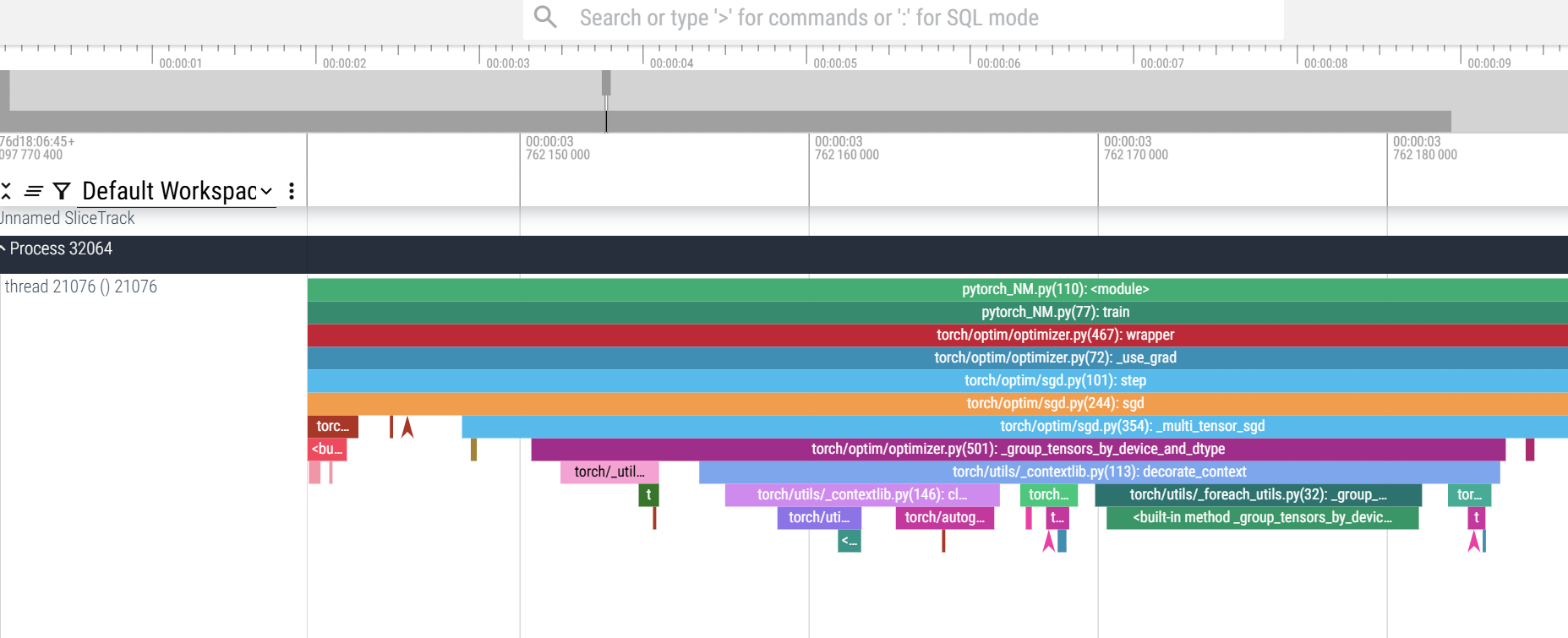
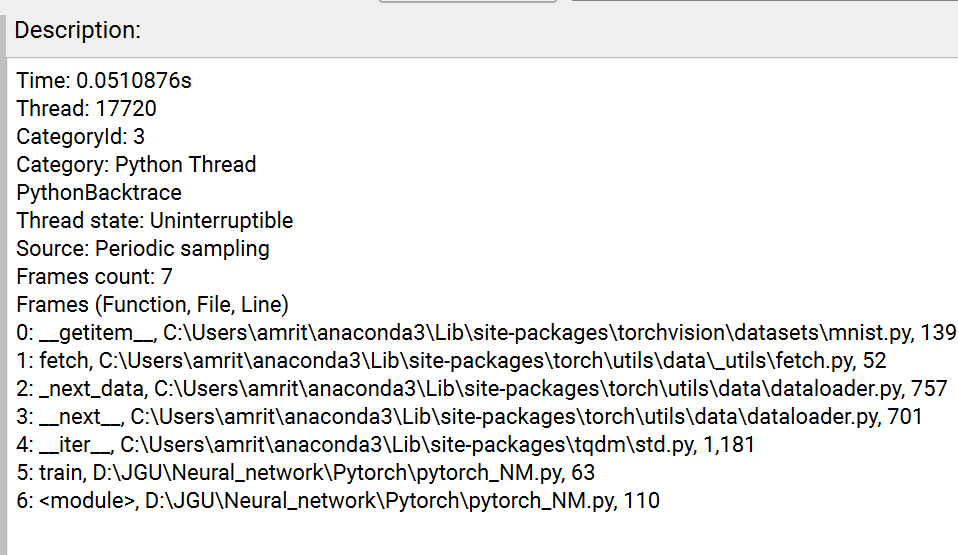
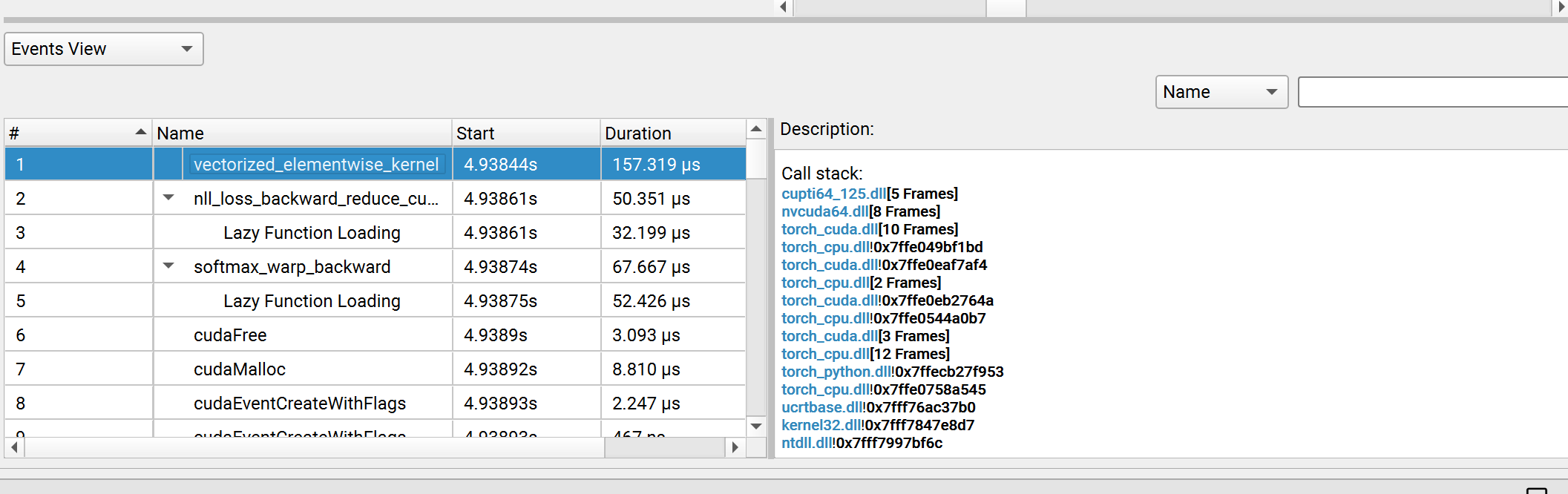
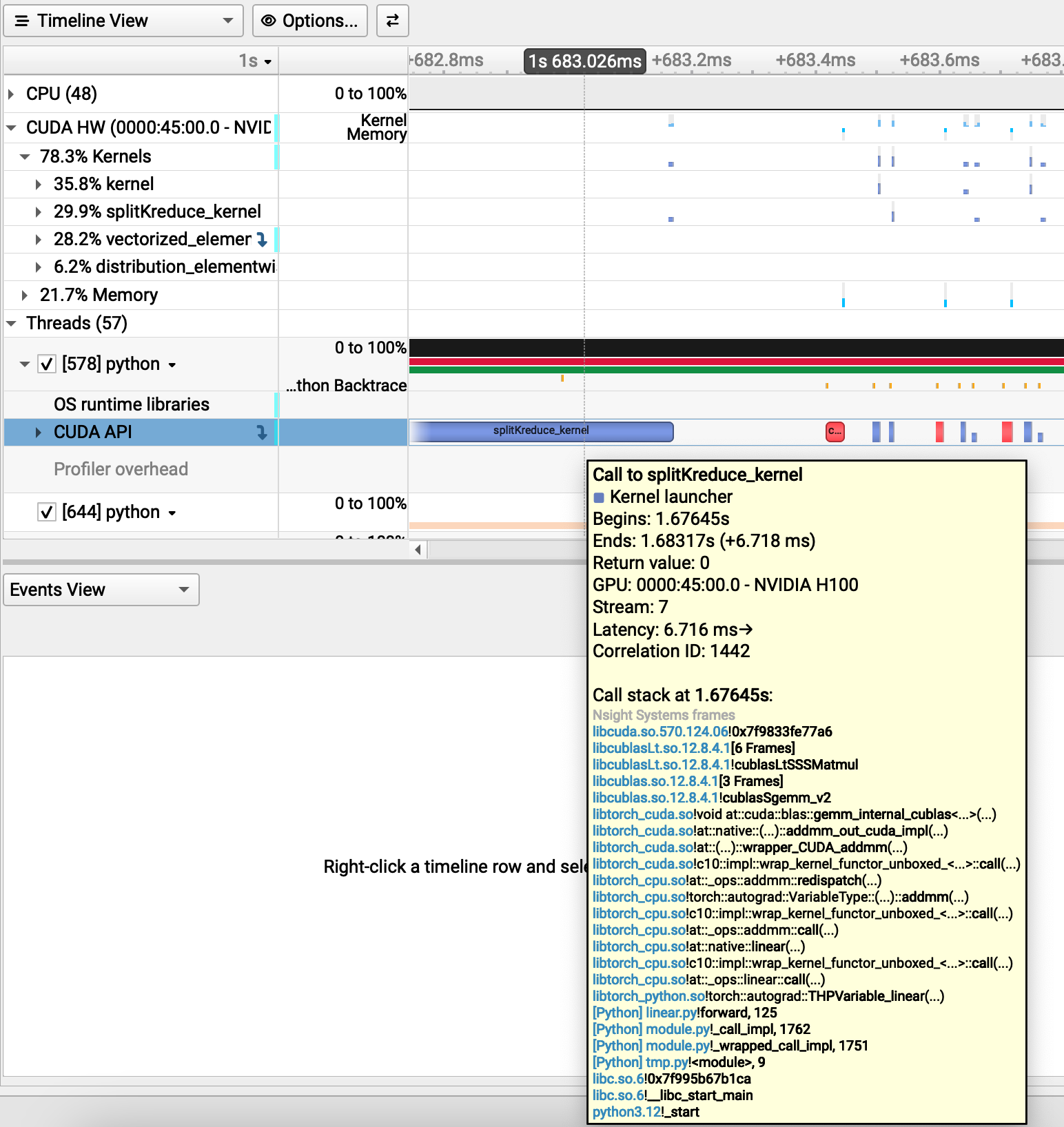
I was using nsys version 2024.2 eariler, and I updated to version 2025.1
using nsys --version , the version is
NVIDIA Nsight Systems version 2025.2.1.130-252135690618v0
and when I again used the nsys profile --help these are the full list of the commands found.
usage: nsys profile [<args>] [application] [<application args>]
--auto-report-name=
Possible values are 'true' or 'false'.
