fatmelon
December 17, 2018, 11:11am
1
Hi,
I have a cross validation code as follows:
train_preds = np.zeros((len(train_X)))
test_preds = np.zeros((len(test_X)))
seed_torch(SEED)
x_test_cuda = torch.tensor(test_X, dtype=torch.long).cuda()
test = torch.utils.data.TensorDataset(x_test_cuda)
test_loader = torch.utils.data.DataLoader(test, batch_size=batch_size, shuffle=False)
for i, (train_idx, valid_idx) in enumerate(splits):
x_train_fold = torch.tensor(train_X[train_idx], dtype=torch.long).cuda()
y_train_fold = torch.tensor(train_y[train_idx, np.newaxis], dtype=torch.float32).cuda()
x_val_fold = torch.tensor(train_X[valid_idx], dtype=torch.long).cuda()
y_val_fold = torch.tensor(train_y[valid_idx, np.newaxis], dtype=torch.float32).cuda()
model = NeuralNet()
model.cuda()
loss_fn = torch.nn.BCEWithLogitsLoss(reduction="sum")
optimizer = torch.optim.Adam(model.parameters())
train = torch.utils.data.TensorDataset(x_train_fold, y_train_fold)
valid = torch.utils.data.TensorDataset(x_val_fold, y_val_fold)
train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid, batch_size=batch_size, shuffle=False)
print(f'Fold {i + 1}')
for epoch in range(train_epochs):
start_time = time.time()
model.train()
avg_loss = 0.
for x_batch, y_batch in tqdm(train_loader, disable=True):
y_pred = model(x_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() / len(train_loader)
model.eval()
valid_preds_fold = np.zeros((x_val_fold.size(0)))
