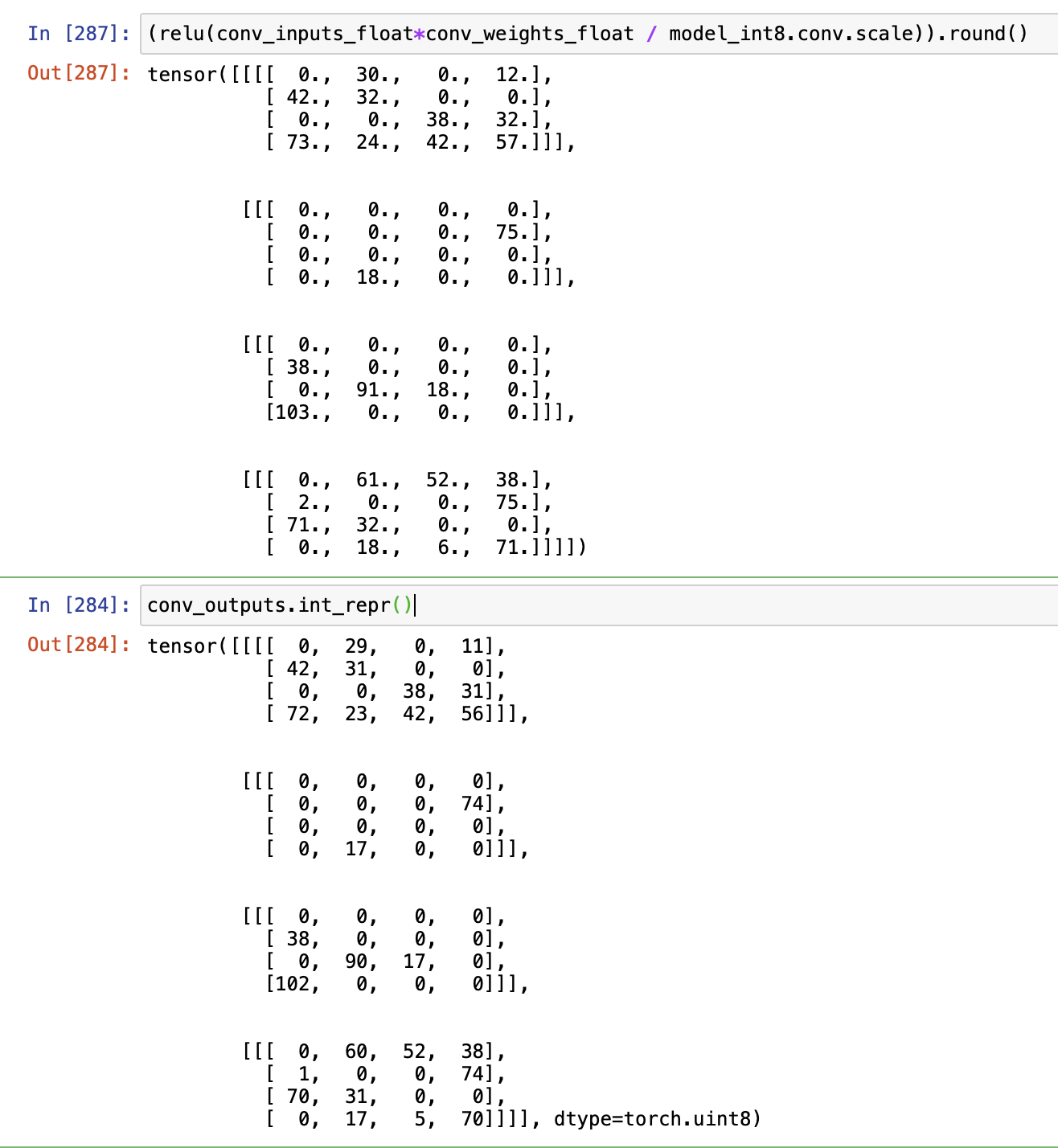
I’ve attached the code and output I used to find out that they actually use the dequantized float values for computation during forward pass.