Derive report file name from collected data, uses details of profiled graphics application.
Format: [Process Name][GPU Name][Window Resolution][Graphics API] Timestamp.nsys-rep
If true, automatically generate report file names.
Default is 'false'. Application scope.
-b, --backtrace=
Possible values are 'auto', or 'none'.
Select the backtrace method to use while sampling.
Select 'none' to disable backtrace collection.
Default is 'auto'.
-c, --capture-range=
Possible values are none, cudaProfilerApi, nvtx, hotkey.
When '-c cudaProfilerApi' is used, profiling will start only when cudaProfilerStart API is
invoked in the application.
When '-c nvtx' is used, profiling will start only when the specified NVTX range is
started in the application.
When '-c hotkey' is used, profiling will start only when the hotkey
set by '--hotkey-capture' is pressed in the application. This works for graphic apps only.
Note that you must enable CUDA or NVTX tracing of the target application
for '-c cudaProfilerApi' or '-c nvtx' to work.
When '-capture-range none' is used, cudaProfilerStart/Stop APIs and hotkey will
be ignored and NVTX ranges will be ignored as collection start/stop triggers.
Default is none.
--capture-range-end=
Possible values are 'none', 'stop', 'stop-shutdown', 'repeat[:N]' or 'repeat-shutdown:N'.
Specify the desired behavior when a capture range ends. Applicable only when used along
with --capture-range option.
If 'none', capture range end will be ignored.
If 'stop', collection will stop at capture range end. Any subsequent capture ranges will be
ignored. Target app will continue running.
If 'stop-shutdown', collection will stop at capture range end and session will be shutdown.
If 'repeat[:N]', collection will stop at capture range end and subsequent capture ranges
will trigger more collections.
Use the optional ':N' to specify max number of capture ranges to be honored. Any subsequent
capture ranges will be ignored once N capture ranges are collected.
If 'repeat-shutdown:N', same behavior as 'repeat:N' but session will be shutdown after N
ranges.
For 'stop-shutdown' and 'repeat-shutdown:N', use --kill option to specify whether target
app should be terminated when shutting down session.
Default is 'stop-shutdown'.
--command-file=
Open a file that contains nsys switches and parse the switches. Note that
command line switches will override switches found in the command-file.
--cpuctxsw=
Possible values are 'process-tree', 'system-wide', or 'none'.
Trace OS thread scheduling activity. Select 'none' to disable tracing CPU context switches.
'process-tree' or 'system-wide' requires administrative privileges.
If a target app is specified, the default is 'process-tree'.
Otherwise the default is 'system-wide'.
--cuda-event-trace=
Possible values are 'auto', 'true' or 'false'.
Trace CUDA Event completion on the device side, and get better correlation
support among CUDA Event APIs. Applicable only when CUDA tracing is enabled.
Note that 'CUDA Event' refers to the synchronization mechanism (cudaEventRecord,
cudaStreamWaitEvent etc.).
Enabling this feature may increase runtime overhead and the likelihood of false
dependencies across CUDA Streams, similar to CUDA Event's timing functionality
when cudaEventDisableTiming is not disabled.
'auto' will automatically turn off the trace if a target process has
CUDA_DEVICE_MAX_CONNECTIONS set to 1.
This switch requires CUDA driver 12.8 or higher.
Default is 'false'. Application scope.
--cuda-flush-interval=
Set the interval, in milliseconds, when buffered CUDA data is automatically saved to
storage. CUDA data buffer saves may cause profiler overhead. Buffer save behavior can be
controlled with this switch.
If the CUDA flush interval is set to 0 on systems running CUDA 11.0 or newer, buffers are
saved when they fill. If a flush interval is set to a non-zero value on such systems,
buffers are saved only when the flush interval expires. If a flush interval is set and the
profiler runs out of available buffers before the flush interval expires, additional buffers
will be allocated as needed. In this case, setting a flush interval can reduce buffer
save overhead but increase memory use by the profiler.