test_preds_fold = np.zeros(len(test_X))
avg_val_loss = 0.
for i, (x_batch, y_batch) in enumerate(valid_loader):
y_pred = model(x_batch).detach()
avg_val_loss += loss_fn(y_pred, y_batch).item() / len(valid_loader)
valid_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
elapsed_time = time.time() - start_time
print('Epoch {}/{} \t loss={:.4f} \t val_loss={:.4f} \t time={:.2f}s'.format(
epoch + 1, train_epochs, avg_loss, avg_val_loss, elapsed_time))
for i, (x_batch,) in enumerate(test_loader):
y_pred = model(x_batch).detach()
test_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
train_preds[valid_idx] = valid_preds_fold
test_preds += test_preds_fold / len(splits)
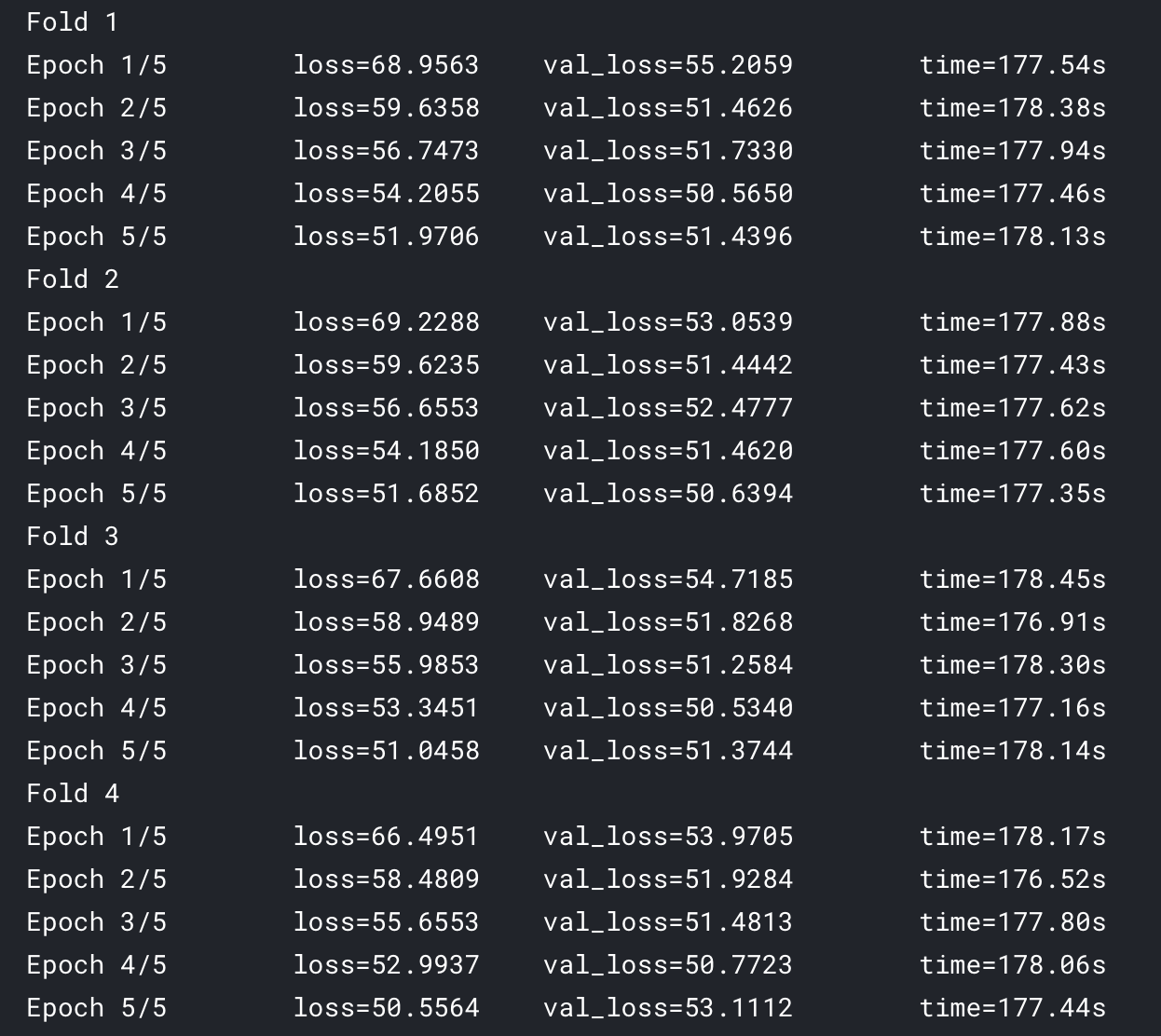
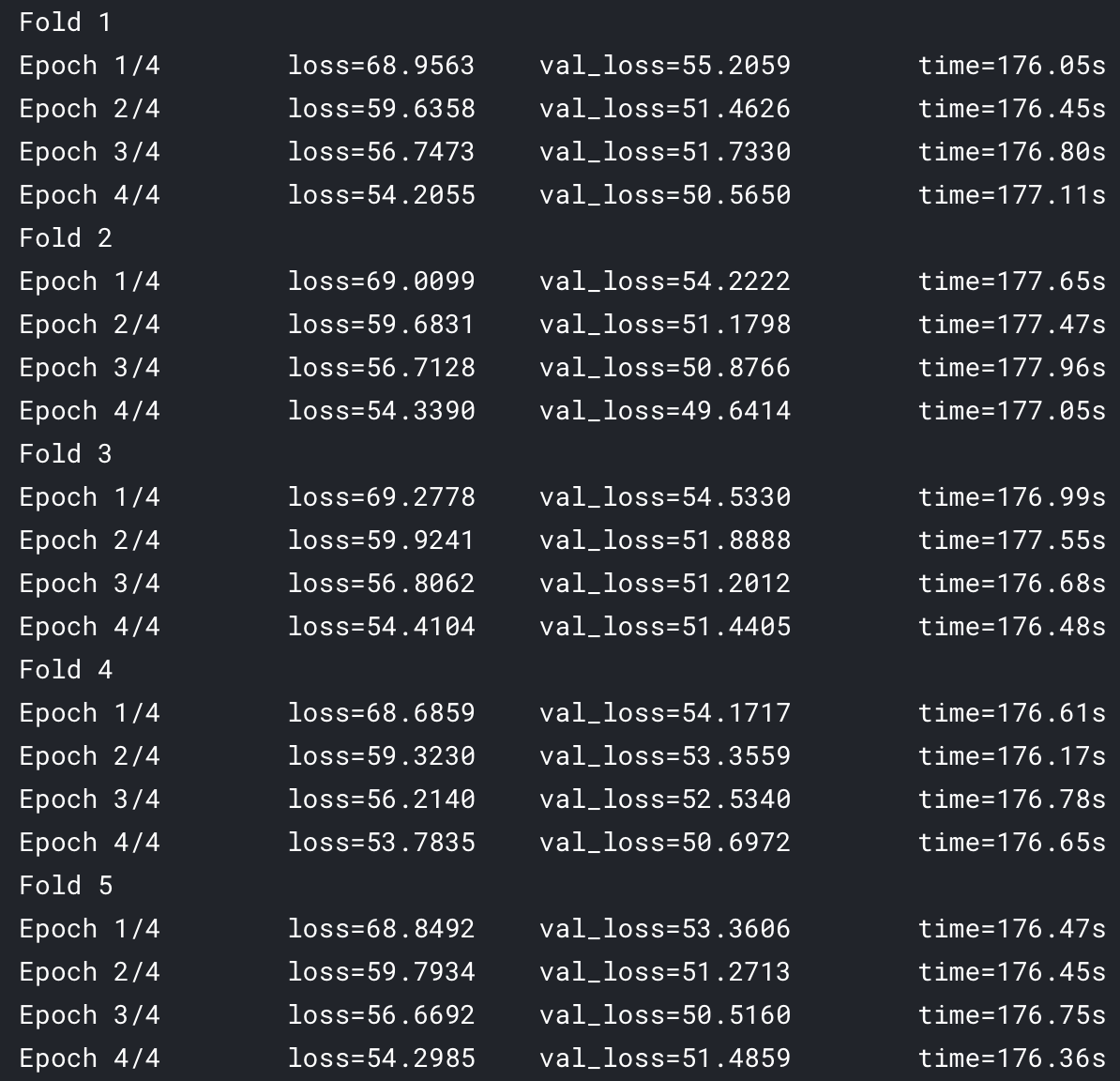
When I modified epoch, the results were very strange, only the training curve of the first fold is consistent:
It seems that the initialization state of the model is different from the second fold to the 4th fold.
Thanks!
2 Likes
ptrblck
December 17, 2018, 4:00pm
2
The additional epoch might have called the random number generator at some place, thus yielding other results in the following folds.state_dict (using copy.deepcopy) and then reinitialize it for each fold instead of recreating the model for each fold.
fatmelon
December 18, 2018, 9:25am
3
Hi,
Thank you for your reply. According to your suggestion, the code I modified is as follows:
