Hello, everyone.
I have a question on how to use prepare_qat properly.
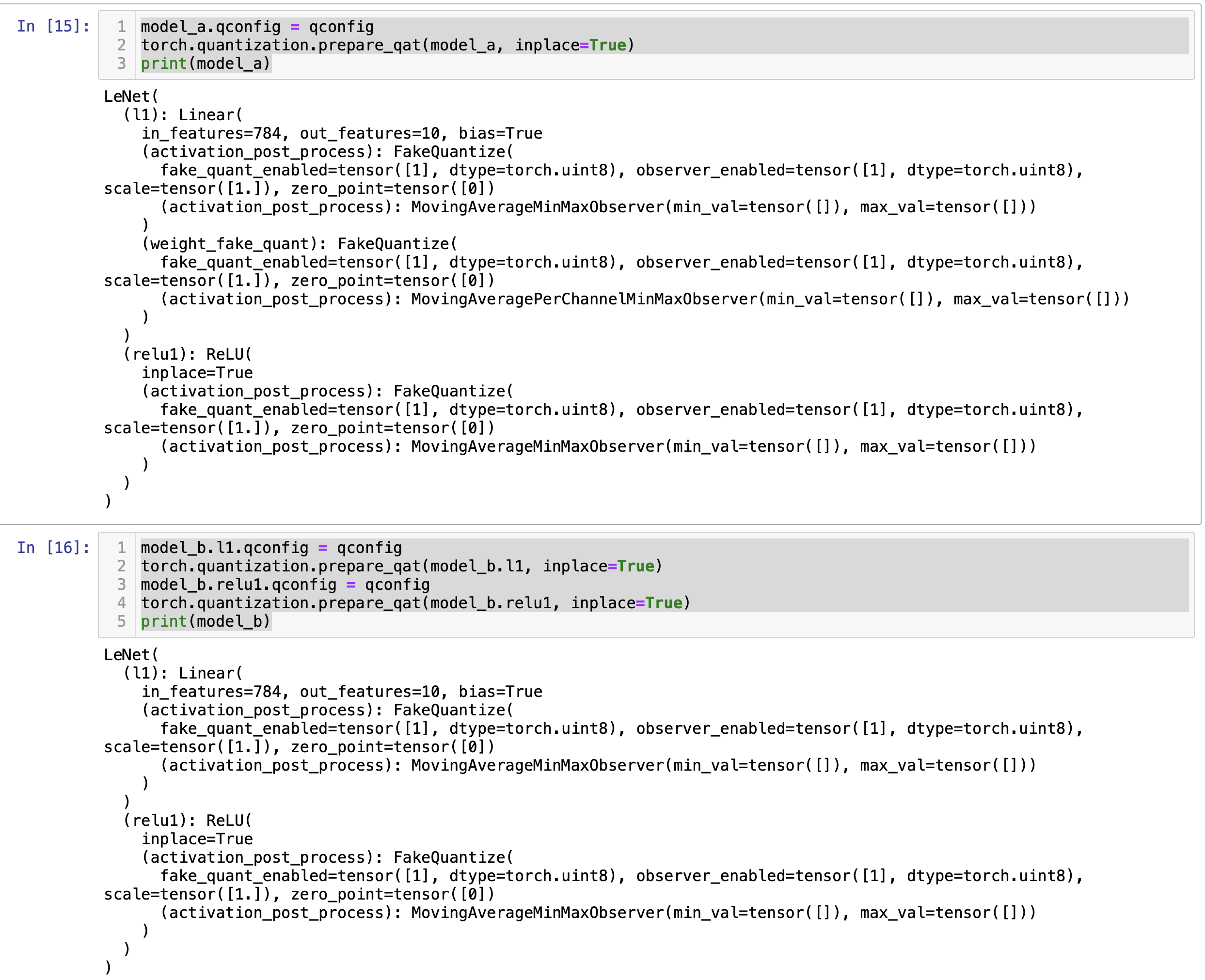
I’m interested in quantizing a subset of models and like to apply prepare_qat selectively. However, a simple test code below reveals that such a selective case will not lead to the same quant-prep as the case where it is done at the top-level.
class LeNet(nn.Module):
def __init__(self): super().__init__() self.l1 = nn.Linear(28 * 28, 10) self.relu1 = nn.ReLU(inplace=True) def forward(self, x): return self.relu1(self.l1(x.view(x.size(0), -1)))model_a = LeNet()
model_b = LeNet()
qconfig = torch.quantization.get_default_qat_qconfig()
Now, when comparing two ways of apply prepare_qat
- top-level prepare_qat
model_a.qconfig = qconfig
torch.quantization.prepare_qat(model_a, inplace=True)
print(model_a)
- layer-wise prepare_qat
model_b.l1.qconfig = qconfig
torch.quantization.prepare_qat(model_b.l1, inplace=True)
model_b.relu1.qconfig = qconfig
torch.quantization.prepare_qat(model_b.relu1, inplace=True)
print(model_b)
You can see below that print(model_a) and print(model_b) will yield different results, notably, weight_fake_quant is missing in model_b.l1. Can someone explain why these two have different behaviors and the right way to do selective quantization?