If the flush interval is set to 0 on systems running older versions of CUDA,
buffers are saved at the end of the collection. If the profiler runs out of available
buffers, additional buffers are allocated as needed. If a flush interval is set to a
non-zero value on such systems, buffers are saved when the flush interval expires.
A cuCtxSynchronize call may be inserted into the workflow before the buffers
are saved which will cause application overhead. In this case, setting a flush interval
can reduce memory use by the profiler but may increase save overhead.
Default is '0'. Application scope.
--cuda-graph-trace=<granularity>[:<launch origin>]
Set the granularity and launch origin for CUDA graph trace.
Applicable only when CUDA tracing is enabled.
Possible values for <granularity> are 'graph' or 'node'.
If 'graph' is selected, CUDA graphs will be traced as a whole and node
activities will not be collected. This can reduce overhead to the minimal,
but requires CUDA driver version 11.7 or higher.
If 'node' is selected, node activities will be collected, but CUDA graphs
will not be traced as a whole. This may cause significant runtime overhead.
If CUDA driver version is 11.7 or higher, default is 'graph', otherwise default is 'node'.
Possible values for <launch origin> are 'host-only' or 'host-and-device'.
If 'host-only' is selected, only CUDA graphs launched from host codes will be traced.
If 'host-and-device' is selected, CUDA graphs launched from host codes and device codes
will both be traced. This is only supported when the granularity is set to 'graph' and
the CUDA driver is version 12.3 or higher. This may cause significant runtime overhead.
If granularity is set to 'graph' and the CUDA driver version is 12.3 or higher,
the default is 'host-and-device', otherwise default is 'host-only'.'.
Application scope.
--cuda-memory-usage=
Possible values are 'true' or 'false'.
Track the GPU memory usage. Applicable only when CUDA tracing is enabled.
This feature may cause significant runtime overhead.
Default is 'false'. Application scope.
-d, --duration=
Collection duration in seconds.
Default is 0 seconds.
--dask=
Possible values are 'functions-trace' or 'none'.
'functions-trace' implies '--python-functions-trace=C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\PythonFunctionsTrace/dask.json',
and will rename relevant threads to 'Dask Worker' and 'Dask Scheduler'.
Default is 'none'.
Implies '--trace=nvtx'.
--debug-symbols=
Specify the paths to directories with symbol files.
Multiple directories can be selected, separated by a colon (':') only (no spaces).
--duration-frames=
Stop the recording session after this many frames have been captured.
Minimum supported frame is '60'.
Note when it is selected cannot include any other stop options.
If not specified the default is disabled. Application scope.
--dx-force-declare-adapter-removal-support=
Possible values are 'true' or 'false'.
The Nsight Systems trace initialization involves creating a D3D
device and discarding it. Enabling this flag makes a call to
DXGIDeclareAdapterRemovalSupport() before device creation.
Default is 'false'.
--dx12-gpu-workload=
Possible values are 'individual', 'batch', 'none', 'true' or 'false'.
If individual or true, trace each DX12 workload's GPU activity individually.
If batch, trace DX12 workloads' GPU activity in ExecuteCommandLists call batches.
If none or false, do not trace DX12 workloads' GPU activity.
Note that this switch is applicable only when --trace=dx12 is specified.
Default is 'individual'. Application scope.
--dx12-wait-calls=
Possible values are 'true' or 'false'.
If true, trace wait calls that block on fences for DX12.
Note that this switch is applicable only when --trace=dx12 is specified.
Default is 'false'. Application scope.
-e, --env-var=
Set environment variable(s) for application process to be launched.
Environment variable(s) should be defined as 'A=B'.
Multiple environment variables can be specified as 'A=B,C=D'
(Experimental) --enable=<plugin_name>[,arg1,arg2,...]
Use the specified plugin.
The option can be specified multiple times to enable multiple plugins.
Plugin arguments are separated by commas only (no spaces).
Commas can be escaped with a backslash '\'. The backslash itself can be
escaped by another backslash '\\'. To include spaces in an argument,
enclose the argument in double quotes '"'.