import copy
model = NeuralNet()
optimizer = torch.optim.Adam(model.parameters())
init_state = copy.deepcopy(model.state_dict())
init_state_opt = copy.deepcopy(optimizer.state_dict())
train_preds = np.zeros((len(train_X)))
test_preds = np.zeros((len(test_X)))
seed_torch(SEED)
x_test_cuda = torch.tensor(test_X, dtype=torch.long).cuda()
test = torch.utils.data.TensorDataset(x_test_cuda)
test_loader = torch.utils.data.DataLoader(test, batch_size=batch_size, shuffle=False)
for i, (train_idx, valid_idx) in enumerate(splits):
model.load_state_dict(init_state)
optimizer.load_state_dict(init_state_opt)
x_train_fold = torch.tensor(train_X[train_idx], dtype=torch.long).cuda()
y_train_fold = torch.tensor(train_y[train_idx, np.newaxis], dtype=torch.float32).cuda()
x_val_fold = torch.tensor(train_X[valid_idx], dtype=torch.long).cuda()
y_val_fold = torch.tensor(train_y[valid_idx, np.newaxis], dtype=torch.float32).cuda()
# model = NeuralNet()
model.cuda()
loss_fn = torch.nn.BCEWithLogitsLoss(reduction="sum")
# optimizer = torch.optim.Adam(model.parameters())
train = torch.utils.data.TensorDataset(x_train_fold, y_train_fold)
valid = torch.utils.data.TensorDataset(x_val_fold, y_val_fold)
train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid, batch_size=batch_size, shuffle=False)
print(f'Fold {i + 1}')
for epoch in range(train_epochs):
start_time = time.time()
model.train()
avg_loss = 0.
