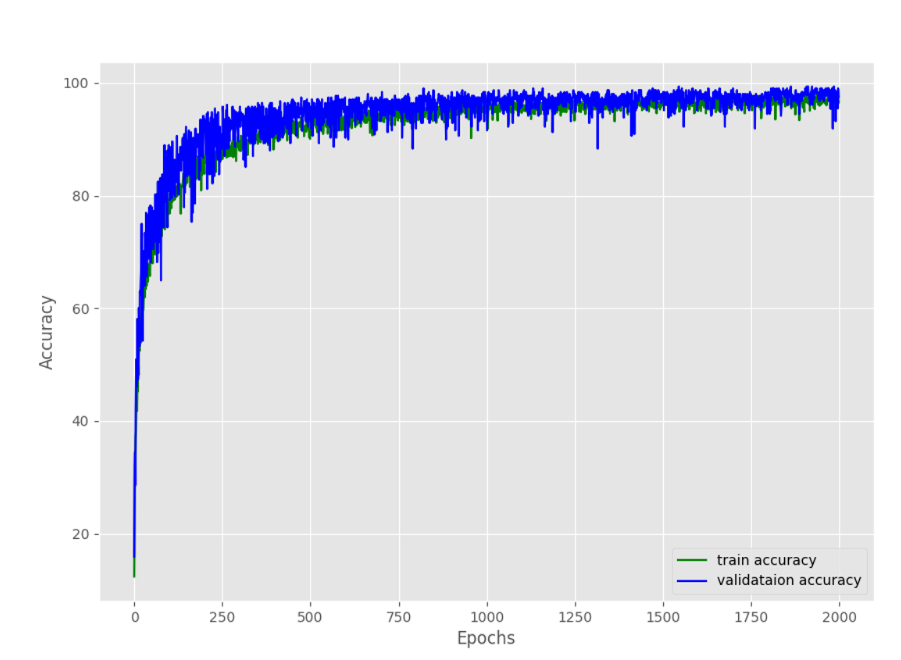
When I training my custom model and fine-tuning the pretrained resnet50 with using torchvision.datasets.ImageFolder, I have underfitting/overfitting during training and get good 98% accuracy on validation. If I use torchvision.datasets.ImageFolder to load the test folder, i get very good prediction and confusion matrix but If I reuse this transform to convert image when I scan the test folder , I always get poor prediction. I don’t know what is this problem in my cas.
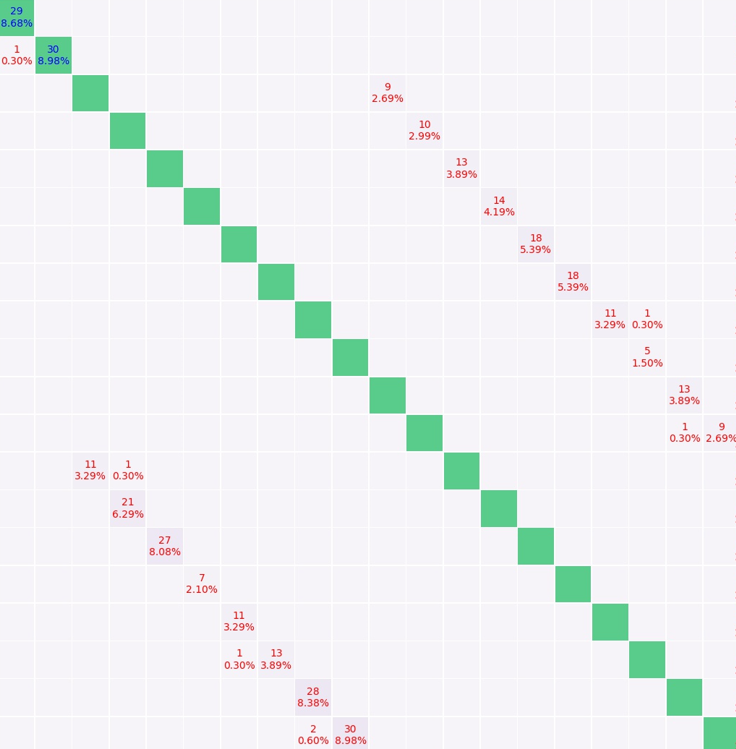
This is confusion matrix with torchvision.datasets.ImageFolder

model = models.resnet50(pretrained = False)
model.fc = nn.Sequential(nn.Linear(2048, 512),
nn.Linear(512, 20))
model=model.to(device)
checkpoint = torch.load(os.path.join(w_dir,‘checkpoints’,test_name,‘last.pth’), map_location=device)
model.load_state_dict(checkpoint[‘model_state_dict’])
test_transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0, 0, 0],
std=[1, 1, 1])])
dataset_name=‘datasets3*’
test_path=os.path.join(w_dir,‘dataset_cropped_20cl’,
dataset_name,‘test’)
test_dataset = datasets.ImageFolder(
root=test_path,
transform=test_transform)
test_loader = DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=False,
num_workers=4, pin_memory=True)
model.eval()
print(‘Make prediction’)
pred_list=list()
true_list=list()
true_name_list=list()
pred_name_list=list()
save_pred_path=os.path.join(w_dir,‘CNN_prediction’,‘checkpoints’)
if os.path.exists(save_pred_path):
shutil.rmtree(save_pred_path)
os.makedirs(save_pred_path)
with torch.no_grad():
for i, data in tqdm(enumerate(test_loader), total=len(test_loader)):
image, labels = data
image = image.to(device)
labels = labels.to(device)
outputs = model(image)
#output_label = torch.topk(outputs, 1)
#pred_class = labels[int(output_label.indices.item())]
#pred_list.append(int(output_label.indices))
#true_list.append(int(labels))
_, preds = torch.max(outputs.data, 1)
pred_list.append(int(preds))
true_list.append(int(labels))
true_name_list.append(id_to_labels[int(labels)])
pred_name_list.append(id_to_labels[int(preds)])
if int(preds)==int(labels):
print(‘prediction is good’)
print(f’ true class is {int(labels)}, predicted class is {int(preds)}‘)
print(f"GT: {id_to_labels[int(labels)]}, pred: {id_to_labels[int(preds)]}")
else:
print(‘prediction is not good’)
print(f’ true class is {int(labels)}, predicted class is {int(preds)}')
print(f"GT: {id_to_labels[int(labels)]}, pred: {id_to_labels[int(preds)]}")
This is ccconfusion matrix with using my transform
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0, 0, 0],
std=[1, 1, 1])])
dataset_name=‘datasets3*’
dataset_path=os.path.join(w_dir,‘dataset_cropped_20cl’,dataset_name,‘test’)
pred_list=list()
true_list=list()
true_name_list=list()
pred_name_list=list()
model.eval()
with torch.no_grad():
#scan test folder
for folder_name in os.listdir(dataset_path):
gt_class=folder_name
for roots,dirs,files in os.walk(os.path.join(dataset_path,folder_name)):
for file in files:
img_path=os.path.join(roots,file)
image = cv2.imread(img_path)
orig_image = image.copy()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image=test_transform(image)
image = torch.unsqueeze(image, 0)
with torch.no_grad():
outputs = model(image.to(device))
_, pred_class = torch.max(outputs.data, 1)
pred_list.append(int(pred_class))
true_list.append(int(gt_class))
true_name_list.append(id_to_labels[int(gt_class)])
pred_name_list.append(id_to_labels[int(pred_class)])