HI!
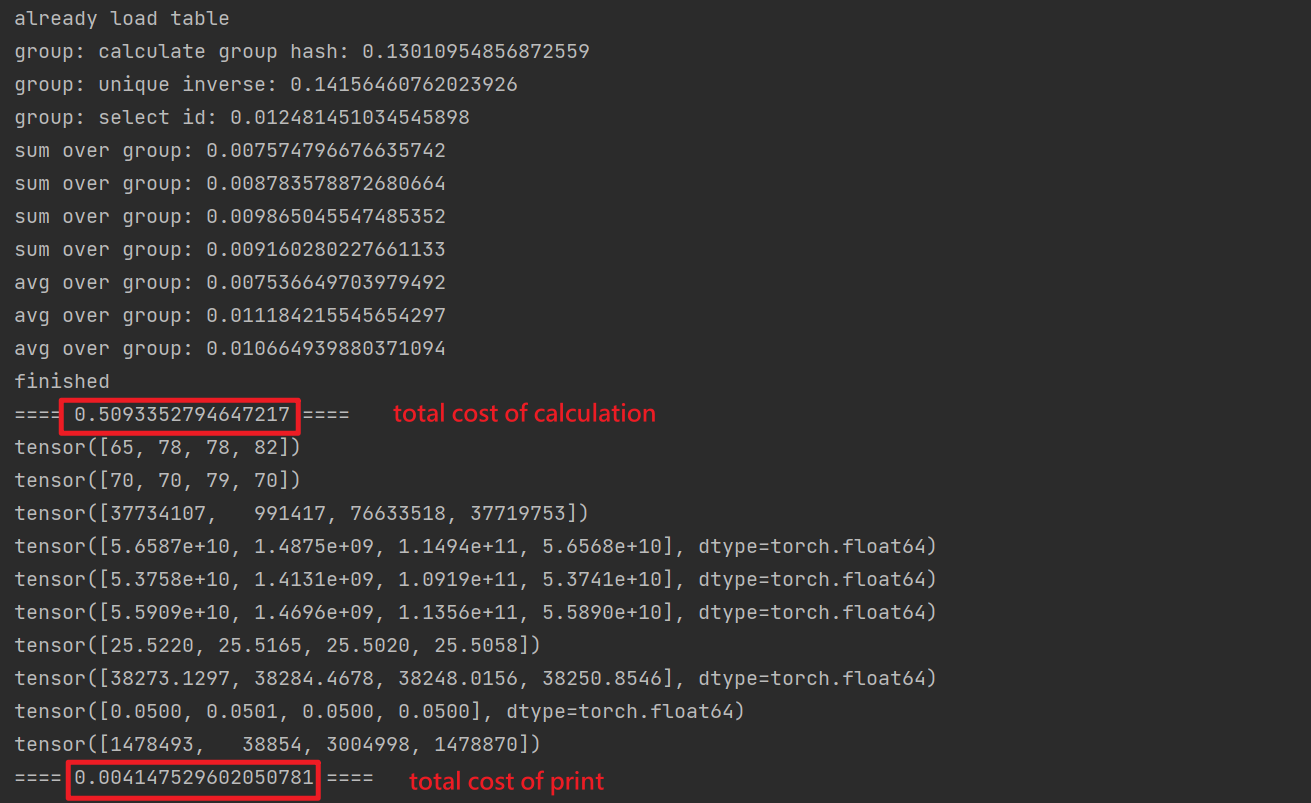
I’m trying to implement an algorithm using tensor operators, but I found a strange thing when I run my algorithm on cuda. The process can run very fast( It took only 50 ms to process inputs with a length of 6M). The length of result tensors are only 4, but printing these tensors cost me 30s!
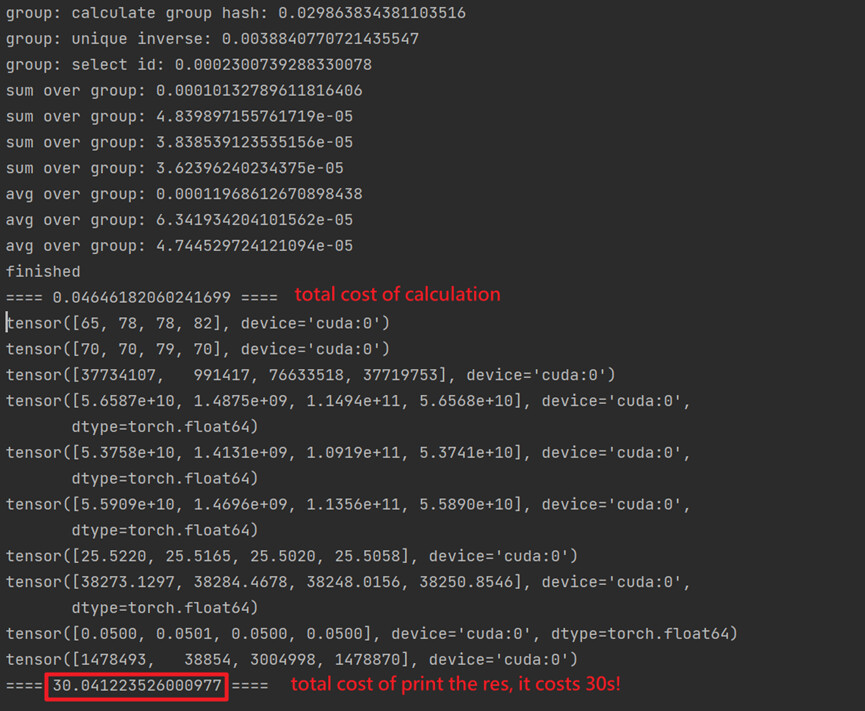
My result consists of 10 (1*4 ) tensors on cuda, when I try to print all these results, the program stuck for 30 seconds before printing the first tensor. and print the rest tensors in less than 1 ms.
When I set the device as ‘cpu’, this strange behavior does not happen.
And I found it is caused by the operator scatter_add(at line39 and line50). If I remove all scatter_add calls, the program behaves normally and prints all results without waiting.
If I try to print the result of every scatter_add immediately after its execution, the program will also freeze for 30s before doing anything. The unexpected freeze only occurred once even when I call the sccatter_add operator several times in the program, the freeze will occur immediately after the first call.
My code:
My Dataset:
Because my dataset is too big and github refuse to upload it, so I truncated and uploaded the first 200k lines of the dataset csv file.
How to reproduce:
please change the file path on line 57 to the real path on your own device.
the buggy scatter_add calls are at line 39 and line 50
my enviroment:
torch2.0 , pandas 1.5.3, cuda 11.7
please help me with this problem