I am providing a reproducible problem to compare poor convergence of PyTorch model compared to Tensorflow for Adam optimizer with learning rate = 0.001, beta (0.9, 0.999), and elipson=1e-8.
The model is:
convLayer = nn.Conv1d(in_channel=24, out_channel=128, kernel_size=15,stride=1,padding=7)
convLayerGate = nn.Conv1d(in_channel=24, out_channel=128, kernel_size=15,stride=1,padding=7)
GLU = convLayer * Torch.sigmoid(convLayerGate)
Input to both PyTorch and Tensorflow (for comparison and reproducibility):
np.random.seed(0)
input = np.random.randn(1, 24, 128)
output = np.random.randn(1, 128, 128)
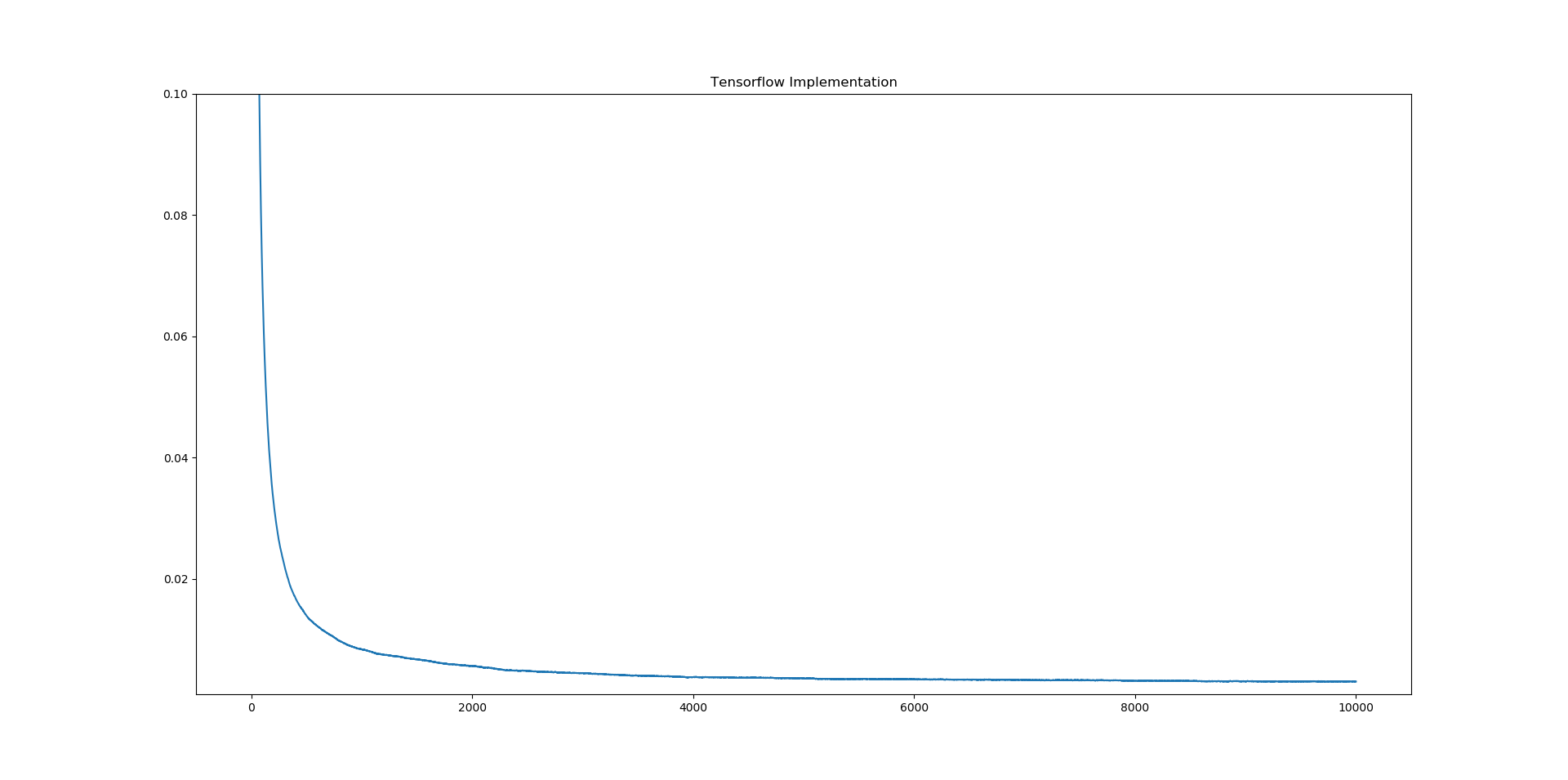
Loss in Tensorflow:
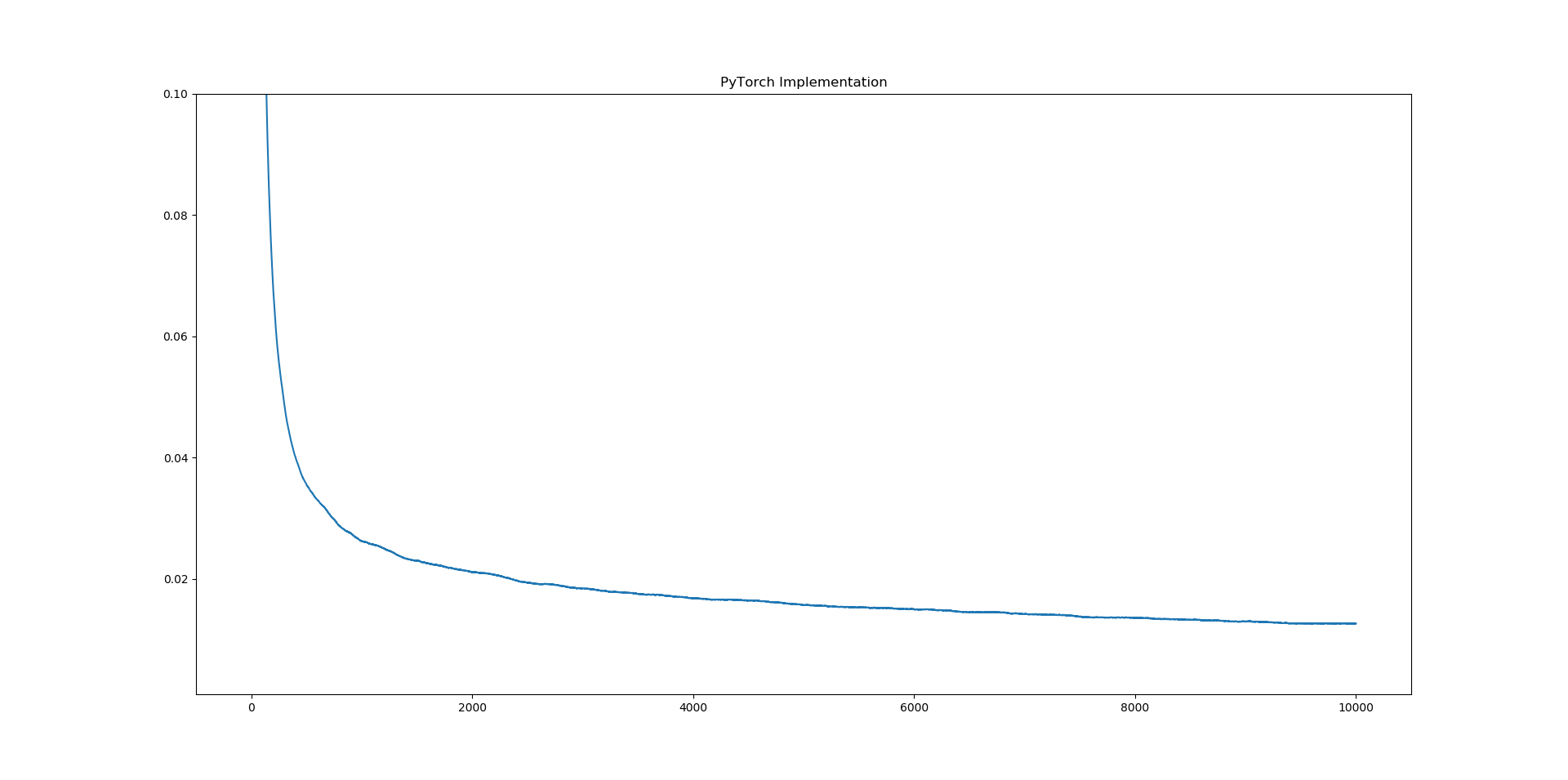
Loss in PyTorch
Tensorflow converges Loss to → 0.0030888948
If one implements the model in Tensorflow one can spot the difference.
