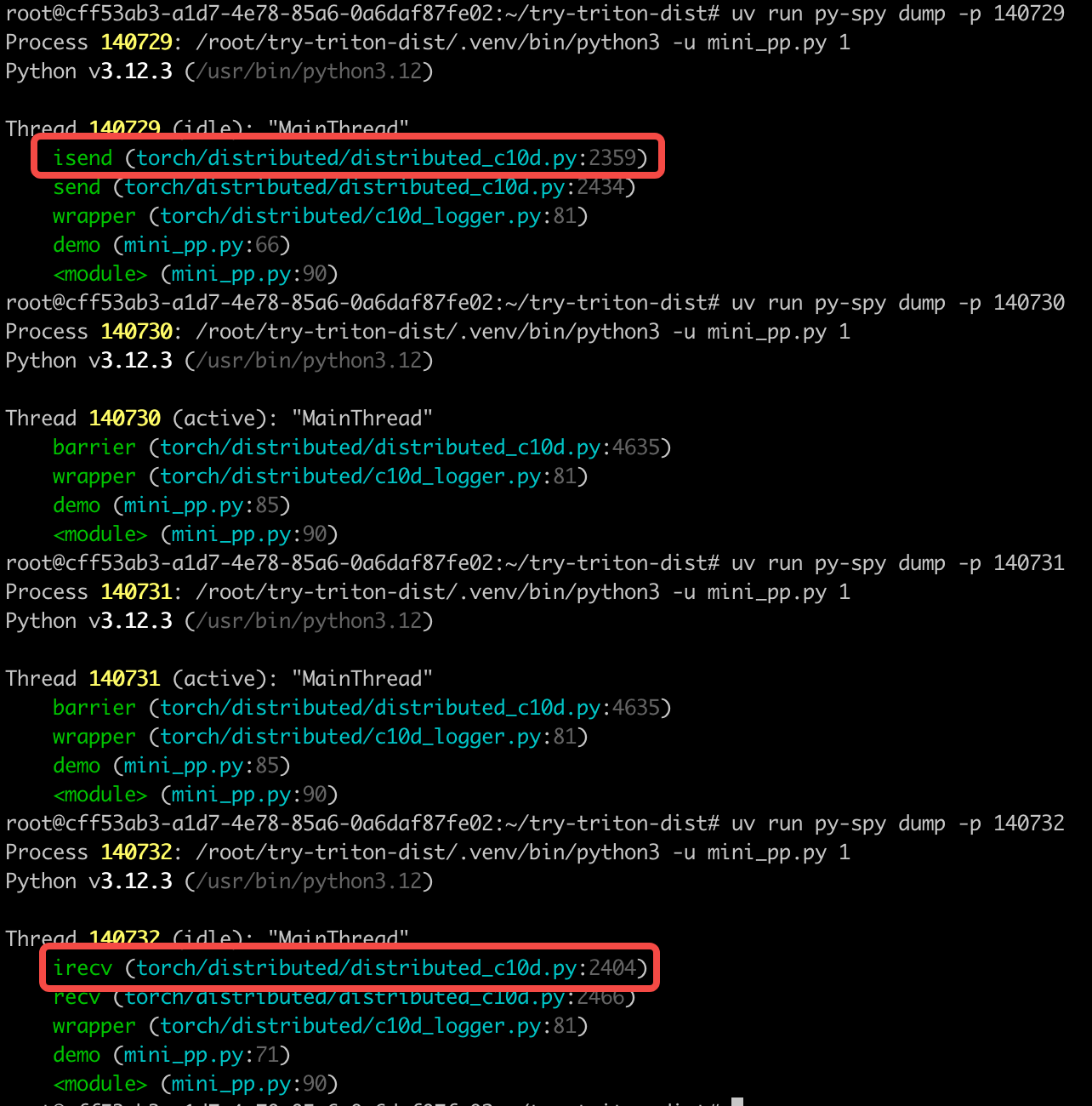
In the send/recv code below, only choice=2 works (when using the default group). Why don’t the other two options work?
