I’m in the process to train a small language model. I’m stuck in the data preparation step where I have seen how It’s a basic practice to wrap the example with special tokens (SOS, EOS).
I’d appreciate the logic behind this practice - also how it would affect the model performance If we don’t wrap the data with special tokens.
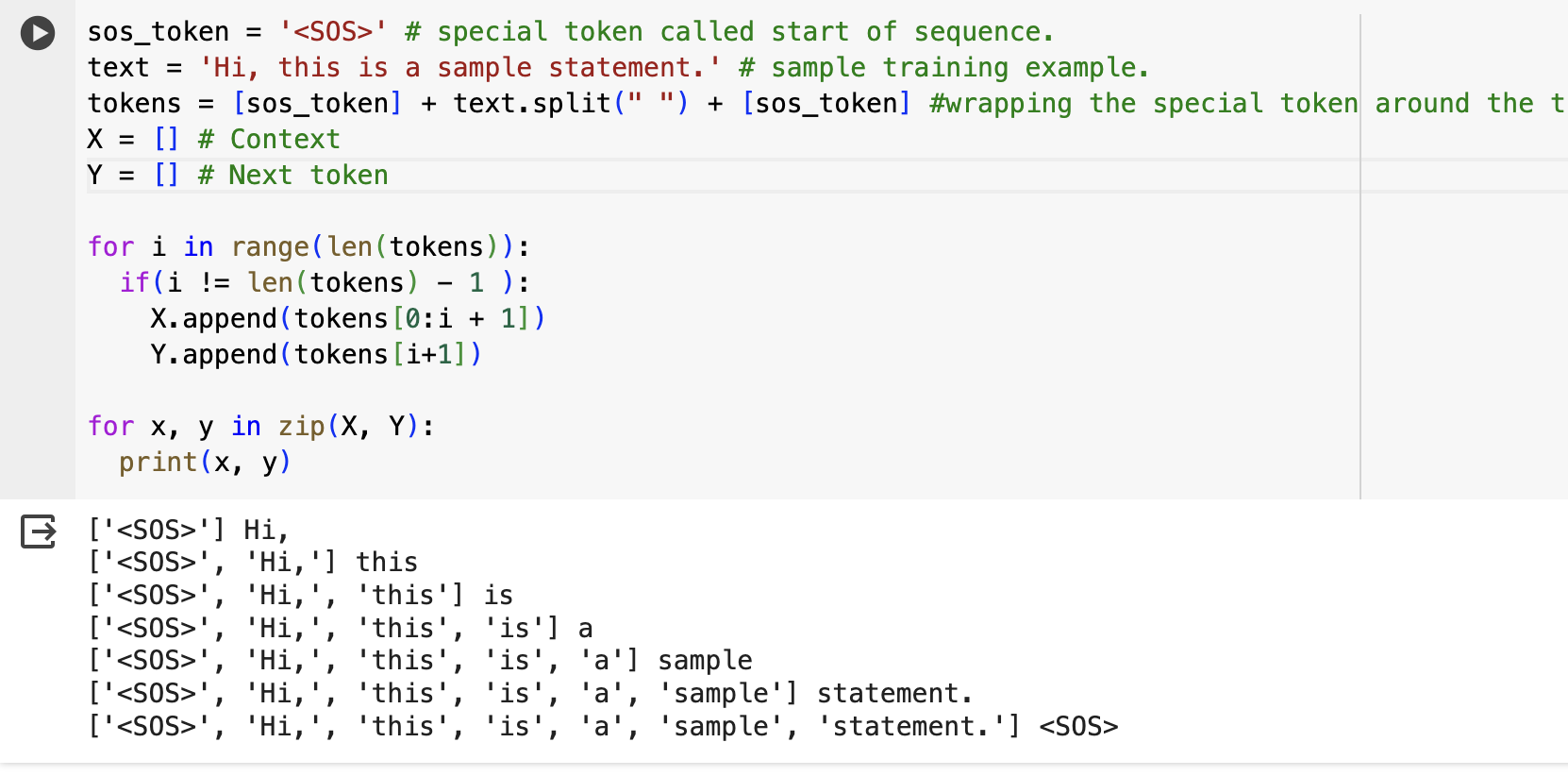
I’m attaching a sample data just to showcase my understanding for ref which I wrapped with the SOS token & tried to generate X (input) & Y (output) tensors.
Looking forward to hearing from the community ![]()
Cheers!