Hi,
I am trying to train a MobileNet V1 model to perform action recognition on UCF-101, but the weight of every BatchNorm in the model ends up at just about the same value. On top of this, each value in a BatchNorm layer are approximately the same. The following as an example:
10.4.weight Parameter containing:
tensor([0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0772, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0772, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0772, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0772, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773,
0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773, 0.0773],
device='cuda:0')
As far as I can tell this is the cause of an issue I am facing where the model output is locked to a single class despite train and val loss both falling during training. The following image shows a few stats of training:
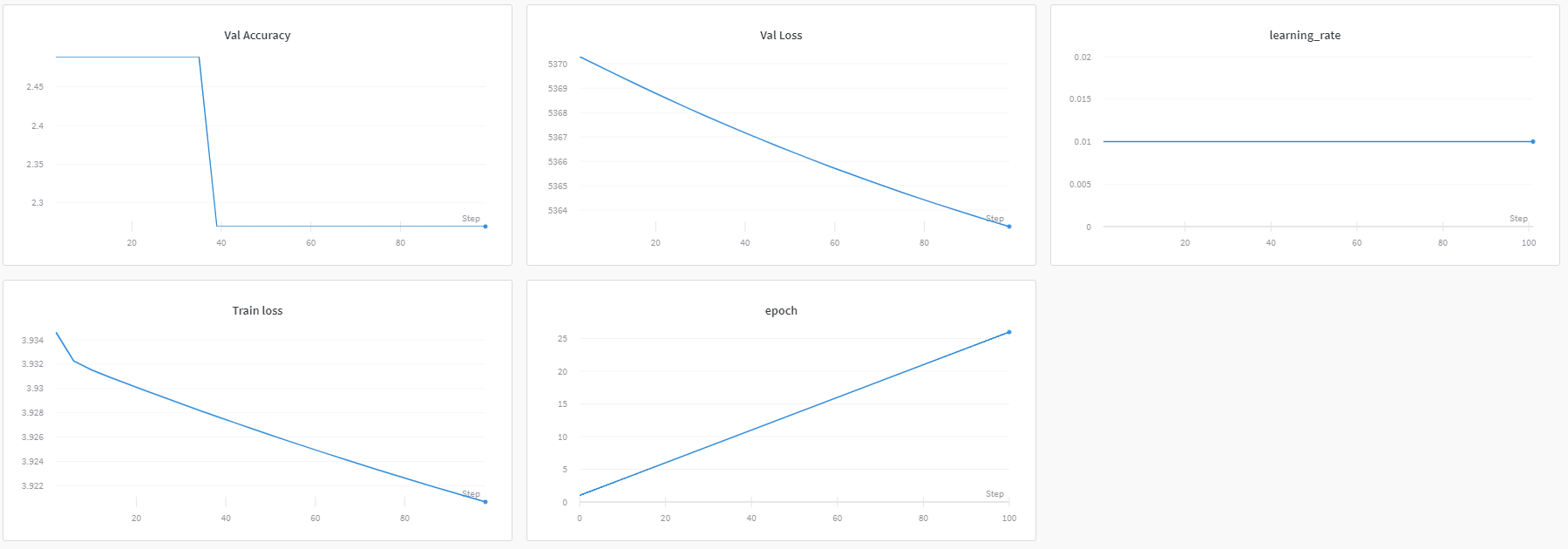
If I set affine=False then accuracy improves during training but as expected this takes time and it seems to flattened out at around 8%.
Is there anything that could cause BatchNorm to act like this? In case it is helpful I have included a simplified version of my code below (the final model will use both video and audio as a mel spectrogram whereas this example is just showing audio).
class MobileNetV1(nn.Module):
def __init__(self, dims, input_channels, embedding_size=1000):
self.dims = dims
super(MobileNetV1, self).__init__()
assert 1 <= dims <= 3
opt_conv = [None, nn.Conv1d, nn.Conv2d, nn.Conv3d]
opt_bn = [None, nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d]
opt_pool = [None, nn.AvgPool1d, nn.AvgPool2d, nn.AvgPool3d]
Conv = opt_conv[dims]
BatchNorm = opt_bn[dims]
self.AvgPool = opt_pool[dims]
def conv_bn(inp, oup, stride):
return nn.Sequential(
Conv(inp, oup, 3, stride, padding=1, bias=False),
BatchNorm(oup),
nn.ReLU(inplace=True))
def conv_dw(inp, oup, stride):
return nn.Sequential(
Conv(inp, inp, kernel_size=3, stride=stride, padding=1, groups=inp, bias=False),
BatchNorm(inp),
nn.ReLU(inplace=True),
Conv(inp, oup, kernel_size=1, stride=1, padding=0, bias=False),
BatchNorm(oup),
nn.ReLU(inplace=True))
self.features = nn.Sequential(
conv_bn(input_channels, 32, 2),
conv_dw(32, 64, 1),
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
)
self.fc = nn.Linear(1024, embedding_size)
def forward(self, x):
x = self.features(x)
avg_pool = self.AvgPool(x.data.size()[-self.dims:])
x = avg_pool(x).view(-1, 1024)
x = self.fc(x)
return x
class AudioClassifier(MobileNetV1):
def __init__(self, embedding_size=1000, train=True):
super().__init__(embedding_size=embedding_size, dims=2, input_channels=1)
self.classifier = nn.Linear(embedding_size, 51)
def forward(self, x):
x = super().forward(x)
x = self.classifier(nn.ReLU()(x))
return x
audioNet = mobilenets.AudioClassifier()
audioTrain(audioNet)
trainLoader = torch.utils.data.DataLoader(
dataset.AudioVideoDataset(root=dataLocation + "/train", **train_transforms),
batch_size=32, shuffle=True, **kwargs)
valLoader = torch.utils.data.DataLoader(
dataset.AudioVideoDataset(root=dataLocation + "/val", **val_transforms),
batch_size=64, shuffle=False, **kwargs)
optimizer = optim.SGD(audioNet.parameters(),
lr=0.01,
momentum=0.9,
dampening=0.9,
weight_decay=1e-3,
nesterov=False)
criterion = nn.CrossEntropyLoss()
def train(args, model, trainLoader, optimizer, criterion):
model.train() # switch to train mode
losses = []
for i, (audio, video, type, target, clip_id) in enumerate(trainLoader, 0):
# zero the parameter gradients
optimizer.zero_grad()
audioOut = model(audio)
loss = criterion(audioOut, target)
loss.backward()
losses.append(loss.item())
optimizer.step()
averageLoss = sum(losses) / len(losses)
return averageLoss
def test(args, model, valLoader, criterion):
model.eval() # switch to evaluate mode
losses = []
correct = 0
with torch.no_grad():
for i, (audio, video, type, target, clip_id) in enumerate(valLoader):
audioOut = model(audio)
loss = criterion(audioOut, target)
losses.append(loss.item())
pred = audioOut.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = 100. * correct / len(valLoader.dataset)
averageLoss = sum(losses) / len(losses)
return averageLoss
