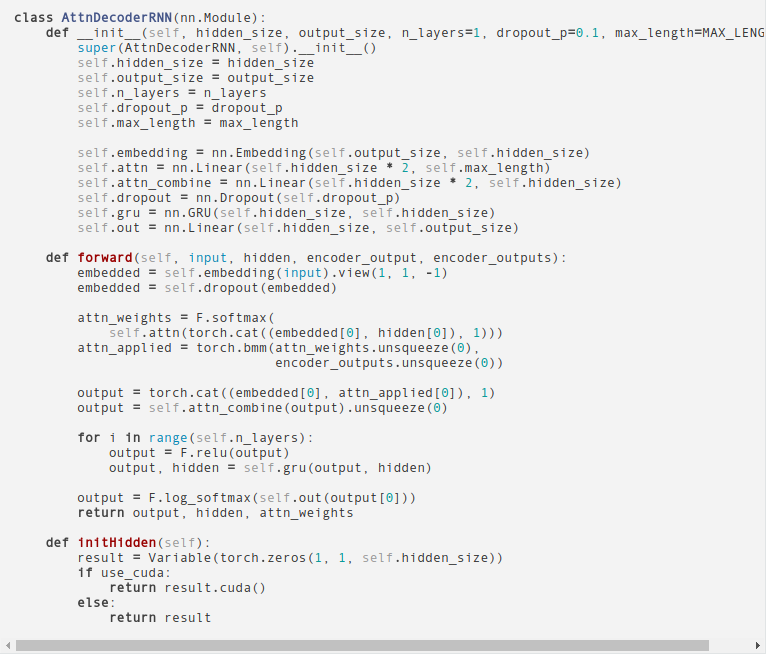
I am learning attention mechanism through reading official tutorial ‘Translation with a Sequence to Sequence Network and Attention’
but I think there is something wrong about implementation of attention decoder:
we can find that attention weights are calculated by code below:
attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)))
however,the dimention of hidden is (num_layers * num_directions, batch, hidden_size)
while the dimention of embedded is (batch, seq_len, embedding_dim) or (seq_len, batch, embedding_dim)
Obviously seq_len is usually not equal with num_layers * num_directions , so it is reasonable to concatenate hidden and embedded?
I am a beginner of NLP and hope that someone who understand the tutorial can explain the reason why they concatenate hidden and embedded, Thank you!
I am late but for other beginners like myself I’ll try to answer this.
Let’s see each component individually:
- Embedding matrix: The dimension of
embedded is (seq_len, batch, embedding_dim). Important thing to note in this tutorial is that we are passing input one at a time to network i.e input will be “he” then “is” then “painting” so on rather than “he is painting” in one go. This means seq_len will always be 1. So embedded will be of shape (1, batch, embedding_dim) and hence embedded[0] will be of shape (batch, embedding_dim).
- Hidden weights: the dimension of hidden is
(num_layers * num_directions, batch, hidden_size). For this tutorial num_layers=1 and num_directions=1 so the dimension becomes (1 * 1, batch, hidden_size). So hidden[0] becomes (batch, hidden_size)
From above to if we concatenate embedded[0] (batch, embedding_dim) and hidden[0] (batch, hidden_size) along dim=1 we safely get tensor of size (batch, hidden_size + embedding_dim) for each time step of the input.
Hopefully it Helps!