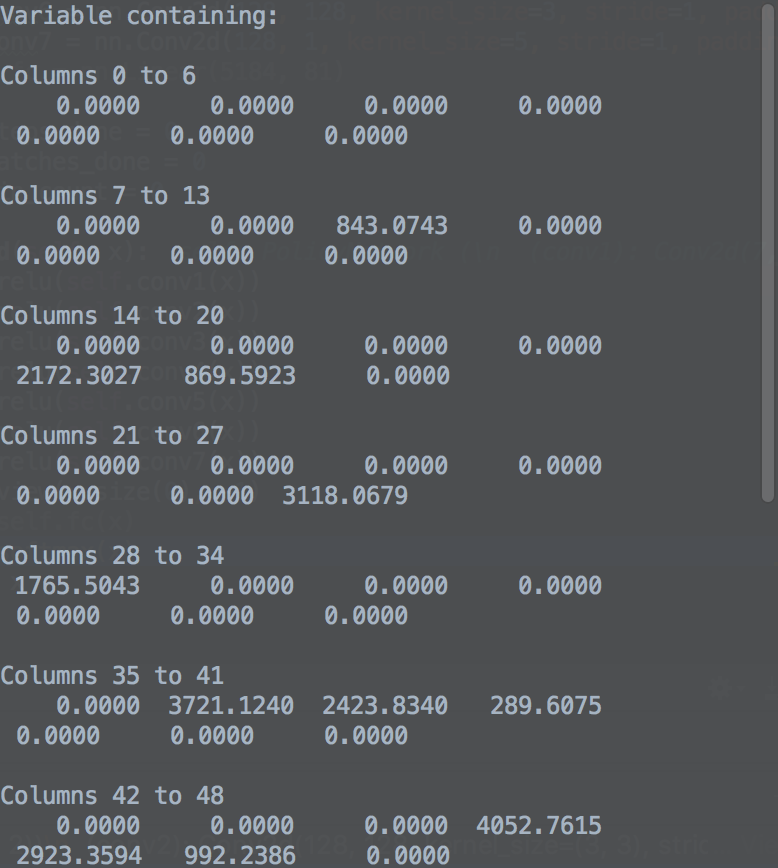
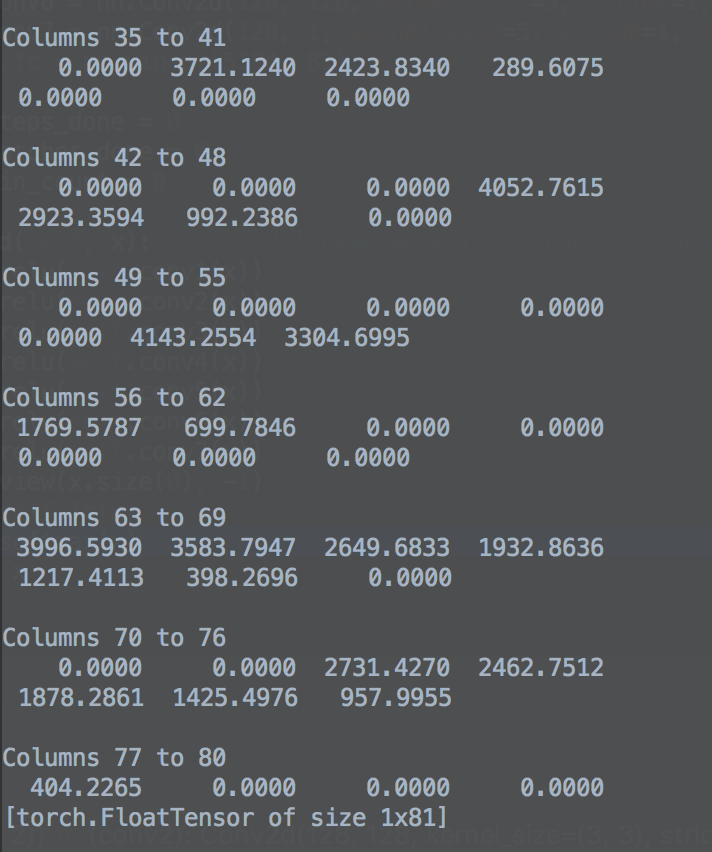
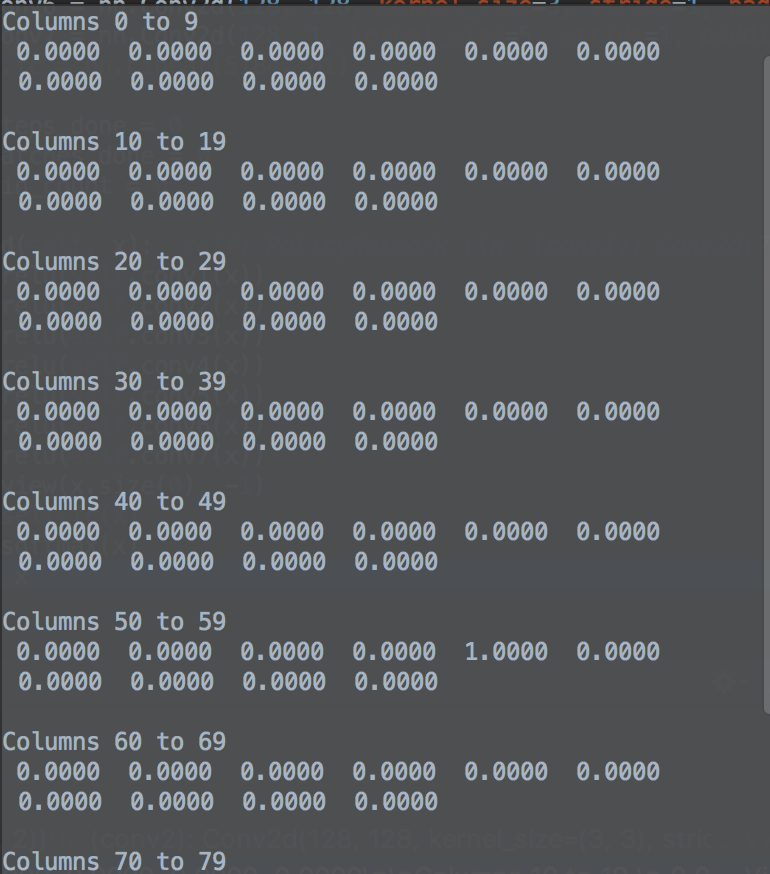
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.relu(self.conv6(x))
x = F.relu(self.conv7(x))
x = x.view(x.size(0), -1)
x = F.softmax(x)
return x
This is to be expected. exp(-20) is about 2e-9, so if your largest input to softmax is 20 larger (in absolute numbers) than the others, the softmax will be extremely spiked. (And the softmax is saturated, i.e. you have vanishing gradients, see e.g. http://eli.thegreenplace.net/2016/the-softmax-function-and-its-derivative/ for lots of details.)
The canonical way to overcome this is to use a temperature parameter to divide the inputs (see e.g. https://en.wikipedia.org/wiki/Softmax_function#Reinforcement_learning ), for your example, the maximal difference seems to be ~150, so you could try an initial temperature of ~200 to get several non-zero probabilities.