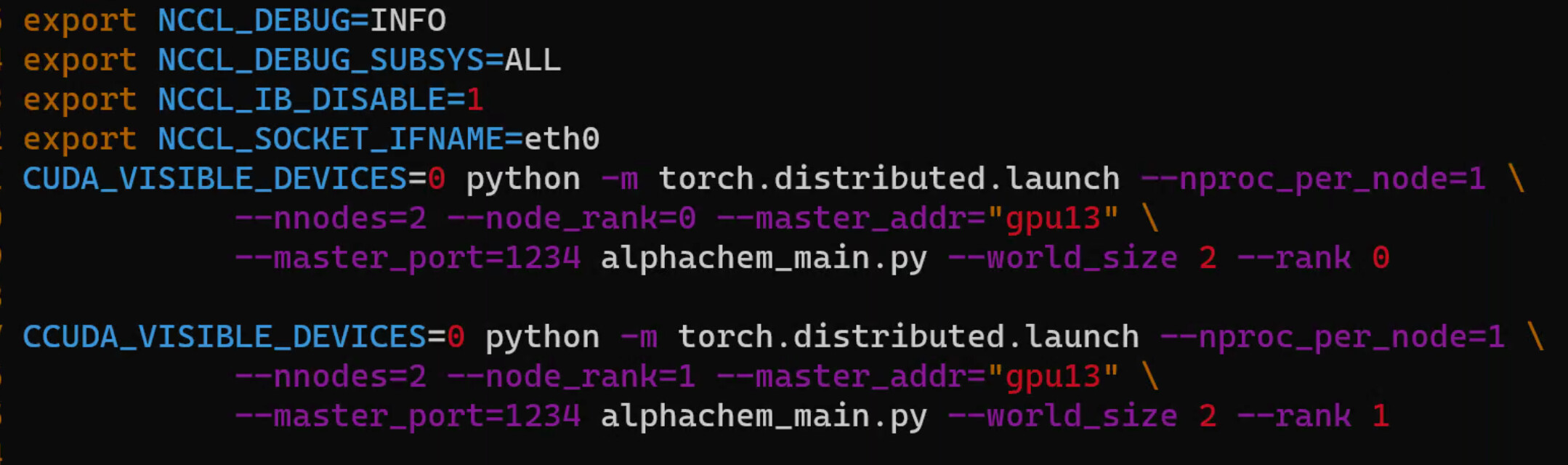
I trained my model in two nodes, and then it hangs up in initiation.

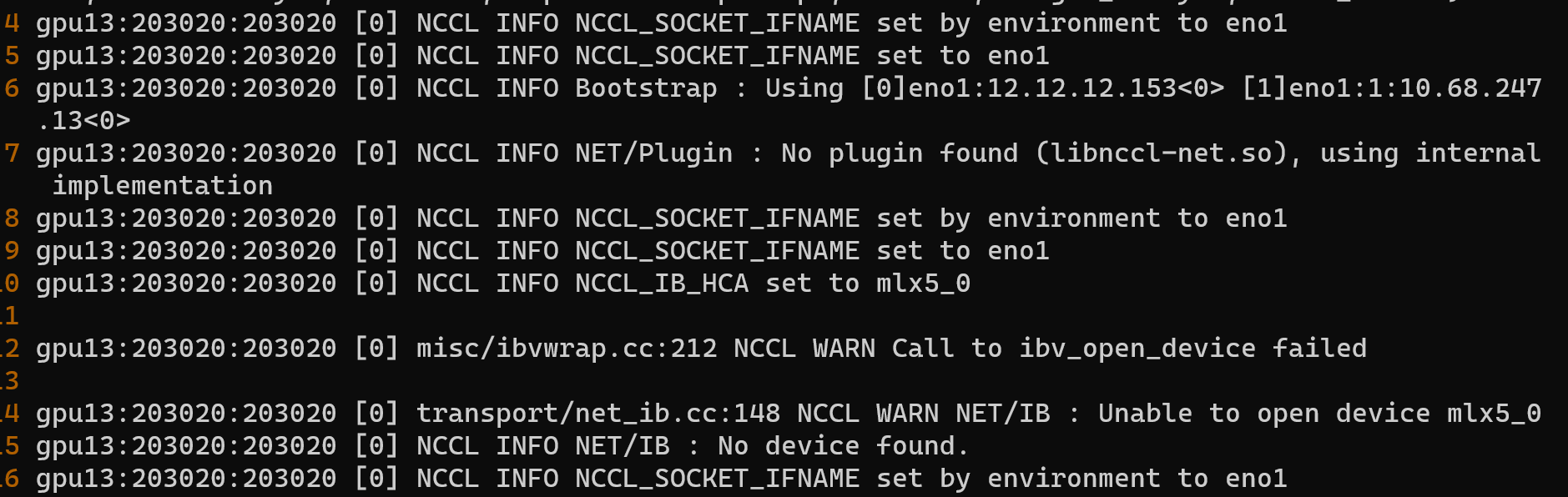
then I add NCCL_DEBUG=INFO and NCCL_DEBUG_SUBSYS=all to see what’s going on, but there is no output file.
I trained my model in two nodes, and then it hangs up in initiation.
Was there any error message? Does it behave differently if you replace gpu10 with its IP address?
then I add NCCL_DEBUG=INFO and NCCL_DEBUG_SUBSYS=all to see what’s going on, but there is no output file.
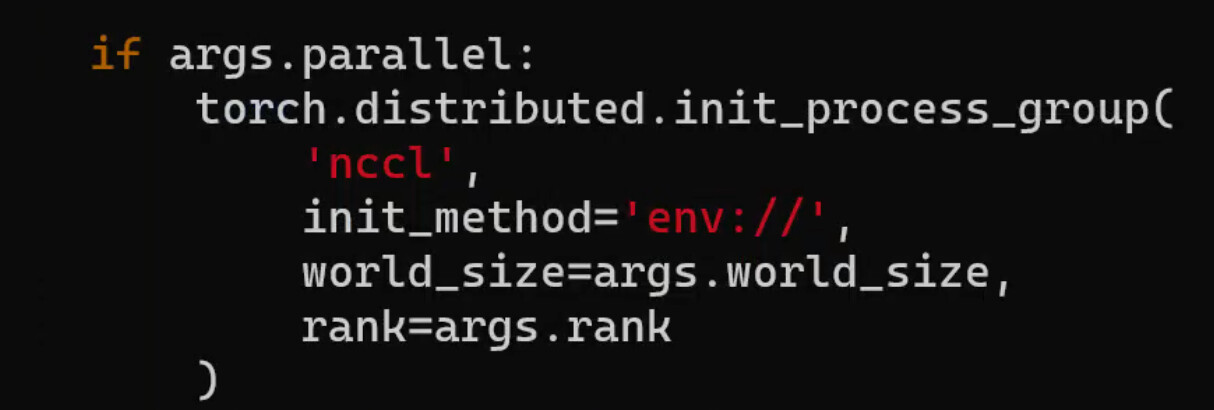
It’s possible that init_process_group failed at rendezvous stage (process ip/port discovery using the master as a leader), so that it has not reached NCCL code yet.
no differences. and it just remind me of connect() time out. But when I trained it on a single node with 2 gpus using CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 alphachem_main.py, it works well.
This probably means the two machines cannot talk to each other using the given configuration. Have you tried setting NCCL_SOCKET_IFNAME to point to the correct NIC?