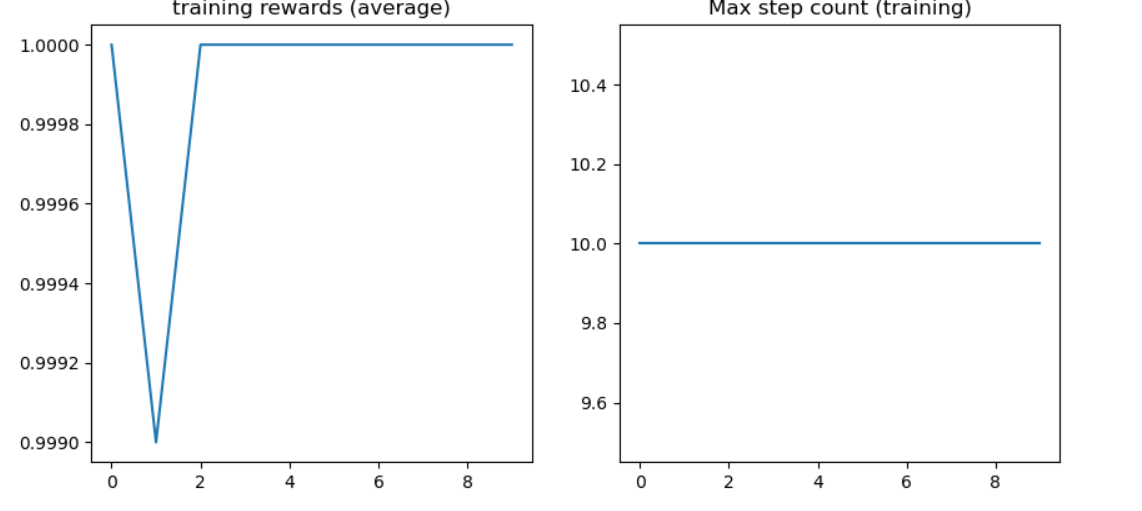
I followed the TorchRL getting started documentation and I am running into issue with not being able to learn the cartpole environment with PPO. The tutorial learns the double pendulum environment no problem, but when I change to cartpole and modify the probabilistic actor for a discrete output it does not learn. perhaps I am not making the proper modifications?