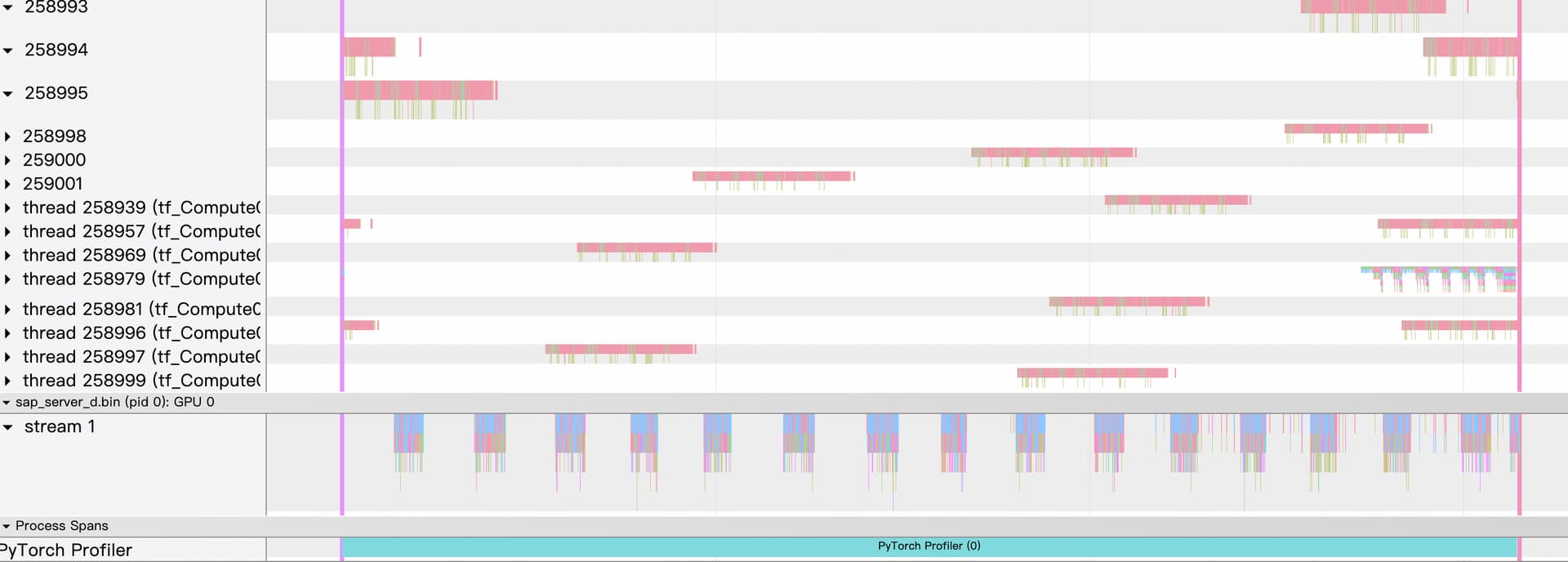
I am trying to build a server which process streaming input.
I should load model weight once and handle multiple inputs in separate threads.
Now I want to profile only one thread that handle with just one query with the profiler kineto.
However, my test shows that profiler kineto will record the events of all threads. Is there any chance to make the profiler kineto thread local just like profile legacy?
Downside is the test code:
TEST_F(ProfilerTest, testMultiThreads) {
torch::inductor::AOTIModelPackageLoader loader("xxxx.pt2");
torch::inductor::AOTIModelContainerRunner* runner = loader.get_runner();
auto inference_worker_with_profiler = [&runner]() {
torch::profiler::impl::ProfilerConfig config_ = torch::profiler::impl::ProfilerConfig(torch::profiler::impl::ProfilerState::KINETO);
std::set<torch::profiler::impl::ActivityType> activities_{torch::profiler::impl::ActivityType::CUDA, torch::profiler::impl::ActivityType::CPU};
torch::autograd::profiler::prepareProfiler(config_, activities_);
torch::autograd::profiler::enableProfiler(config_, activities_);
std::vector<torch::Tensor> inputs = {torch::rand({300, 1024}, torch::kFloat32).to(torch::kCUDA)};
std::vector<torch::Tensor> outputs = runner->run(inputs);
std::unique_ptr<torch::autograd::profiler::ProfilerResult> res = torch::autograd::profiler::disableProfiler();
std::string file_name = "xxx.json";
res->save(file_name);
};
auto inference_worker_without_profiler = [&runner]() {
std::vector<torch::Tensor> inputs = {torch::rand({300, 1024}, torch::kFloat32).to(torch::kCUDA)};
std::vector<torch::Tensor> outputs = runner->run(inputs);
};
std::thread thread_a(inference_worker_with_profiler);
std::thread thread_b(inference_worker_without_profiler);
std::thread thread_c(inference_worker_without_profiler);
std::thread thread_d(inference_worker_without_profiler);
std::thread thread_e(inference_worker_without_profiler);
thread_a.join();
thread_b.join();
thread_c.join();
thread_d.join();
thread_e.join();
}
The profile result is similar as bellow: