OK, so you’re doing basic time series analysis. In this case, input_size=1, of course.
Before replying to your specific questions, just some general comments:
- Try not to think too much of row or column vectors. Once you have tensors with more than 2 dimensions (i.e., a matrix), the notions of rows, columns, etc. get quickly confusing. Think about of dimensions and their order.
- Network layers only throw an error if the shape of the input is not correct. However, just because the input shape is correct, doesn’t mean that the input itself is correct. Please have a look at a previous post of mine where I outline some pitfalls of
view()andreshape(). For example, the linex = x.view(1, len(x), 1)should be fine since you only have 1 sequence in your batch andinput_size=1.
- I’m providing one sequence of 12 data points. That means my batch size is one, correct?
Yes! It’s only a bit unintuitive why the shape of the original x is (12, 1), since the batch size usually comes first. But I assume that’s just the result of your get_targets() method.
- If I wanted to provide the network two sequences at a time, I’d need to shape my input to (2, 12, 1). Does this mean a batch is defined as a set of column vectors, where each sequence is a column?
Yes! This needs to be the resulting shape. But again, be careful how you get to this shape without messing up your batch tensor; see link above.
- If I wanted to have a batches with two sequences, each one containing two variables per point in time, I’d have to change my shape to (2, 12, 2). Is that correct?
Yes! (same comment as above). I would only change the phrasing a bit: the batch contains 2 sequences, each sequence contains 12 data points, and each data point has 2 features (or, is represented by a 2-dim (feature) vector). The term “variable” does fit here.
- Going back to the data output from the forward pass above. The LSTM layer outputs a tensor of size (1, 12, 3). It’s basically a tensor containing 3 columns. What does each column represent? What does each element of a given column represent?
Don’t think for rows or columns. The output of an LSTM gives you the hidden states for each data point in a sequence, for all sequences in a batch. You only have 1 sequence, it comes with 12 data points, each data point has 3 features (since this is the size of the LSTM layer). Maybe this image helps a bit:
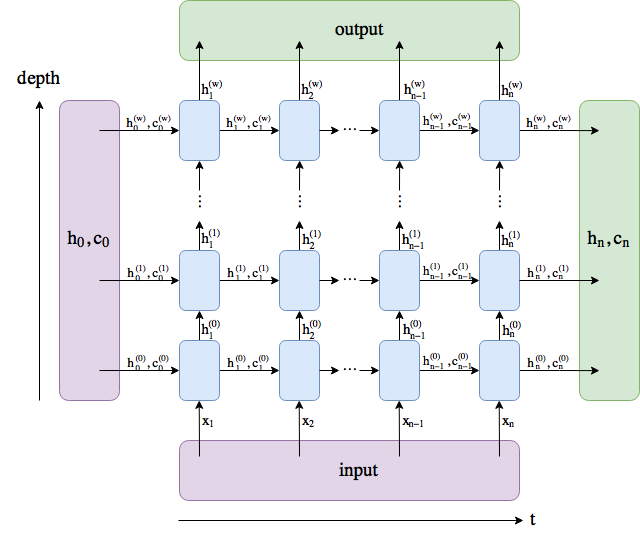
In your case, you have h_1 to h_12 since you have 12 data points, and each h_i is a vector with 3 features.
- I need to “flatten” the output tensor before I can feed it to my fully connected layer. Have I done so correctly?
No! The linear layer expects an input shape of (batch_size, "something"). Since your batch size is 1, out after flattening need to be of shape (1, "something"), but you have (12, "something"). Note that self.fc doesn’t care, it just sees a batch of size 12 and does process it. In your simple case, a quick fix would be out = out.view(1, -1)
- The output of the fully connected layer is essentially a column vector. I specified that my output be of size 1, but I got back 12. I think this means that each element of my 12 point sequence gets run through the layers individually. That makes me think that each element of this output is simply the predicted “next step” for that point in the sequence, but I don’t know. What does each element of this column vector mean?
Once you fixed the flattening, self.fc will return an output of size 1. Through the incorrect flattening to created a batch of size 12.
- If I am correct about #6, why does the author of this code only have a singleton label for each 12 point sequence? See the function “get_targets”.
Same issue: you’re flattening is off.