Hello,
I am having a problem training a 1D convolution NN. My dataset is of the shape [B,C,W] – [50, 1, 402] i.e. trained in a batch of 50 with 1 channel and 402 time samples (each sample is a kind of signal). The problem I am trying to solve is to estimate a value based on the provided signal as input. For instance, each signal will have a different value of output and I am training a network to estimate the output value.
I used the following 1D convolution NN configuration.
class Simple1DCNN(torch.nn.Module):
def __init__(self):
super(Simple1DCNN, self).__init__()
self.layer1 = torch.nn.Conv1d(in_channels = 1, out_channels = 10, kernel_size = 5)
self.act = torch.nn.ReLU()
self.layer2 = torch.nn.Conv1d(in_channels = 10, out_channels = 20, kernel_size = 5)
self.fc1 = torch.nn.Linear(20*394, 100)
self.fc2 = torch.nn.Linear(100, 50)
self.fc3 = torch.nn.Linear(50, 1)
self.conv2_drop = torch.nn.Dropout(0.5)
def forward(self, x):
x = self.act(self.layer1(x))
x = self.act(self.conv2_drop(self.layer2(x)))
x = x.view(-1, x.shape[1] * x.shape[-1])
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc3(x) # collecting the output of linear layer
return x
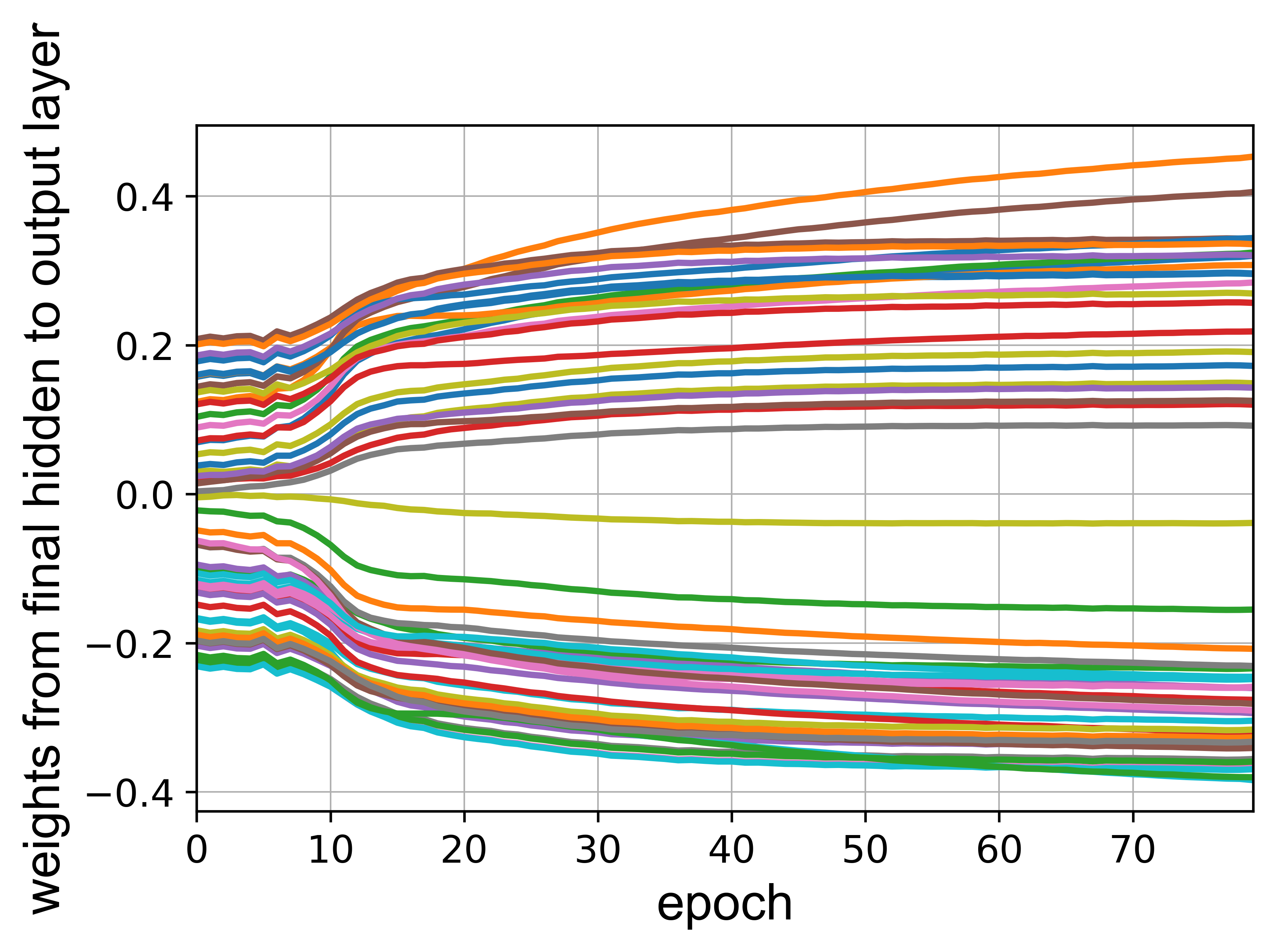
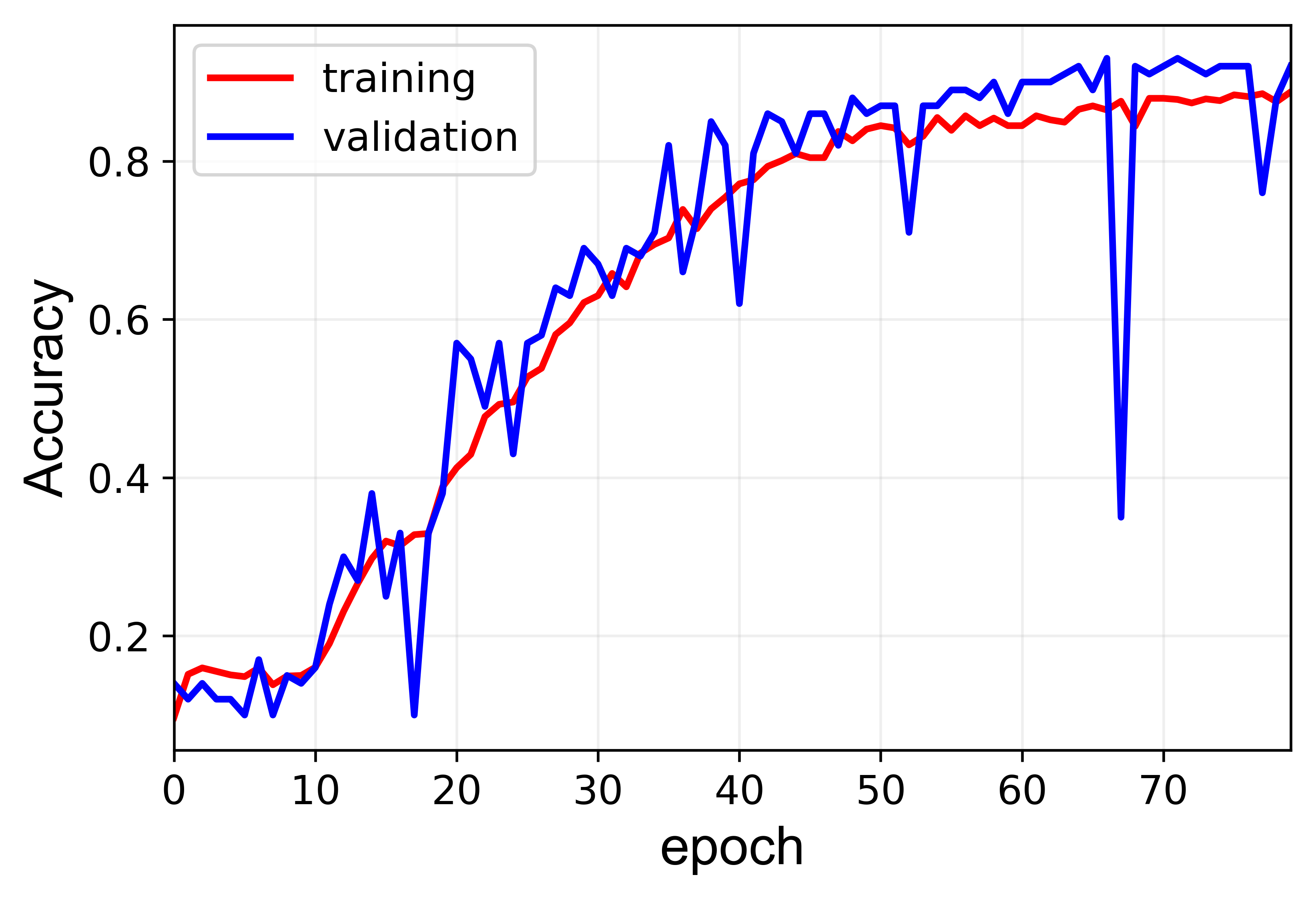
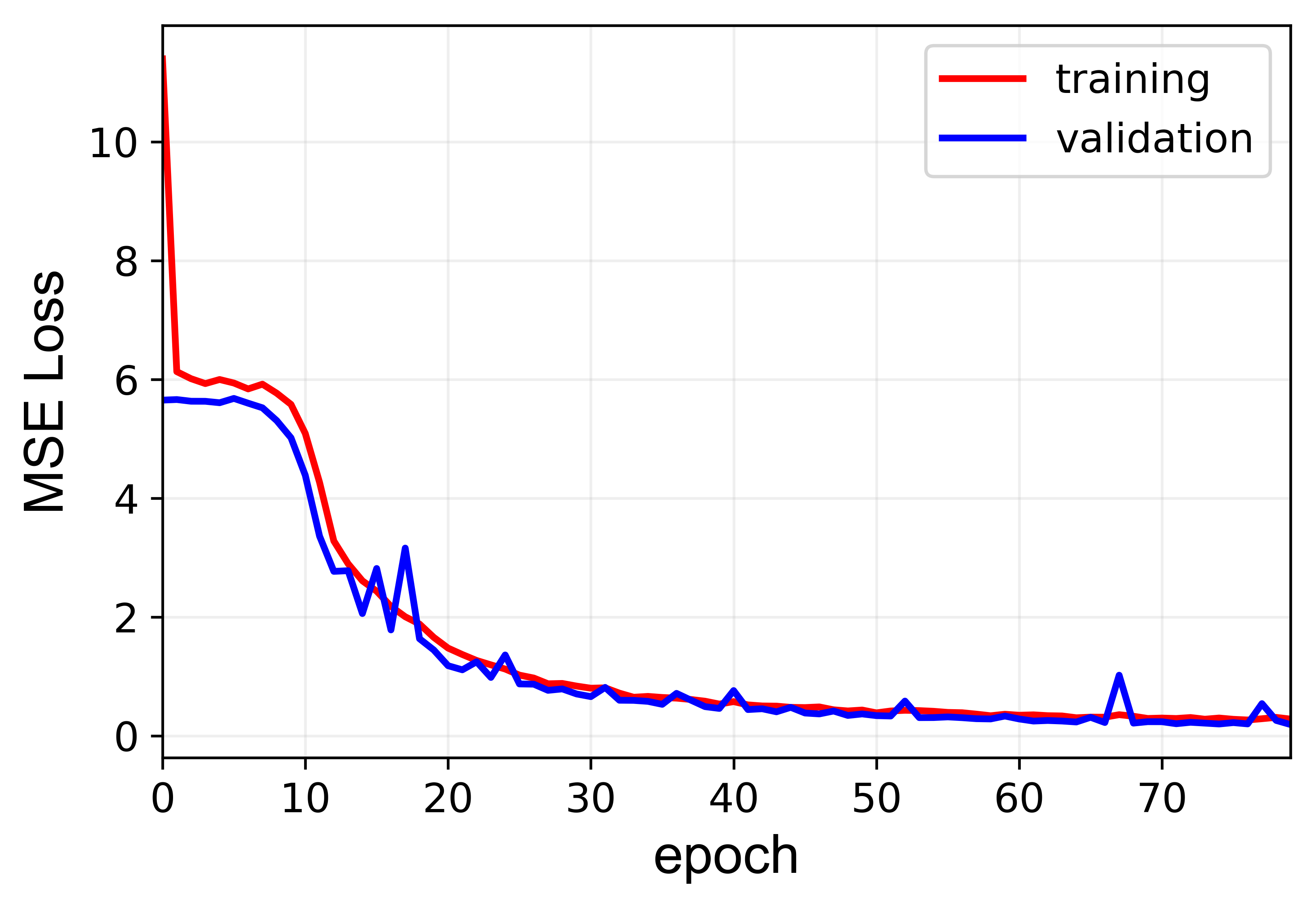
the problem is that networking is overfitting the training set which can be seen from the results below:

You can see that the training loss is decreasing while the validation loss is not. Here, a tolerance of 10% is defined so that if the output is within 10% of the actual output it is counted as an accurate prediction (this is just for my personal info and has no relation with the training process).
I have done everything, from normalizing the inputs to splitting the dataset to a random training and validation set (80% - 20%)
Some other use full information are:
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr = 1e-3, momentum = 0.5, weight_decay = 0.01)
Can anybody help me with this??