Hi all,
I am training my network with the policy gradient approach. My rewards are either -1 or 1, and I calculate the loss and update the parameters just like in here. However, the loss increases and goes to zero and the average reward in each epoch quickly converges to -1. I attached the loss and reward plots. My optimizer is SGD, and I tried ADAM and also played around with the learning rate, but no success. Does anyone have any ideas?
Thanks.
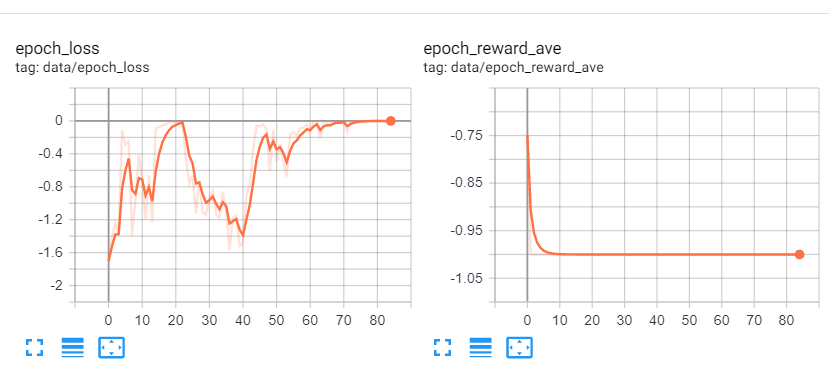
Edit: at the output I have a softmax layer with 11 outputs (actions) and it seems that after training, the model “learns” to output 0 for all actions but one. Then, the log probability of that action will be 0 and that is why the loss is zero. This is very bizarre to me because I expect the loss to decrease and not increase.