for x_batch, y_batch in tqdm(train_loader, disable=True):
y_pred = model(x_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() / len(train_loader)
model.eval()
valid_preds_fold = np.zeros((x_val_fold.size(0)))
test_preds_fold = np.zeros(len(test_X))
avg_val_loss = 0.
for i, (x_batch, y_batch) in enumerate(valid_loader):
y_pred = model(x_batch).detach()
avg_val_loss += loss_fn(y_pred, y_batch).item() / len(valid_loader)
valid_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
elapsed_time = time.time() - start_time
print('Epoch {}/{} \t loss={:.4f} \t val_loss={:.4f} \t time={:.2f}s'.format(
epoch + 1, train_epochs, avg_loss, avg_val_loss, elapsed_time))
for i, (x_batch,) in enumerate(test_loader):
y_pred = model(x_batch).detach()
test_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
train_preds[valid_idx] = valid_preds_fold
test_preds += test_preds_fold / len(splits)
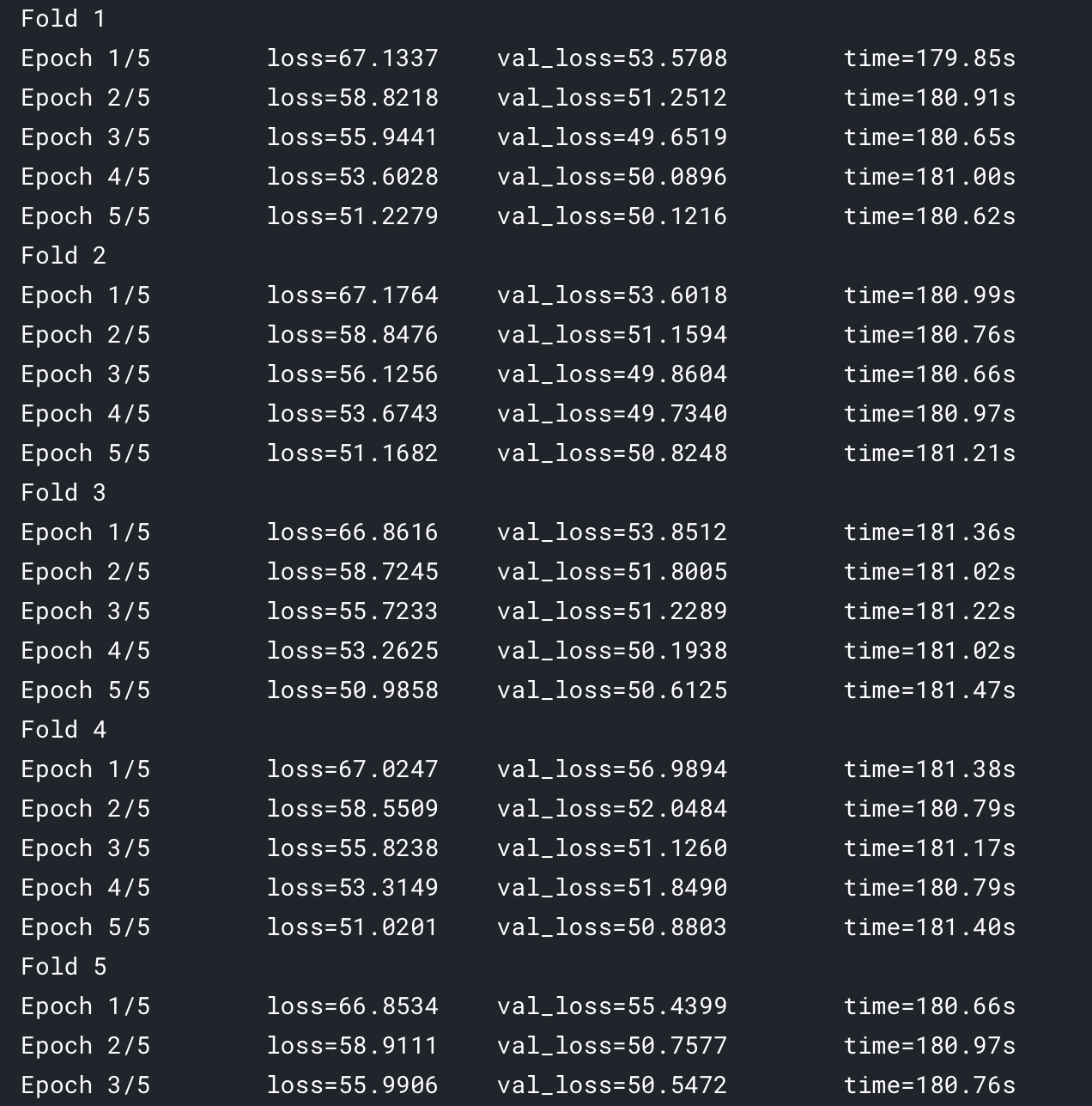
Strangely, even the curve of fold0 is not consistent after modification:
I wonder if I misunderstood your meaning? If so, please point it out.