`CUDA_LAUNCH_BLOCKING=1 uv run torchrun --nproc-per-node=4 mini_pp.py 0/1/2` to launch the code
import os
import sys
import torch
from torch.distributed.device_mesh import DeviceMesh, init_device_mesh
def init_distributed():
# Initializes the distributed backend
# which will take care of sychronizing nodes/GPUs
dist_url = "env://" # default
# only works with torch.distributed.launch // torch.run
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
local_rank = int(os.environ["LOCAL_RANK"])
# this will make all .cuda() calls work properly
torch.cuda.set_device(local_rank)
torch.distributed.init_process_group(
backend="nccl", init_method=dist_url, world_size=world_size, rank=rank,
device_id=torch.device(f"cuda:{torch.cuda.current_device()}"),
)
# synchronizes all the threads to reach this point before moving on
torch.distributed.barrier()
return world_size, rank, local_rank
def demo():
choice = int(sys.argv[1])
world_size, rank, local_rank = init_distributed()
device_mesh: DeviceMesh = init_device_mesh(
'cuda',
(world_size // 2, 2),
mesh_dim_names=('pp', 'tp'),
)
pp_mesh: DeviceMesh = device_mesh["pp"]
pp_group = pp_mesh.get_group()
# tp_mesh: DeviceMesh = device_mesh["tp"]
# tp_group = tp_mesh.get_group()
pp_rank = pp_group.rank()
# pp_size = pp_group.size()
device = torch.device(f"cuda:{torch.cuda.current_device()}")
dtype = torch.bfloat16
shape = (3, 1024)
if choice == 0: # get stuck
if pp_rank == 0:
hidden_states = torch.randn(shape, device=device, dtype=dtype)
torch.distributed.send(hidden_states, group_dst=pp_rank + 1, group=pp_group)
print(f"send {torch.distributed.get_global_rank(pp_group, pp_rank)}->{torch.distributed.get_global_rank(pp_group, pp_rank + 1)}")
else:
hidden_states = torch.empty(shape, device=device, dtype=dtype)
torch.distributed.recv(hidden_states, group_src=pp_rank - 1, group=pp_group)
print(f"recv {torch.distributed.get_global_rank(pp_group, pp_rank - 1)}->{torch.distributed.get_global_rank(pp_group, pp_rank)}")
elif choice == 1: # get stuck too
if pp_rank == 0:
hidden_states = torch.randn(shape, device=device, dtype=dtype)
group_dst = torch.distributed.get_global_rank(pp_group, pp_rank + 1)
torch.distributed.send(hidden_states, dst=group_dst, group=pp_group)
print(f"send {torch.distributed.get_global_rank(pp_group, pp_rank)}->{torch.distributed.get_global_rank(pp_group, pp_rank + 1)}")
else:
hidden_states = torch.empty(shape, device=device, dtype=dtype)
group_src = torch.distributed.get_global_rank(pp_group, pp_rank - 1)
torch.distributed.recv(hidden_states, src=group_src, group=pp_group)
print(f"recv {torch.distributed.get_global_rank(pp_group, pp_rank - 1)}->{torch.distributed.get_global_rank(pp_group, pp_rank)}")
else: # works
if pp_rank == 0:
hidden_states = torch.randn(shape, device=device, dtype=dtype)
group_dst = torch.distributed.get_global_rank(pp_group, pp_rank + 1)
torch.distributed.send(hidden_states, dst=group_dst)
print(f"send {torch.distributed.get_global_rank(pp_group, pp_rank)}->{torch.distributed.get_global_rank(pp_group, pp_rank + 1)}")
else:
hidden_states = torch.empty(shape, device=device, dtype=dtype)
group_src = torch.distributed.get_global_rank(pp_group, pp_rank - 1)
torch.distributed.recv(hidden_states, src=group_src)
print(f"recv {torch.distributed.get_global_rank(pp_group, pp_rank - 1)}->{torch.distributed.get_global_rank(pp_group, pp_rank)}")
torch.distributed.barrier()
print(f"rank {rank}, pp_rank {pp_rank}, hidden_states: {hidden_states}", flush=True)
if __name__ == "__main__":
demo()