3 Likes
SimonW
December 6, 2018, 8:06am
2
Did you make sure that you initialized the layers identically in pytorch and tf?
I used the default initialization for both PyTorch and Tensorflow. Even if the initialization scheme is not same, it seems unreasonable that Tensorflow converges to a loss which is 4 times better than what PyTorch converges to for such a simple model.
SimonW
December 6, 2018, 9:08am
4
Initialization matters a lot… please try with same initial value.
1 Like
SimonW
December 6, 2018, 9:08am
5
Initialization matters a lot… please try with same initial value.
To level the playing fields between both Tensorflow and PyTorch:
Both are now using “Glorot Uniform” Initializer.
Bias is turned off for both the models.
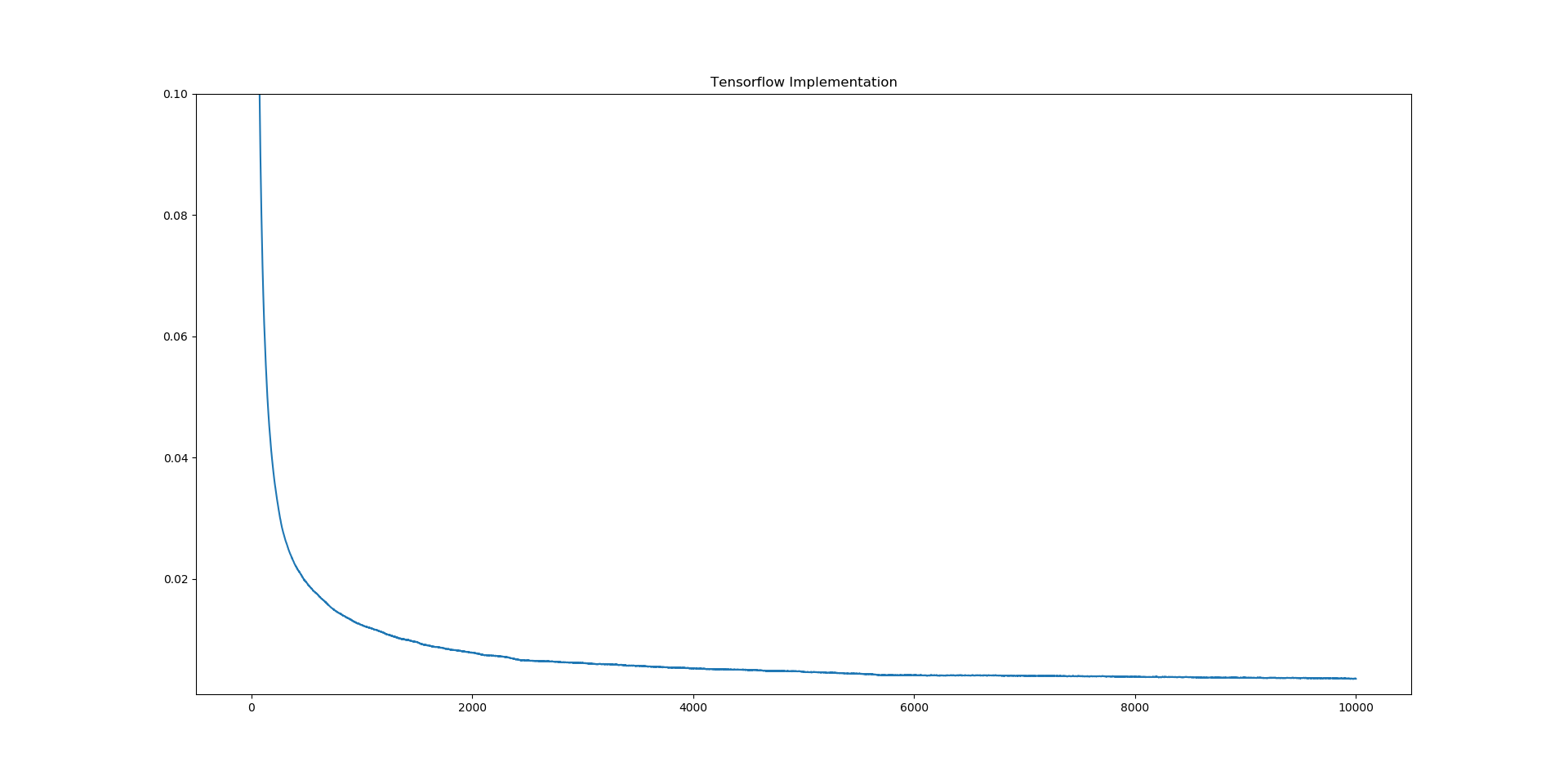
New Tensorlfow model loss function:
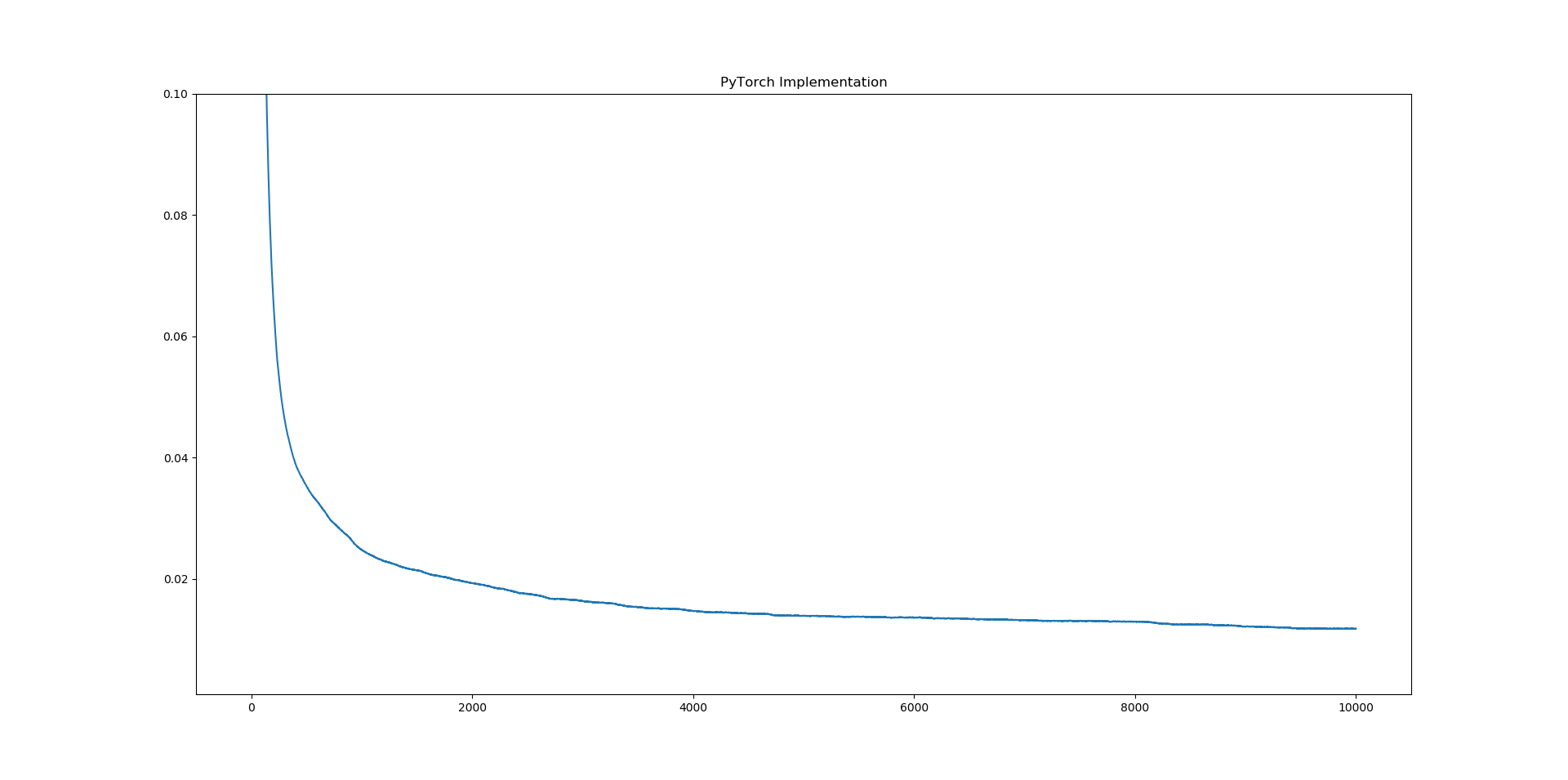
New PyTorch model loss function:
Tensorflow minimum loss: 0.00354829
6 Likes
RyanS
June 22, 2020, 12:40pm
7
Has any further progress been made on this issue as of yet? I am struggling with a problem very similar in nature to this.