Thanks
ptrblck
December 18, 2018, 11:09pm
4
Could you try to move the seed before the first model creation and try it again?
fatmelon
December 19, 2018, 1:23pm
5
Hi,
I modify the code as follow:
import copy
seed_torch(SEED)
model = NeuralNet()
optimizer = torch.optim.Adam(model.parameters())
init_state = copy.deepcopy(model.state_dict())
init_state_opt = copy.deepcopy(optimizer.state_dict())
train_preds = np.zeros((len(train_X)))
test_preds = np.zeros((len(test_X)))
x_test_cuda = torch.tensor(test_X, dtype=torch.long).cuda()
test = torch.utils.data.TensorDataset(x_test_cuda)
test_loader = torch.utils.data.DataLoader(test, batch_size=batch_size, shuffle=False)
for i, (train_idx, valid_idx) in enumerate(splits):
model.load_state_dict(init_state)
optimizer.load_state_dict(init_state_opt)
x_train_fold = torch.tensor(train_X[train_idx], dtype=torch.long).cuda()
y_train_fold = torch.tensor(train_y[train_idx, np.newaxis], dtype=torch.float32).cuda()
x_val_fold = torch.tensor(train_X[valid_idx], dtype=torch.long).cuda()
y_val_fold = torch.tensor(train_y[valid_idx, np.newaxis], dtype=torch.float32).cuda()
# model = NeuralNet()
model.cuda()
loss_fn = torch.nn.BCEWithLogitsLoss(reduction="sum")
# optimizer = torch.optim.Adam(model.parameters())
train = torch.utils.data.TensorDataset(x_train_fold, y_train_fold)
valid = torch.utils.data.TensorDataset(x_val_fold, y_val_fold)
train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid, batch_size=batch_size, shuffle=False)
print(f'Fold {i + 1}')
for epoch in range(train_epochs):
start_time = time.time()
model.train()
avg_loss = 0.
for x_batch, y_batch in tqdm(train_loader, disable=True):
y_pred = model(x_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() / len(train_loader)
model.eval()
valid_preds_fold = np.zeros((x_val_fold.size(0)))
test_preds_fold = np.zeros(len(test_X))
avg_val_loss = 0.
for i, (x_batch, y_batch) in enumerate(valid_loader):
y_pred = model(x_batch).detach()
avg_val_loss += loss_fn(y_pred, y_batch).item() / len(valid_loader)
valid_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
elapsed_time = time.time() - start_time
print('Epoch {}/{} \t loss={:.4f} \t val_loss={:.4f} \t time={:.2f}s'.format(
epoch + 1, train_epochs, avg_loss, avg_val_loss, elapsed_time))
for i, (x_batch,) in enumerate(test_loader):
y_pred = model(x_batch).detach()
test_preds_fold[i * batch_size:(i+1) * batch_size] = sigmoid(y_pred.cpu().numpy())[:, 0]
train_preds[valid_idx] = valid_preds_fold
test_preds += test_preds_fold / len(splits)
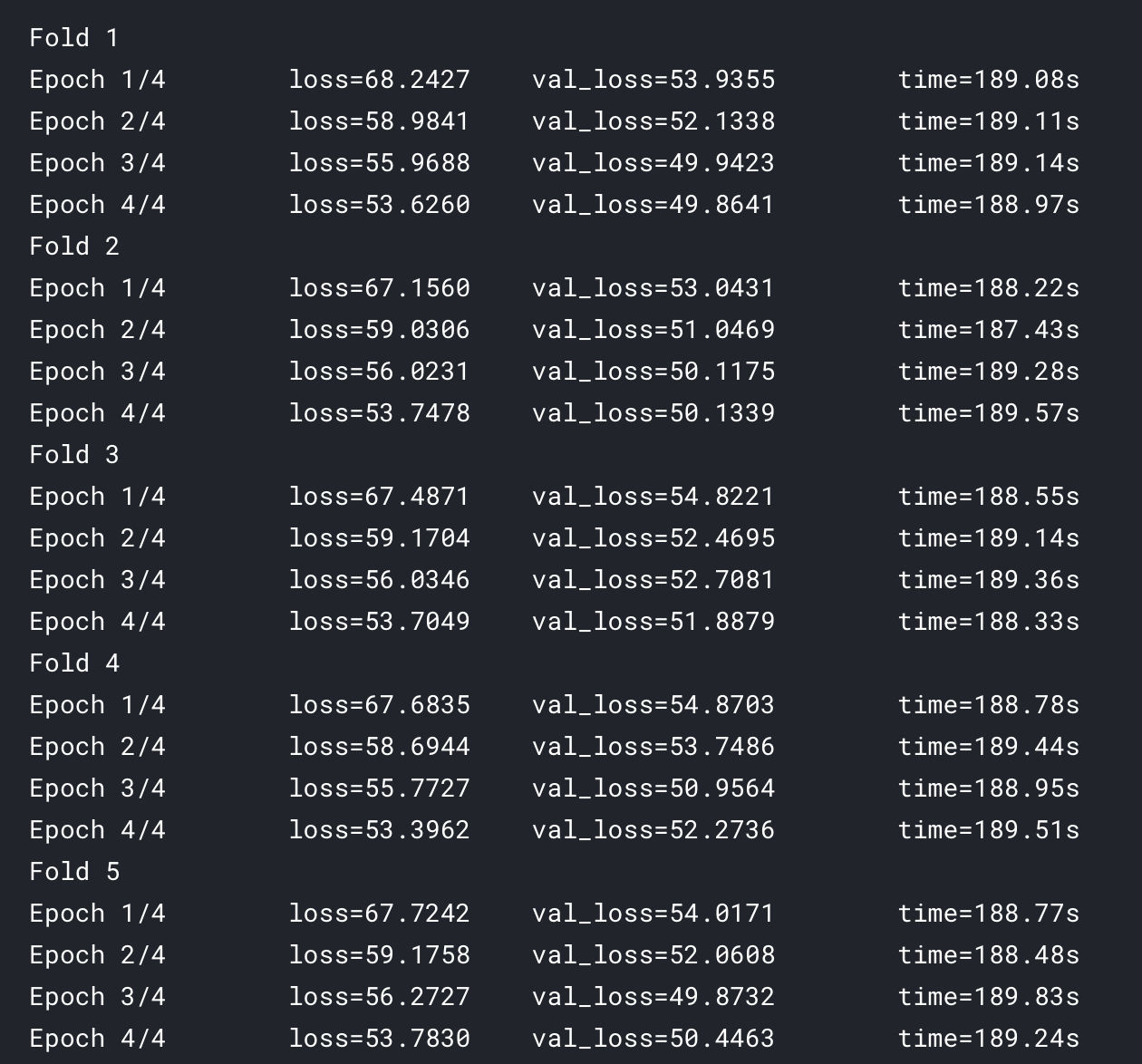
The problem seems to have returned to its origin
I wonder if there are other parameters besides the model and optimizer that need to be reset or initialized at first?
ptrblck
December 19, 2018, 5:10pm
6
Haha, oh boy.state_dicts in the training loop. Now the results are equal.
fatmelon
December 20, 2018, 8:55am
7
Thank you for your kind help
For the convenience of others, I also post the code seed_torch :
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
Actually, I’m working on a kaggle competition and reproducibility is very important. That’s one of the reasons I use pytorch.
