.2949],
[0.2927],
[0.2865],
[0.2844],
[0.2862],
[0.2822],
[0.2758],
[0.2726],
[0.2753],
[0.2824],
[0.2911],
[0.2906]], grad_fn=<AddmmBackward>)
Okay, so my questions about this specific code:
- I’m providing one sequence of 12 data points. That means my batch size is one, correct?
- If I wanted to provide the network two sequences at a time, I’d need to shape my input to (2, 12, 1). Does this mean a batch is defined as a set of column vectors, where each sequence is a column?
- If I wanted to have a batches with two sequences, each one containing two variables per point in time, I’d have to change my shape to (2, 12, 2). Is that correct?
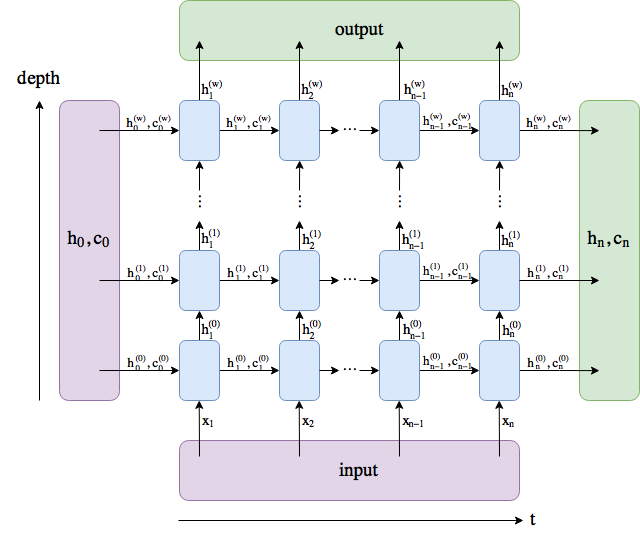
- Going back to the data output from the forward pass above. The LSTM layer outputs a tensor of size (1, 12, 3). It’s basically a tensor containing 3 columns. What does each column represent? What does each element of a given column represent?
- I need to “flatten” the output tensor before I can feed it to my fully connected layer. Have I done so correctly?
- The output of the fully connected layer is essentially a column vector. I specified that my output be of size 1, but I got back 12. I think this means that each element of my 12 point sequence gets run through the layers individually. That makes me think that each element of this output is simply the predicted “next step” for that point in the sequence, but I don’t know. What does each element of this column vector mean?
-
If I am correct about #6, why does the author of this code only have a singleton label for each 12 point sequence? See the function “get_targets”.