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
# manually specify where tensors will be converted from floating
# point to quantized in the quantized model
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# manually specify where tensors will be converted from quantized
# to floating point in the quantized model
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval mode for static quantization logic to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'fbgemm' for server inference and
# 'qnnpack' for mobile inference. Other quantization configurations such
# as selecting symmetric or assymetric quantization and MinMax or L2Norm
# calibration techniques can be specified here.
model_fp32.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# Prepare the model for static quantization. This inserts observers in
# the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.quantization.prepare(model_fp32_fused)
# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.quantization.convert(model_fp32_prepared)
# hooks to retrieve inputs, outputs and weights of conv layer (fused conv + relu)
conv_inputs = []
conv_weights = []
conv_outputs = []
hooks = []
for hook in hooks:
hook.remove()
def hook_fn(m, i, o):
global conv_inputs, conv_outputs, conv_weights
conv_inputs = i[0] # [0] because conv_inputs is a tuple and we only care about the first item
conv_weights = m.weight()
conv_outputs = o
hooks.append(model_int8.conv.register_forward_hook(hook_fn))
# run forward pass
res = model_int8(input_fp32)
relu = torch.nn.ReLU()
# Manually dequantize and manually compute output
# Note that convolution is just a simple multiplication because it's a 1x1 kernel with 1 channel
conv_float_input = (conv_inputs.int_repr().int() - conv_inputs.q_zero_point())*conv_inputs.q_scale()
conv_float_weight = conv_weights.int_repr() * conv_weights.q_per_channel_scales()
conv_float_output = conv_float_input * conv_float_weight + model_int8.conv.bias()
manual_output_1 = (relu(conv_float_output / model_int8.conv.scale)).round()
print("manual_output_1:\n", manual_output_1)
# Use built-in dequantize() and manually compute output
# Note that convolution is just a simple multiplication because it's a 1x1 kernel with 1 channel
conv_float_output = conv_inputs.dequantize()*conv_weights.dequantize() + model_int8.conv.bias()
manual_output_2 = relu((conv_float_output / model_int8.conv.scale).round())
print("manual_output_2:\n", manual_output_2)
# Output produced by forward() pass
print("output produced by forward():\n", conv_outputs.int_repr())
# print the difference between manual input and output generated by forward (0.0 means no difference)
print("manual_output_1 and conv_outputs differ by: ", end = "")
print((manual_output_1 - conv_outputs.int_repr()).sum().item())
print("manual_output_2 and conv_outputs differ by: ", end = "")
print((manual_output_2 - conv_outputs.int_repr()).sum().item())
Here’s the output (will differ every time because input is randomly generated):
manual_output_1:
tensor([[[[ 96., 0., 15., 15.],
[104., 0., 0., 64.],
[ 0., 0., 0., 31.],
[ 0., 0., 0., 0.]]],
[[[ 0., 58., 0., 0.],
[ 54., 0., 35., 23.],
[ 0., 0., 0., 17.],
[ 23., 8., 125., 83.]]],
[[[ 0., 125., 0., 77.],
[ 0., 69., 127., 4.],
[ 8., 0., 0., 0.],
[ 58., 0., 35., 0.]]],
[[[ 46., 15., 52., 0.],
[ 4., 27., 69., 29.],
[ 0., 56., 0., 2.],
[ 0., 54., 33., 21.]]]], dtype=torch.float64,
grad_fn=<RoundBackward0>)
manual_output_2:
tensor([[[[ 96., 0., 15., 15.],
[104., 0., 0., 64.],
[ 0., 0., 0., 31.],
[ 0., 0., 0., 0.]]],
[[[ 0., 58., 0., 0.],
[ 54., 0., 35., 23.],
[ 0., 0., 0., 17.],
[ 23., 8., 125., 83.]]],
[[[ 0., 125., 0., 77.],
[ 0., 69., 127., 4.],
[ 8., 0., 0., 0.],
[ 58., 0., 35., 0.]]],
[[[ 46., 15., 52., 0.],
[ 4., 27., 69., 29.],
[ 0., 56., 0., 2.],
[ 0., 54., 33., 21.]]]], grad_fn=<ReluBackward0>)
output produced by forward():
tensor([[[[ 96, 0, 15, 15],
[104, 0, 0, 64],
[ 0, 0, 0, 31],
[ 0, 0, 0, 0]]],
[[[ 0, 58, 0, 0],
[ 54, 0, 35, 23],
[ 0, 0, 0, 17],
[ 23, 8, 125, 83]]],
[[[ 0, 125, 0, 77],
[ 0, 69, 127, 4],
[ 8, 0, 0, 0],
[ 58, 0, 35, 0]]],
[[[ 46, 15, 52, 0],
[ 4, 27, 69, 29],
[ 0, 56, 0, 2],
[ 0, 54, 33, 21]]]], dtype=torch.uint8)
manual_output_1 and conv_outputs differ by: 0.0
manual_output_2 and conv_outputs differ by: 0.0