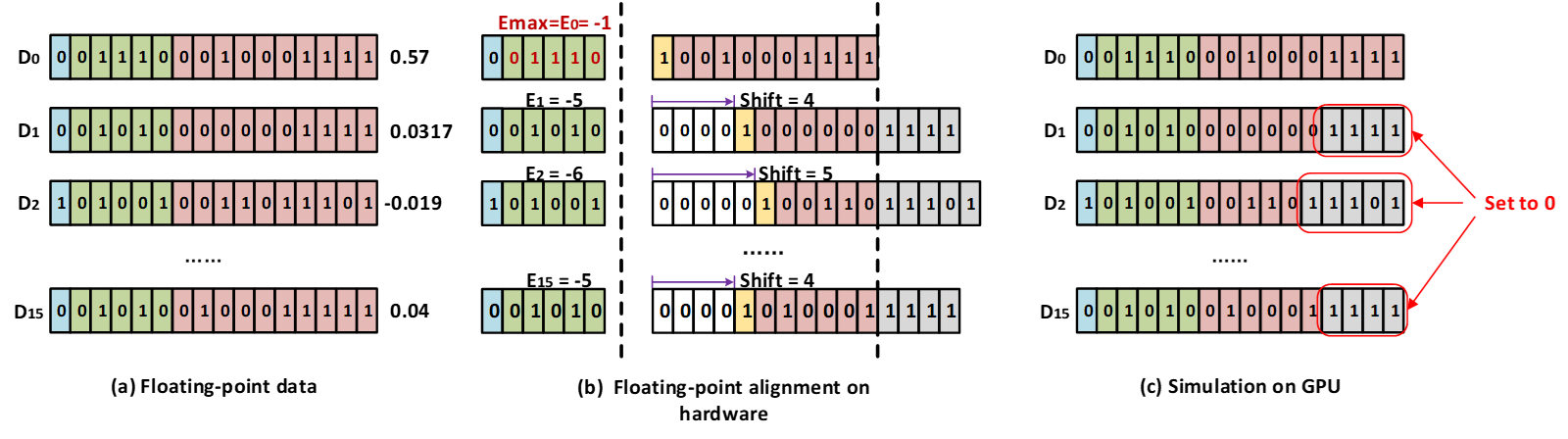
I want to simulate the behavior of floating-point calculations on hardware, which is to align the floating-point exponent of a set of floating-point data, and then truncate the excess mantissa bits. I use this method to fine-tune the ViT-tiny model on ImageNet.
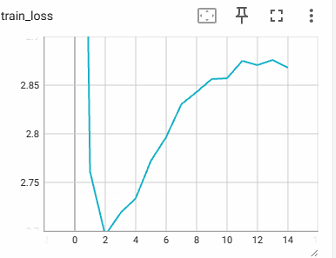
However once I quantify weights when training, it becomes non-convergent. The training loss becomes weird, what may happen after epoch 2?
If i need any extra operations when quantinization?
This is part of my training codes.
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
images=images.to(device)
if half_p:
images=images.half()
model.module.head.weight.data.copy_(tensor_aligned(model.module.head.weight.data,align=False,device=device,pad_val=-100))
pred = model(images)
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
model.module.head.weight.grad.copy_(tensor_aligned(model.module.head.weight.grad,device=device,pad_val=-100))
optimizer.step()
optimizer.zero_grad()
This function is to quantify weights as shown in fig (c)
def tensor_aligned(src,device,align=True,g_size=128,cut_num=0,pad_val=0):
if align == True:
src_shape=src.shape
pad_size= int((g_size-src_shape[-1] % g_size) % g_size)
_, exponent = torch.frexp(src)
exponent=exponent.to(torch.int16)
exponent=torch.nn.functional.pad(exponent,(0,pad_size),value=pad_val)
pad_shape=exponent.shape
exponent=exponent.reshape(-1,g_size)
src=torch.nn.functional.pad(src,(0,pad_size)).reshape(-1,g_size)
src=src.view(torch.int16)
exp_max=torch.max(exponent,1).values.reshape(-1,1)
exp_sft=exp_max-exponent
exp_sft=torch.where(exp_sft>10,0,exp_sft)
mask=torch.full(exp_sft.shape, -1, dtype=torch.int16).to(device)
mask=torch.bitwise_left_shift(mask,exp_sft)
src=torch.bitwise_and(src,mask)
src=src.view(torch.float16)
src=src.reshape(pad_shape)
src=src[... , :src_shape[-1]]
return src
`