Finally, thank you again for your help.
4 Likes
ptrblck
December 20, 2018, 10:04am
8
Good to hear it’s working and good luck in the competition!

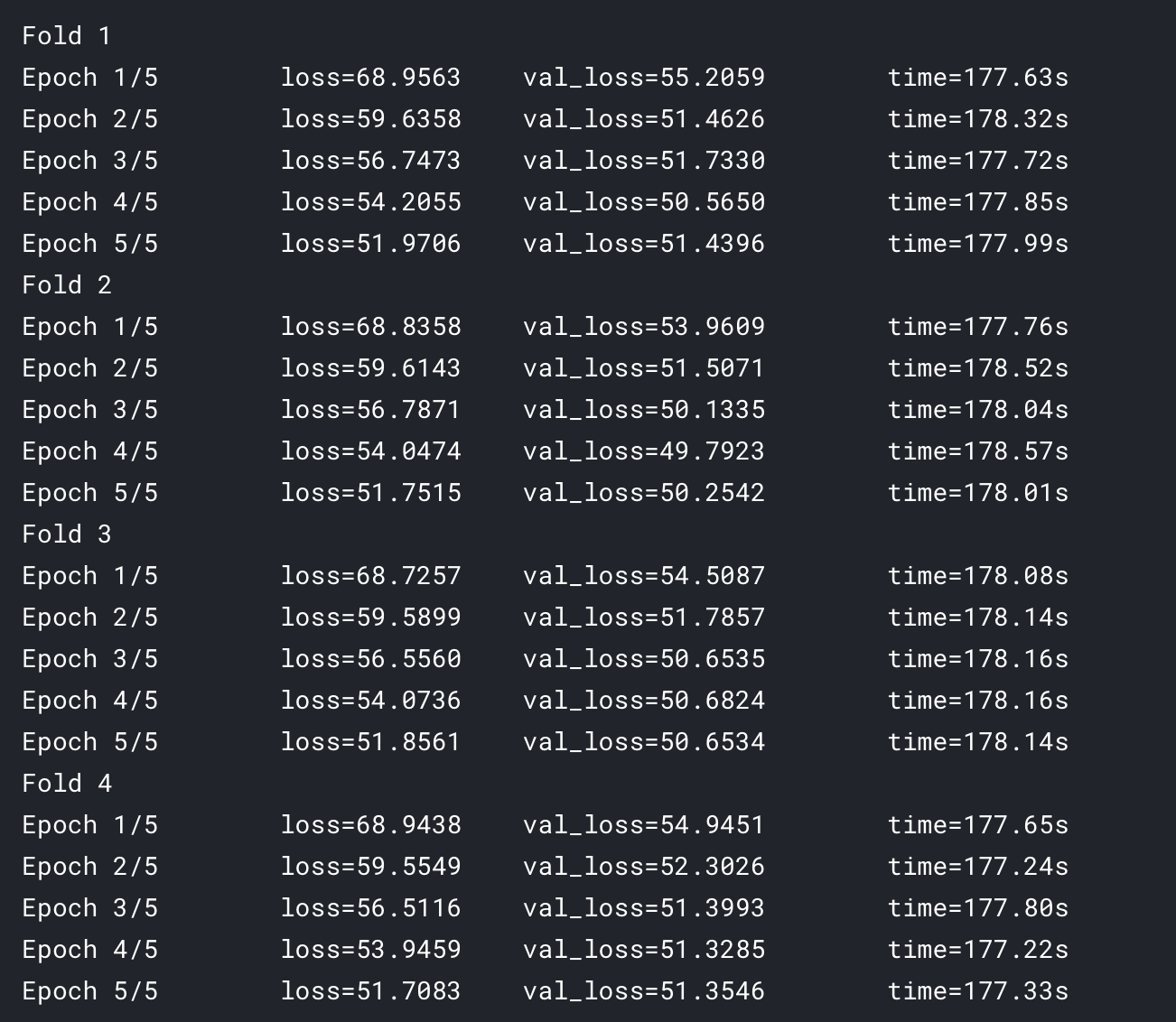
 . As you said, the results are equal.
. As you said, the results are equal.