Hello!
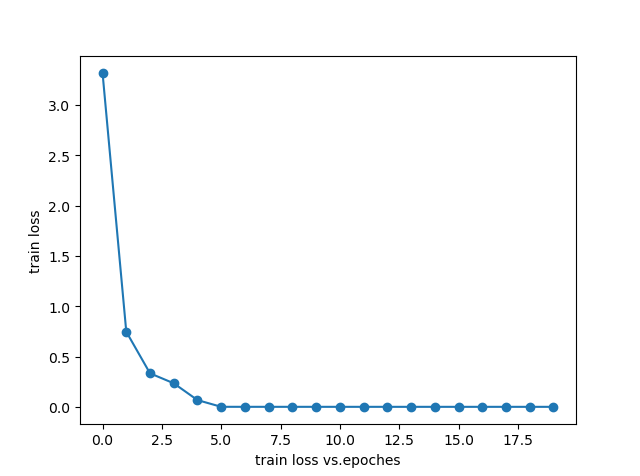
Recently I use a CNN to estimate whether two images are similar or not. But a problem occurred during training. When I train the network, the train loss usually kept 0 or 0.69 without any trend of decline. Hope there are someone can help me…
The size of the input image is 246x192.
the network and training code are as follows:
network:
import math
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, 3, padding=1)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = nn.Conv2d(inplanes, planes, 1)
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResCompare(nn.Module):
def __init__(self):
super(ResCompare, self).__init__()
self.conv1 = nn.Conv2d(2, 32, 5, padding=2, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU(inplace=True)
self.max_pool = nn.MaxPool2d(2)
self.layer1 = BasicBlock(32, 64)
self.layer2 = BasicBlock(64, 128)
self.layer3 = BasicBlock(128, 256)
self.layer4 = BasicBlock(256, 512)
self.fc1 = nn.Linear(92160, 2)
self.dropout = nn.Dropout2d(p=0.5)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.max_pool(x)
x = self.layer1(x)
x = F.max_pool2d(x, 2)
x = self.layer2(x)
x = F.max_pool2d(x, 2)
x = self.layer3(x)
x = F.max_pool2d(x, 2)
x = self.layer4(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.dropout(x)
return x
train:
import os
import torch
import sys
from torch.autograd import Variable
import torch.nn as nn
import torch.utils.data as Data
import rescompare
import dataprocess
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
sys.path.append('twochannel')
N = 5
learning_rate=0.0001
cnn = rescompare.ResCompare().cuda()
optimizer = torch.optim.Adam(cnn.parameters(), learning_rate, weight_decay=1e-4)
loss_func = nn.CrossEntropyLoss()
print(cnn)
x_train, y_train = dataprocess.data("train")
train_data = Data.TensorDataset(x_train, y_train)
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=1,
shuffle=True,
)
modelpath='E:/Data/torchmodel/2019_09_20_samepeople_epoch5.pth'
for epoch in range(0, N):
for step, (x_batch, y_batch) in enumerate(train_loader):
cnn.train()
x_var = Variable(x_batch).cuda()
y_var = Variable(y_batch).cuda().long()
optimizer.zero_grad()
netout = cnn(x_var)
loss = loss_func(netout, y_var)
loss.backward()
optimizer.step()
if step % 36 == 0:
print('epoch {},step {}/50,Train Loss: {:.6f}'.format(epoch + 1, (step // 36) + 1, loss.item()))
print(netout)
print('\n')
torch.save(cnn.state_dict(), modelpath)