Hey, guys
I trained a image segmentation model and want to do inference using libtorch. The model predict a mask with a input image.
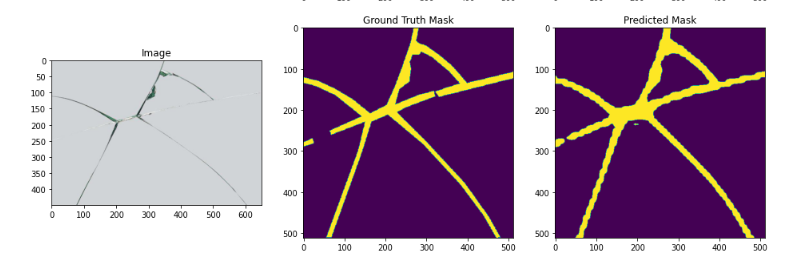
I traced the model for later C++ usage.
#define CV_8UC3 CV_MAKETYPE(CV_8U,3)
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
#include<opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/types_c.h>
#include <cuda.h>
#include <cuda_runtime.h>
using namespace cv;
using namespace std;
int main() {
std::string model_path = "D:/project/WDD/model_cpu.pt";
std::string image_path = "D:/data/glass_crack/converted/84/img.png";
torch::jit::script::Module model = torch::jit::load(model_path);
assert(module != nullptr);
std::cout << "load model sucessfully.\n";
//load img and normalize
Mat img = imread(image_path, 1);
cv::cvtColor(img, img, CV_BGR2RGB);
if (img.empty())
{
printf("could not show image...");
return -1;
}
cv::Mat img_float;
img.convertTo(img_float, CV_32FC3, 1.0f / 255.0f);
auto tensor_image = torch::from_blob(img_float.data, { 1, img.cols, img.rows, 3 });
tensor_image = tensor_image.permute({ 0, 3, 1, 2 });
//normalize
tensor_image[0][0] = tensor_image[0][0].sub(0.485).div(0.229);
tensor_image[0][1] = tensor_image[0][1].sub(0.456).div(0.224);
tensor_image[0][2] = tensor_image[0][2].sub(0.406).div(0.225);
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(tensor_image);
// Execute the model and turn its output into a tensor.
at::Tensor out_tensor = model.forward(inputs).toTensor();
// convert result to CV mat and save
out_tensor = out_tensor.squeeze().detach();
out_tensor = out_tensor.mul(255).clamp(0, 255).to(torch::kU8);
std::cout << out_tensor.sizes() << '\n';
cv::Mat resultImg(img.rows, img.cols, CV_8UC3);
std::memcpy((void*)resultImg.data, out_tensor.data_ptr(), sizeof(torch::kU8) * out_tensor.numel());
imwrite("landscape_output.jpg", resultImg);
std::cout << "Done!\n";
while (1);
}
it loaded model and did forward sucessfully, however, the problem is the output. The output:
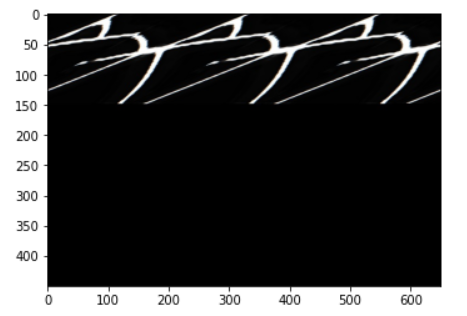
the output is not as expected, totally nonsense…
can someone help?


