I have around 4000 .npy files which contain two different images namely ‘R’ & ‘L’. I also have another data .csv file which contain list of data ID,SIDE,Lable.I used these two files(npy,csv) to process my custom dataset using the referencetutorial.My aim is image classification using CNN.
here is my code
root_dirA= '/home/fatema/Downloads/homework/datasetA/p26crops/'
csvroot = '/home/fatema/Downloads/homework/datafile.csv'
#read the csv file
classfile =pd.read_csv(csvroot)
# remove the NA value from the file
df = classfile.dropna(how='any',axis=0)
# Dropout the duplicates of number from ID and Side
data = df.drop_duplicates(subset=['ID', 'SIDE'])
#reset the index
Data = data.reset_index(drop=True)
#make a class for data
class AOIDataset(Dataset):
def __init__(self, csv_file,root_dir, transform=None):
# self.data = pd.read_csv(csv_file, header=None)
self.data = csv_file
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self,idx):
img_name = os.path.join(self.root_dir,
self.data['ID'][idx])
patches, p_id = np.load(img_name)
img_class = self.data.iloc[idx,2]
side = self.data.iloc[idx,1]
if (self.data['SIDE'][idx,:1]==1):
# #if (self.data.iloc[idx,0]) ==1:
image = np.array(patches['R'].astype('uint8'), 'L') #[image['R':side]|image['L':side]]
else:
image = np.array(patches['L'].astype('uint8'), 'L')
if self.transform is not None:
image = self.transform(image)
sample = {'image': image, 'grade':img_class}
return sample
if __name__ == '__main__':
# Define transforms (1)
#trans = transforms.Compose([ transforms.ToTensor()])
# Call the dataset
train_data =AOIDataset(train_df,root_dirA)
here is my training function code
def train_model(epochs):
model.train() #set the model to training mode
for epoch in range(epochs):
losses = []
num_times=0
closs = 0
for i,batch in enumerate(train_loader,0):
image , grade = batch
image=image.unsqueeze(1).type(torch.FloatTensor)
prediction = model(image)
loss = costFunction(prediction,grade)
closs += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
#Track every 100th loss
if i%50 == 0:
losses.append(loss.item())
num_times = num_times + 1
#print every 1000th time
if i%50 == 0:
print('[%d %d] loss: %.4f'% (epoch+1,i+1,closs/50))
closs = 0
#Calculate the accuracy and save the model state
accuracy()
#Plot the graph of loss with iteration
plt.plot([i for i in range(num_times)],losses,label='epoch'+str(epoch))
plt.legend(loc=1,mode='expanded',shadow=True,ncol=2)
plt.show()
def accuracy():
model.eval() #set the model to evaluation mode
#Calculate the overall performance of the network
correctHits=0
total=0
accuracy=0
for batches in val_loader:
image,grade = batches
image=image.unsqueeze(1).type(torch.FloatTensor)
prediction = model(image)
_,prediction = torch.max(prediction.data,1) #returns max as well as its index
total += grade.size(0)
correctHits += (prediction==grade).sum().item()
accuracy = (correctHits/total)*100
print('Accuracy = '+str(accuracy))
if __name__ == '__main__':
train_model(1)
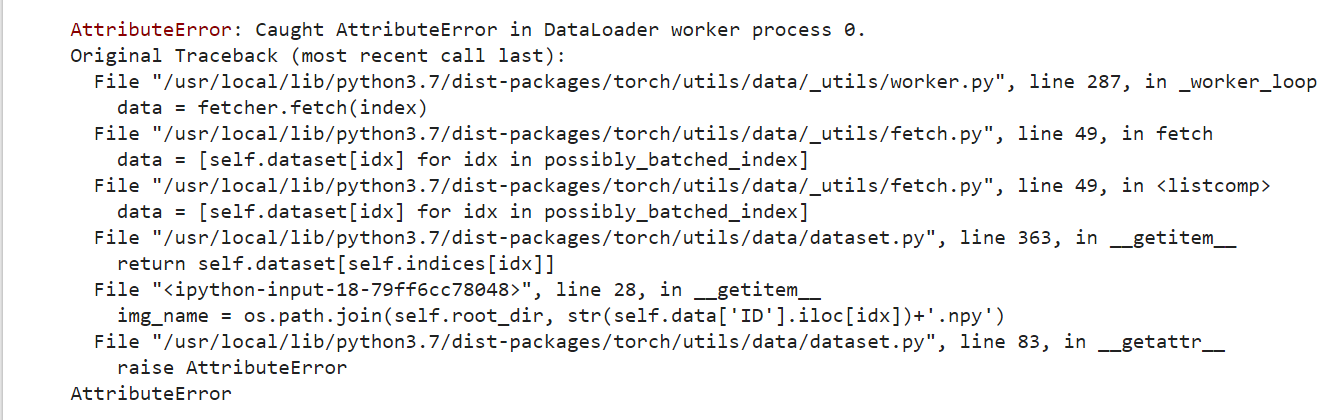
The error that I got is here
Traceback (most recent call last):
File “/home/fatema/miniconda3/lib/python3.6/site-packages/IPython/core/interactiveshell.py”, line 3325, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File “”, line 1, in
runfile(’/home/fatema/Downloads/practice1.py’, wdir=’/home/fatema/Downloads’)
File “/home/fatema/Downloads/pycharm-professional-2019.1.3/pycharm-2019.1.3/helpers/pydev/_pydev_bundle/pydev_umd.py”, line 197, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File “/home/fatema/Downloads/pycharm-professional-2019.1.3/pycharm-2019.1.3/helpers/pydev/_pydev_imps/_pydev_execfile.py”, line 18, in execfile
exec(compile(contents+"\n", file, ‘exec’), glob, loc)
File “/home/fatema/Downloads/practice1.py”, line 223, in
train_model(1)
File “/home/fatema/Downloads/practice1.py”, line 180, in train_model
for i,batch in enumerate(train_loader,0):
File “/home/fatema/miniconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 560, in next
batch = self.collate_fn([self.dataset[i] for i in indices])
File “/home/fatema/miniconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 560, in
batch = self.collate_fn([self.dataset[i] for i in indices])
File “/home/fatema/miniconda3/lib/python3.6/site-packages/torch/utils/data/dataset.py”, line 107, in getitem
return self.dataset[self.indices[idx]]
File “/home/fatema/Downloads/practice1.py”, line 64, in getitem
self.data[‘ID’][idx])
File “/home/fatema/miniconda3/lib/python3.6/posixpath.py”, line 94, in join
genericpath._check_arg_types(‘join’, a, *p)
File “/home/fatema/miniconda3/lib/python3.6/genericpath.py”, line 149, in _check_arg_types
(funcname, s.class.name)) from None
TypeError: join() argument must be str or bytes, not ‘int64’