To list all available plugins, use '--enable=help' command.
--etw-provider=
Add custom ETW trace provider(s).
Possible values are '<name>,<guid>' or JSON configuration file path.
If you want to specify more attributes than Name and GUID, provide a JSON
configuration file.
Find 'C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\etw_providers_template.json'
as a template.
This switch can be used multiple times to add multiple providers.
--export=<format>[,<format>...]
Possible formats are: none sqlite hdf text json arrow arrowdir parquetdir
Create additional output file(s) based on the data collected.
If 'none' is selected, no additional files are created.
Default is 'none'. This option can be given more than once.
-f, --force-overwrite=
Possible values are 'true' or 'false'.
If true, overwrite all existing result files with same output filename
(QDSTRM, nsys-rep, SQLITE, HDF, TEXT, JSON, ARROW, ARROWDIR, PARQUETDIR).
Default is 'false'.
--flush-on-cudaprofilerstop=
If set to 'true', any call to cudaProfilerStop() will
cause the CUDA trace buffers to be flushed. Note that the CUDA trace
buffers will be flushed when the collection ends, irrespective of the
value of this switch. Default value is 'true'.
--gpu-metrics-devices=
Collect GPU Metrics from the specified devices.
Possible values are:
'none', 'cuda-visible', 'all',
or a comma separated list of GPU IDs reported by '--gpu-metrics-devices=help' switch.
Default is 'none'. System scope.
--gpu-metrics-frequency=
Specify the sampling frequency for GPU Metrics.
Minimum supported frequency is '10' (Hz).
Maximum supported frequency is '200000' (Hz).
Default is '10000'. System scope.
--gpu-metrics-set=
Specify the metric set for GPU Metrics.
The option argument must be one of aliases reported by '--gpu-metrics-set=help' switch.
Default is the first metric set that supports all selected GPU. System scope.
--gpu-video-device=
Collect GPU video accelerator traces from specified devices.
The argument must be 'none' or one or more GPU IDs reported by '--gpu-video-device=help'.
Default is 'none'. System scope.
--gpuctxsw=
Possible values are 'true' or 'false'.
Trace GPU context switches. This switch requires CUDA driver r435.17 or higher.
Requires root privileges.
Default is 'false'. System scope.
-h, --help=[<tag>]
Print the command's help menu. The switch can take one optional
argument that will be used as a tag. If a tag is provided, only options
relevant to the tag will be printed.
The available help menu tags for this command are:
app, application, backtrace, capture, cli, command, cuda, driver, dx, dx12,
env, environment, etw, events, export, file, filter, frame, gpu, hotkey,
injection, interactive, interrupt, isr, log, logs, memory, nvtx, opengl,
output, profile, profiling, range, report, sample, sampling, session, stats,
switch, symbol, symbols, trace, vulkan, wait, wddm, and windows.
--hotkey-capture=
Possible values are `F1` to `F12`.
Note that on Windows platforms `F10` is not supported.
Hotkey to trigger the profiling session.
Note that this switch is applicable only when --capture-range=hotkey is specified.
Default is `F12`.
--injection-use-detours=
Possible values are 'true' or 'false'.
Use detours for injection.
Equivalent to setting the --system-wide option to the
inverse value.
Default is 'true'.
--isr=
Possible values are 'true' or 'false'.
Trace Interrupt Service Routines (ISRs) and Deferred Procedure Calls (DPCs).
Requires administrative privileges. Available only on Windows devices.
Default is 'false'.
--kill=
Possible values are 'true' or 'false'.
Terminate the target application when ending/shutting down profiling
session.
Default is 'true', so the application is terminated when profiling session ends/is
shutdown.
-n, --inherit-environment=
Possible values are 'true' or 'false'.
Inherit environment variables.
Default is 'true'.
--nvtx-domain-[include|exclude]=
Possible values are a comma-separated list of NVTX domains.
Choose the include or exclude option to (only) include or exclude the specified domains. The
options are mutually exclusive. 'default' filters the NVTX default domain. A domain with
this name and commas in a domain name have to be escaped with '\'.
Note that both switches are applicable only when --trace=nvtx is specified.
-o, --output=
Output report filename.
Any %q{ENV_VAR} pattern in the filename will be substituted with the value of the
environment variable.
Any %h pattern in the filename will be substituted with the hostname of the system.
Any %p pattern in the filename will be substituted with the PID of the target process or
the PID of the root process if there is a process tree.
Any %n pattern in the filename will be substituted with the minimal positive integer that is
not already occupied.
Any %% pattern in the filename will be substituted with %.
Default is 'report%n'.
--opengl-gpu-workload=
Possible values are 'true' or 'false'.
If true, trace the OpenGL workload's GPU activity.
Note that this switch is applicable only when --trace=opengl is specified.
Default is 'true'. Application scope.
-p, --nvtx-capture=
Possible values are: `range@domain' to specify both range and domain,
`range' to specify range in default domain, `range@*' to specify a range in any domain.
NVTX message and domain to trigger the profiling session.
'@' can be escaped with backslash '\'.
Note that this switch is applicable only when --capture-range=nvtx is specified.
--python-functions-trace=
Specify the path to the json file containing the requested
Python functions to trace.
Note that nvtx package must be installed on the target Python.
See 'C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\PythonFunctionsTrace/annotations.json' as an example.
For PyTorch application, see predefined annotations at 'C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\PythonFunctionsTrace/pytorch.json'.
For Dask application, see predefined annotations at 'C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\PythonFunctionsTrace/dask.json'.
--python-sampling=
Possible values are 'true' or 'false'.
Sample Python backtrace.
Default is 'false'.
Note: This feature provides meaningful backtraces for Python processes.
When profiling Python-only workflows, consider disabling the CPU sampling option to reduce overhead.
--python-sampling-frequency=
Specify Python sampling frequency.
Minimum supported frequency is '1' (Hz).
Maximum supported frequency is '2000' (Hz).
Default is '1000' (Hz).
--pytorch=
Possible values are 'autograd-nvtx', 'autograd-shapes-nvtx', 'functions-trace' or 'none'.
If 'autograd-nvtx' is used, nsys will call
torch.autograd.profiler.emit_nvtx(record_shapes=False)
when pytorch is imported.
If 'autograd-shapes-nvtx' is used, nsys will call
torch.autograd.profiler.emit_nvtx(record_shapes=True)
when pytorch is imported.
'functions-trace' is an alias to '--python-functions-trace=C:\Program Files\NVIDIA Corporation\Nsight Systems 2025.2.1\target-windows-x64\PythonFunctionsTrace/pytorch.json'.
The 'autograd-nvtx' and 'autograd-shapes-nvtx' options can be combined
with the 'functions-trace' option by adding them separated by a comma.
Default is 'none'.
Implies '--trace=nvtx'.
--reflex-events=
Possible values are 'true' or 'false'.
If true, collect Reflex SDK ETW events.
Default is 'false'. System scope.
--resolve-symbols=
Possible values are 'true' or 'false'.
Resolve symbols of captured samples and backtraces.
Default is 'false' on Windows, 'true' on other platforms.
--retain-etw-files=
Possible values are 'true' or 'false'.
Retain ETW files.
If true, retains ETW files generated by the trace, merges and moves the files to the output directory.
Default is 'false'.
-s, --sample=
Possible values are 'process-tree', 'system-wide' or 'none'.
Collect CPU IP/backtrace samples. Select 'none' to disable sampling. 'process-tree' or 'system-wide' requires administrative privileges.
If a target application is launched, the default is 'process-tree', otherwise the default
is 'none'.
--sampling-frequency=
Specify sampling/backtracing frequency.
Minimum supported frequency is '100' (Hz).
Maximum supported frequency is '8000' (Hz).
Default is '1000' (Hz).
--session-new=
Start the collection in a new named session. The option argument represents the session
name.
