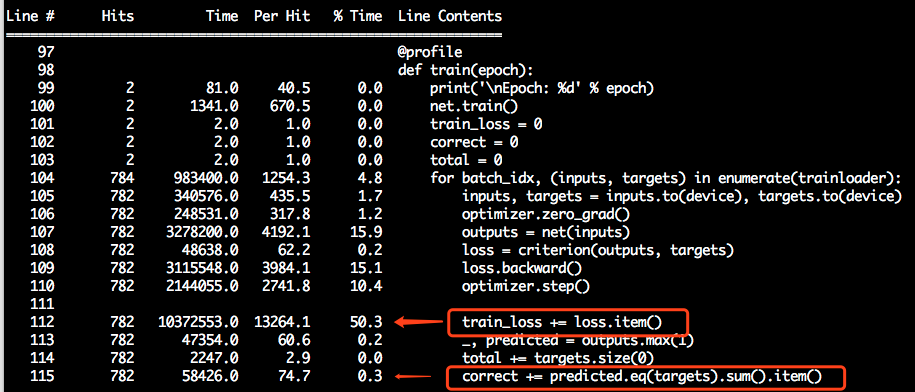
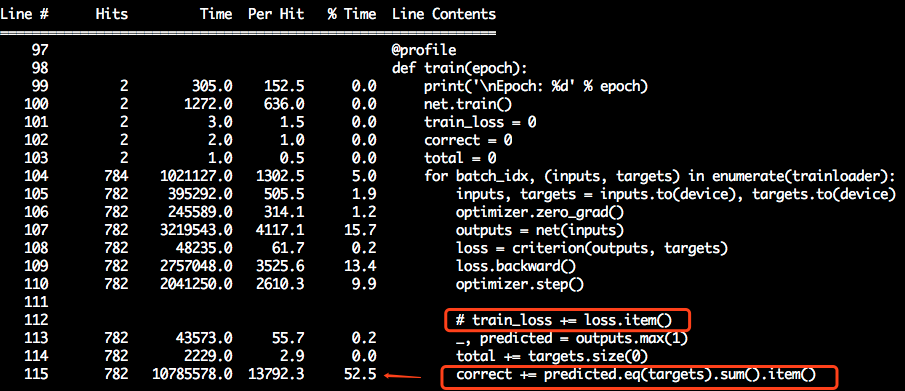
@ajbrock
kernprof seems tentatively quite nice 
Off-topic for this thread, but just cos I find it interesting, I get radically different timings on cpu vs gpu, I mean, different things are slow. On cpu, it looks like my bottleneck is tanh, interestingly,whereas on gpu, it’s matrix multiplicaiton.
Mac, CPU mode:
215 2585 40255 15.6 0.2 prev_dec_state = prev_dec_state.view(batch_size, hidden_size)
216 2585 182622 70.6 1.1 prev_dec_state_W = prev_dec_state @ self.W
217 2585 39752 15.4 0.2 enc_out_U = enc_out.view(seq_len * batch_size, hidden_size * 2) @ \
218 2585 3005655 1162.7 17.8 self.U.transpose(0, 1)
219 2585 53347 20.6 0.3 enc_out_U = enc_out_U.view(seq_len, batch_size, hidden_size)
220 2585 2367 0.9 0.0 prev_dec_state_W_exp = prev_dec_state_W \
221 2585 31246 12.1 0.2 .view(1, batch_size, hidden_size) \
222 2585 68789 26.6 0.4 .expand(seq_len, batch_size, hidden_size)
223 2585 2063555 798.3 12.2 x = enc_out_U + prev_dec_state_W_exp
224 2585 10745470 4156.9 63.7 x = F.tanh(x)
225 2585 304178 117.7 1.8 x = x.view(seq_len * batch_size, hidden_size) @ self.v.view(-1, 1)
226 2585 40751 15.8 0.2 x = x.view(seq_len, batch_size)
227 2585 32390 12.5 0.2 x = x.transpose(0, 1)
228 2585 243247 94.1 1.4 x = F.softmax(x)
tanh is slow 
on an aws p2, using cuda, and with some syncs thrown in, just to be sure (results are same without sync though, weirdly):
220 2541 48584 19.1 2.6 prev_dec_state = prev_dec_state.view(batch_size, hidden_size)
221 2541 211774 83.3 11.4 prev_dec_state_W = prev_dec_state @ self.W
222 2541 48346 19.0 2.6 enc_out_U = enc_out.view(seq_len * batch_size, hidden_size * 2) @ \
223 2541 225530 88.8 12.1 self.U.transpose(0, 1)
224 2541 46828 18.4 2.5 enc_out_U = enc_out_U.view(seq_len, batch_size, hidden_size)
225 2541 2511 1.0 0.1 prev_dec_state_W_exp = prev_dec_state_W \
226 2541 30299 11.9 1.6 .view(1, batch_size, hidden_size) \
227 2541 92212 36.3 5.0 .expand(seq_len, batch_size, hidden_size)
228 2541 96198 37.9 5.2 x = enc_out_U + prev_dec_state_W_exp
229 2541 223889 88.1 12.0 cuda_sync()
230 2541 170755 67.2 9.2 x = F.tanh(x)
231 2541 62406 24.6 3.4 cuda_sync()
232 2541 281476 110.8 15.1 x = x.view(seq_len * batch_size, hidden_size) @ self.v.view(-1, 1)
233 2541 45434 17.9 2.4 cuda_sync()
234 2541 48591 19.1 2.6 x = x.view(seq_len, batch_size)
235 2541 29989 11.8 1.6 x = x.transpose(0, 1)
236 2541 194787 76.7 10.5 x = F.softmax(x)
=> matrix multiplication dominates in this case
Hmmm, as I write, I’m wondering whether tanh is actually running multi-core, in the cpu version? Seems it might not be?