Hey, I am trying to train a FCN model(https://pytorch.org/vision/stable/models/generated/torchvision.models.segmentation.fcn_resnet50.html#torchvision.models.segmentation.fcn_resnet50) on a segmentation dataset however the loss doesn’t seem to decrease and converge and I’m totally clueless why. I do my backward and forward propagation as well and zero grad my optimizer and .train() my model when needed.
This is my training code:
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from tqdm import tqdm
from torchsummary import summary
if torch.cuda.is_available():
DEVICE = 'cuda:0'
print('Running on the GPU')
else:
DEVICE = "cpu"
print('Running on the CPU')
MODEL_PATH = '/content/best_model.pth'
LOAD_MODEL = False
BATCH_SIZE = 16
LEARNING_RATE = 0.001
EPOCHS = 100
CLASSES = ['grass', 'weed', 'crop']
TRANSFORMS = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def check_accuracy(loader, model, num_classes=3, device="cuda"):
num_correct = 0
num_pixels = 0
dice_score = 0
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device).float()
y = y.to(device).float()
preds = model(x)
preds = torch.sigmoid(preds['out'])
for i in range(0, num_classes):
preds_ = (preds[:, i, :, :] > 0.5).float()
y_ = y[:, i, :, :]
num_correct += (preds_ == y_).sum()
num_pixels += torch.numel(preds_)
dice_score += (2 * (preds_ * y_).sum()) / (
(preds_ + y_).sum() + 1e-8
)
print(
f"Got {num_correct}/{num_pixels} with acc {num_correct/num_pixels*100:.2f}"
)
# print(f"Dice score: {dice_score/len(loader)}")
model.train()
return dice_score/(len(loader) * num_classes)
def train_function(data, model, optimizer, loss_fn, device):
print('Entering into train function')
loss_fn.requires_grad = True
loss_values = []
data = tqdm(data)
model.train()
for index, batch in enumerate(data):
X, y = batch
X, y = X.to(device), y.to(device)
#X = X.permute(0, 3, 1, 2).float()
#y = y.permute(0, 3, 1, 2).float()
#print(X.shape)
#print(y.shape)
optimizer.zero_grad()
preds = model(X)
#visualize(image=preds['out'][0].permute(1, 2, 0).cpu())
preds['out'].requires_grad = True
loss = loss_fn(preds['out'], y)
loss.backward()
optimizer.step()
data.set_description(f"Loss: {loss.item()}")
print(f"Dice Score: {check_accuracy(data, model)}")
return loss.item()
def main():
global epoch
epoch = 0 # epoch is initially assigned to 0. If LOAD_MODEL is true then
# epoch is set to the last value + 1.
LOSS_VALS = [] # Defining a list to store loss values after every epoch
train_dataset = WeedsDataset("/content/dataset/images", '/content/dataset/annotations', classes=['grass', 'weed', 'crop'],
process=TRANSFORMS, process_mask=TRANSFORMS_MASK)
train_set = DataLoader(train_dataset, batch_size=8, shuffle=True)
print('Data Loaded Successfully!')
# Defining the model, optimizer and loss function
model = torch.hub.load('pytorch/vision:v0.10.0', 'fcn_resnet50', num_classes=3, pretrained=False).train().to(DEVICE)
ct = 0
for child in model.children():
ct += 1
if ct < 10:
for param in child.parameters():
param.requires_grad = False
params = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
loss_function = nn.BCEWithLogitsLoss().to(DEVICE)
# Loading a previous stored model from MODEL_PATH variable
if LOAD_MODEL == True:
checkpoint = torch.load(MODEL_PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optim_state_dict'])
epoch = checkpoint['epoch']+1
LOSS_VALS = checkpoint['loss_values']
print("Model successfully loaded!")
#Training the model for every epoch.
for e in range(epoch, EPOCHS):
print(f'Epoch: {e}')
loss_val = train_function(train_set, model, optimizer, loss_function, DEVICE)
LOSS_VALS.append(loss_val)
torch.save({
'model_state_dict': model.state_dict(),
'optim_state_dict': optimizer.state_dict(),
'epoch': e,
'loss_values': LOSS_VALS
}, MODEL_PATH)
print("Epoch completed and model successfully saved!")
main()
The loss:
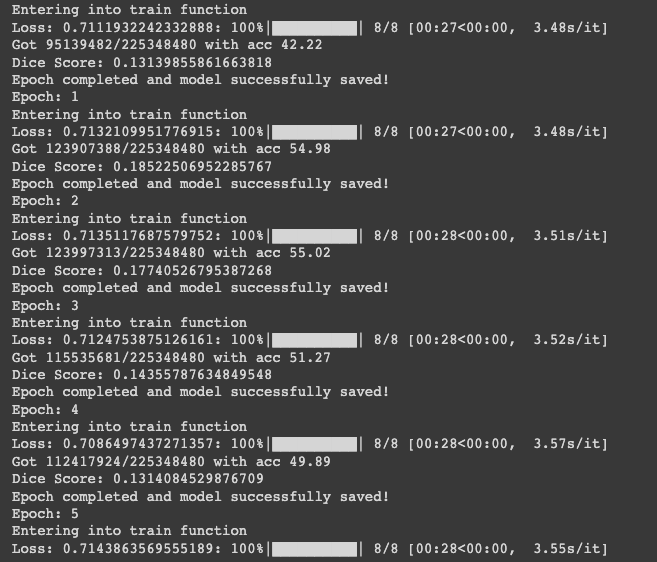
Let me know if there is anything that I can fix.