The session name must start with an alphabetical character followed by printable or space
characters.
Any '%q{ENV_VAR}' pattern in the session name will be substituted with the value of the
environment variable.
Any '%h' pattern in the option argument will be substituted with the hostname of the system.
Any '%%' pattern in the option argument will be substituted with '%'.
--start-frame-index=
Start the recording session when the frame index reaches the frame number preceding the
start frame index. Minimum supported frame is '1'.
Note when it is selected cannot include any other start options.
If not specified the default is disabled. Application scope.
--stats=
Possible values are 'true' or 'false'.
Generate summary statistics after the collection.
When set to true, an SQLite database file will be created after the collection.
Default is 'false'.
--system-wide=
Possible values are 'true' or 'false'.
Perform system-wide injection using Windows hooks.
Equivalent to setting the --injection-use-detours option to the
inverse value.
Default is 'false'.
-t, --trace=
Possible values are 'cuda', 'cuda-hw', 'nvtx', 'cublas', 'cublas-verbose',
'cusolver', 'cusolver-verbose', 'cusparse', 'cusparse-verbose', 'opengl',
'opengl-annotations', 'nvvideo', 'vulkan', 'vulkan-annotations', 'dx11',
'dx11-annotations', 'dx12', 'dx12-annotations', 'openxr',
'openxr-annotations', 'wddm', 'python-gil' or 'none'.
Select the API(s) to trace. Multiple APIs can be selected, separated by commas only
(no spaces).
If '<api>-annotations' is selected, the corresponding API will also be traced.
If 'none' is selected, no APIs are traced.
Default is 'cuda,nvtx,opengl'. Application scope.
--vulkan-gpu-workload=
Possible values are 'individual', 'batch', 'none', 'true' or 'false'.
If individual or true, trace each Vulkan workload's GPU activity individually.
If batch, trace Vulkan workloads' GPU activity in vkQueueSubmit call batches.
If none or false, do not trace Vulkan workloads' GPU activity.
Note that this switch is applicable only when --trace=vulkan is specified.
Default is 'individual'. Application scope.
-w, --show-output=
Possible values are 'true' or 'false'.
If true, send target process's stdout and stderr streams to both the console and
stdout/stderr files which are added to the report file.
If false, only send target process stdout and stderr streams to the stdout/stderr files
which are added to the report file.
Default is 'true'.
--wait=
Possible values are 'primary' or 'all'.
If 'primary', the CLI will wait on the application process termination.
If 'all', the CLI will additionally wait on re-parented processes created by the
application.
Default is 'all'.
--wddm-additional-events=
Possible values are 'true' or 'false'.
If true, collect additional range of ETW events, including context status, allocations, sync wait and signal events, etc.
Requires administrative privileges.
Note that this switch is applicable only when --trace=wddm is specified.
Default is 'true'. System scope.
--wddm-backtraces=
Possible values are 'true' or 'false'.
If true, collect backtraces of WDDM events.
Requires administrative privileges.
Disabling this data collection can reduce overhead for target
applications that generate many DxgKrnl WDDM Events.
Note that this switch is applicable only when --trace=wddm is specified.
Default is 'false'.
-x, --stop-on-exit=
Possible values are 'true' or 'false'.
Stop profiling when the launched application exits.
If stop-on-exit=false, duration must be greater than 0.
Default is 'true'.
-Y, --start-later=
Possible values are 'true' or 'false'.
Delays collection indefinitely until the nsys start
command is executed for this session.
Enabling this option overrides the --delay option.
Default is 'false'.
-y, --delay=
Collection start delay in seconds.
Default is 0.
The output command with profile are same as before version, which does not contain the flags options for
-cudabacktrace and --python-backtrace
And this again in not matching with the User Guide of Nvidia Nsys 2025 version.
I am not able to identify why is this issue arising ?
–update 20-03
I am using it on Win11 system.
I reinstalled Nsight systems, but that did not make a difference. It shows the same documentation for --help as before.