I want to do document classification using hierarchical lstm described in http://aclweb.org/anthology/N/N16/N16-1174.pdf, I don’t know how to prepare data for this task. Could anybody help me?
Each document is stored in a separate file. I want to use sentence level RNN to get sentence level representation, which will be sent to document level RNN to get the document level representation. I don’t know how to process data for this task using torchtext. Could anybody help me?
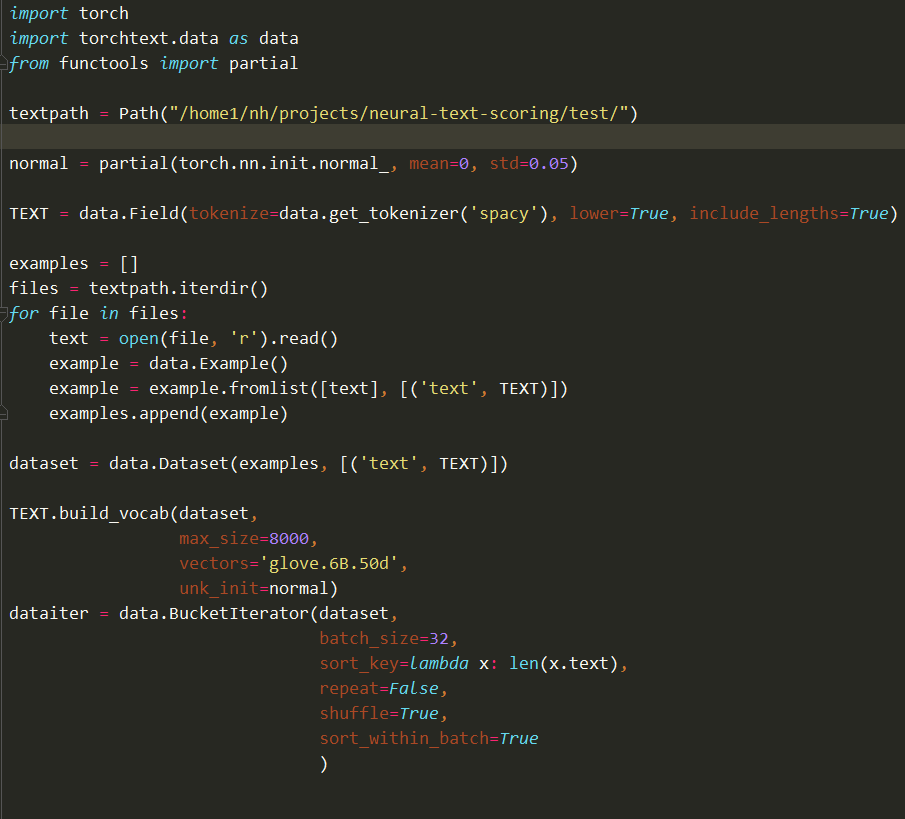
I know how to process data using the whole document. But when it comes to the hierarchical level preprocessing, it stucks me. My code for the whole document preprocessing is as follows: