I am a beginner of the PyTorch, now I am writing a code for the time series forecasting by LSTM. The LSTM includes two layers and stacks together. The first layer of LSTM includes 10 LSTM units and the hidden units will pass to another layer of LSTM which includes a single LSTM unit. The following is the architecture diagram of the neural network.
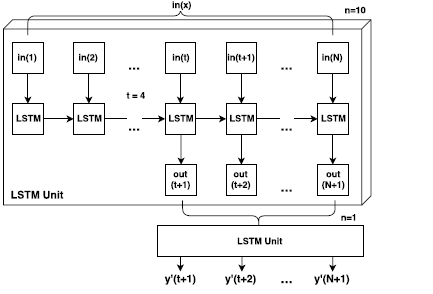
following is my code,
def __init__(self, nb_features=1, hidden_size_1=100, hidden_size_2=100, nb_layers_1 =5, nb_layers_2 = 1, dropout=0.4): #(self, nb_features=1, hidden_size=100, nb_layers=10, dropout=0.5): ####### nb_layers=5
super(Sequence, self).__init__()
self.nb_features = nb_features
self.hidden_size_1 = hidden_size_1
self.hidden_size_2 = hidden_size_2
self.nb_layers_1 =nb_layers_1
self.nb_layers_2 = nb_layers_2
self.lstm_1 = nn.LSTM(self.nb_features, self.hidden_size_1, self.nb_layers_1, dropout=dropout) #, dropout=dropout
self.lstm_2 = nn.LSTM(self.hidden_size_1, self.hidden_size_2, self.nb_layers_2, dropout=dropout)
self.lin = nn.Linear(self.hidden_size_2, 1)
def forward(self, input):
h0 = Variable(torch.zeros(self.nb_layers_1, input.size()[1], self.hidden_size_1))
h1 = Variable(torch.zeros(self.nb_layers_2, input.size()[1], self.hidden_size_2))
#print(type(h0))
c0 = Variable(torch.zeros(self.nb_layers_1, input.size()[1], self.hidden_size_1))
c1 = Variable(torch.zeros(self.nb_layers_2, input.size()[1], self.hidden_size_2))
#print(type(c0))
output_0, hn_0 = self.lstm_1(input, (h0, c0))
output, hn = self.lstm_2(output_0, (h1, c1))
out = torch.tanh(self.lin(output[-1])) ##########out = self.lin(output[-1])
#out = self.lin(output_2[-1])
return out
The code can be run, however, the output is a straight line even tuning the hyperparameter (learning rate, dropout, activation method) and increases epoch (i.e. 3000 epochs), the output result was shown in the following.
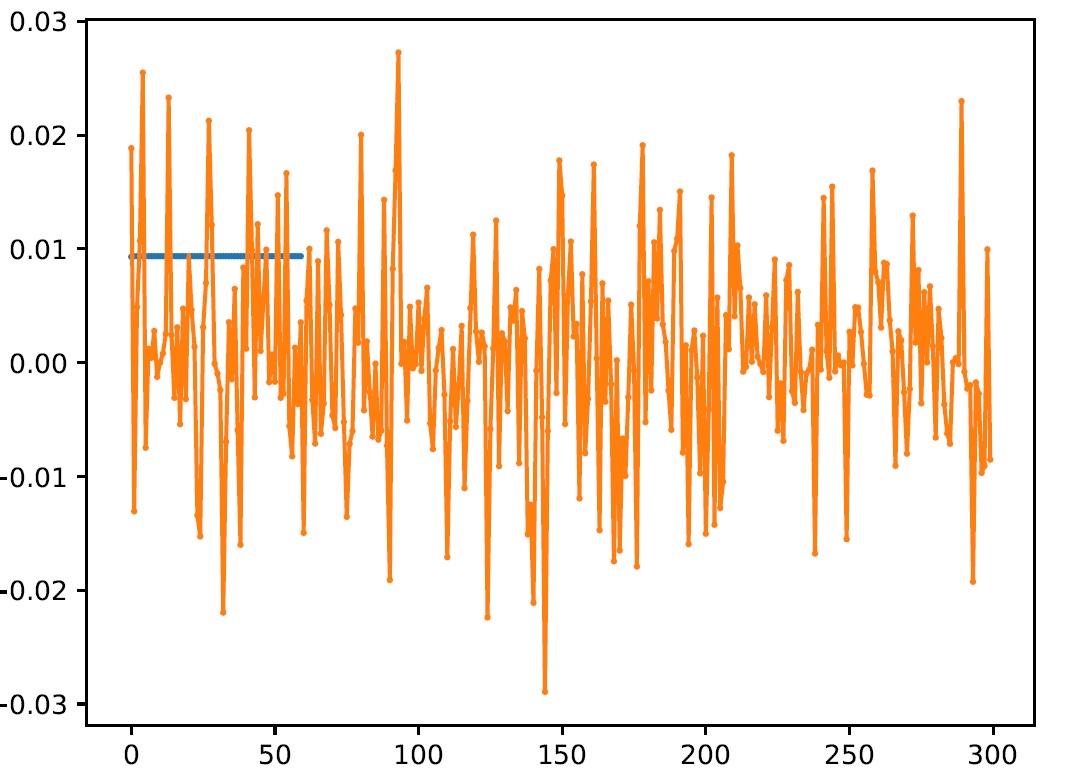
Could you please give me some suggestions to solve this problem. many thanks