Please, I need help to run my model and I am stuck!
I try here to train a Siamese BERT model, using a particular dataset (that I transformed in dataloader..)
But I got this error (the GPU is : ‘Tesla P100-PCIE-16GB’)
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_34/2427691835.py in
11 optim.zero_grad()
12 # prepare batches and more all to the active device
—> 13 inputs_ids_a = batch[‘code_file1_input_ids’].to(device)
14 inputs_ids_b = batch[‘code_file2_input_ids’].to(device)
15 attention_a = batch[‘code_file1_attention_mask’].to(device)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
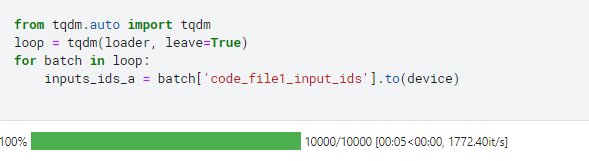
from tqdm.auto import tqdm
for epoch in range(4):
model.train() # make sure model is in training mode
# initialize the dataloader loop with tqdm (tqdm == progress bar)
loop = tqdm(loader, leave=True)
for batch in loop:
# zero all gradients on each new step
optim.zero_grad()
# prepare batches and more all to the active device
inputs_ids_a = batch['code_file1_input_ids'].to(device)
inputs_ids_b = batch['code_file2_input_ids'].to(device)
attention_a = batch['code_file1_attention_mask'].to(device)
attention_b = batch['code_file2_attention_mask'].to(device)
label = batch['similar_or_different'].to(device)
# extract token embeddings from BERT
u = model(inputs_ids_a, attention_mask=attention_a)[0] # all token embeddings A
v = model(inputs_ids_b, attention_mask=attention_b)[0] # all token embeddings B
.........
..............
# process concatenated tensor through FFNN
x = ffnn(x)
# calculate the 'softmax-loss' between predicted and true label
loss = loss_func(x, label)
# using loss, calculate gradients and then optimize
loss.backward()
optim.step()
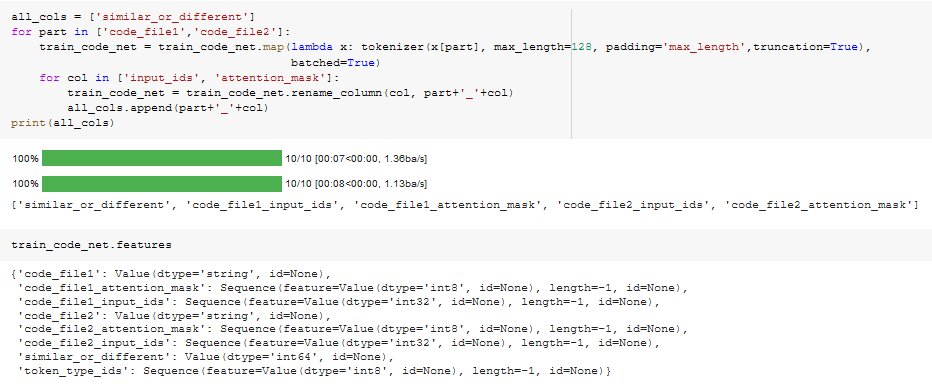
Knowing that: I reduced the batch_size to 1
And when I tried, just before this code, this one: It passes!!!
from tqdm.auto import tqdm
loop = tqdm(loader, leave=True)
for batch in loop:
inputs_ids_a = batch['code_file1_input_ids'].to(device)
Here the output (I couldn’t add the other screenshot becaue i was told new users can’t integrate two images… )