I’m trying to process some videos by dividing each video into 4 clips(video length=40, clip length=10) and pass them through the model.
Here is the code:
feature_dim = 1024
N, C, T, H, W = video.shape # T=40
clip_pos = [0, 10, 20, 30]
# approach I
feature = torch.empty(N, 4, feature_dim)
for i in clip_pos:
feature[:, i] = some_model(video[:, :, i:i+10]) # N, feature_dim
# approach II
data_pack = torch.cat([video[:, :, i:i+10] for i in clip_pos]) # N*4, C, 10, H, W
output = some_model(data_pack) # N*4, feature_dim
feature = output.reshape(N, 4, feature_dim) # output.view(N, 4, feature_dim) lead to the same bad result
'''
code for training
'''
The approach I works fine, but since it uses for loop which is less efficient, I tried the approach II to feed forward all the data at once. However it does not perform well in training and I dont know why.
I guess there may be something tricky happened when performing concatenate & reshape on tensor that make gradients flow abnormal.
How can I modify approach II to make it work? And why do the 2 approaches lead to different results?
In [10]: a = torch.zeros(3, 1)
In [11]: b = torch.ones(3, 1)
In [12]: c = torch.stack([a, b])
In [13]: c.view(3, 2, 1)
Out[13]:
tensor([[[0.],
[0.]],
[[0.],
[1.]],
[[1.],
[1.]]])
You can see that you mixup the batch elements.
You want output.reshape(4, N, feature_dim).transpose(0, 1)
Oh, I see. Since the batch_size dim changes faster than the clip dim in concatenated tensor, the batch_size dim should be after the clip dim when reshaping.
Sorry to bother again. Last time I changed the code as suggested and did some experiment for comparison. However, there is still a gap of performance between 2 approaches which I couldn’t figure out why…
Here is the modified code:
feature_dim = 1024
N, C, T, H, W = video.shape # T=40
clip_pos = [0, 10, 20, 30]
# approach I
feature = torch.empty(N, 4, feature_dim)
for i in clip_pos:
feature[:, i] = some_model(video[:, :, i:i+10]) # N, feature_dim
# approach II
data_pack = torch.cat([video[:, :, i:i+10] for i in clip_pos]) # N*4, C, 10, H, W
output = some_model(data_pack) # N*4, feature_dim
feature = output.reshape(4, N, feature_dim).transpose(0, 1)
'''
code for training
'''
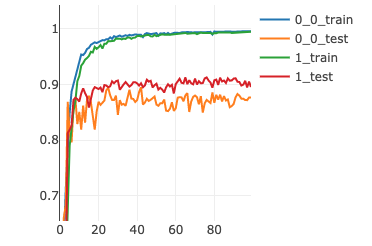
And Here is the training&testing curve(The higher the better. The red&green curve corresponds to approach I)
It seems unreasonable that 2 approaches which did exactly the same thing lead to different results. Or is my modified code still wrong?
Hope for your reply!
And I thought that with fixed random seed, the 2 approaches should produce the same result. But turns out that it’s not the case.
But what should the randomness come from if I have already fixed the seed?
The problem is that with float numbers, if you compute two things in two different way, you can end up with slightly different values. When you do gradient descent, these small differences are amplified and you get completely different networks.
You should try different random seeds to see what happens.