I am trying reinforcement learning using pytorch,
and when I load a pretrained model as initial,
the performance is worse at begin, and it become better very fast
this is a plot the shows the performance drop when resume.
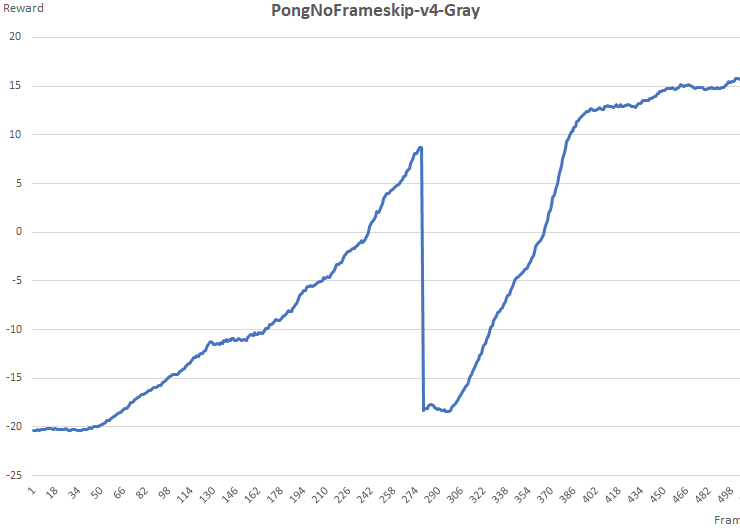
I save my model like this post suggest:
and I didn’t delete any layer of my model
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'optimizer' : optimizer.state_dict(),
})
def save_checkpoint(state, filename='checkpoint.pth.tar'):
torch.save(state, filename)
and resume model like this:
def load_pretrained(model, pretrained_dict):
model_dict = model.state_dict()
# filter out unmatch dict
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
model.load_state_dict(pretrained_dict)
if checkpoint_file is not None:
print('loading checkpoint_file {}'.format(checkpoint_file))
cp = torch.load(checkpoint_file)
load_pretrained(optimizer, cp['optimizer'])
load_pretrained(state_dict, cp['state_dict'])
trained_episodes = cp['epoch']
Is that normal that need some time to let the performance recover?