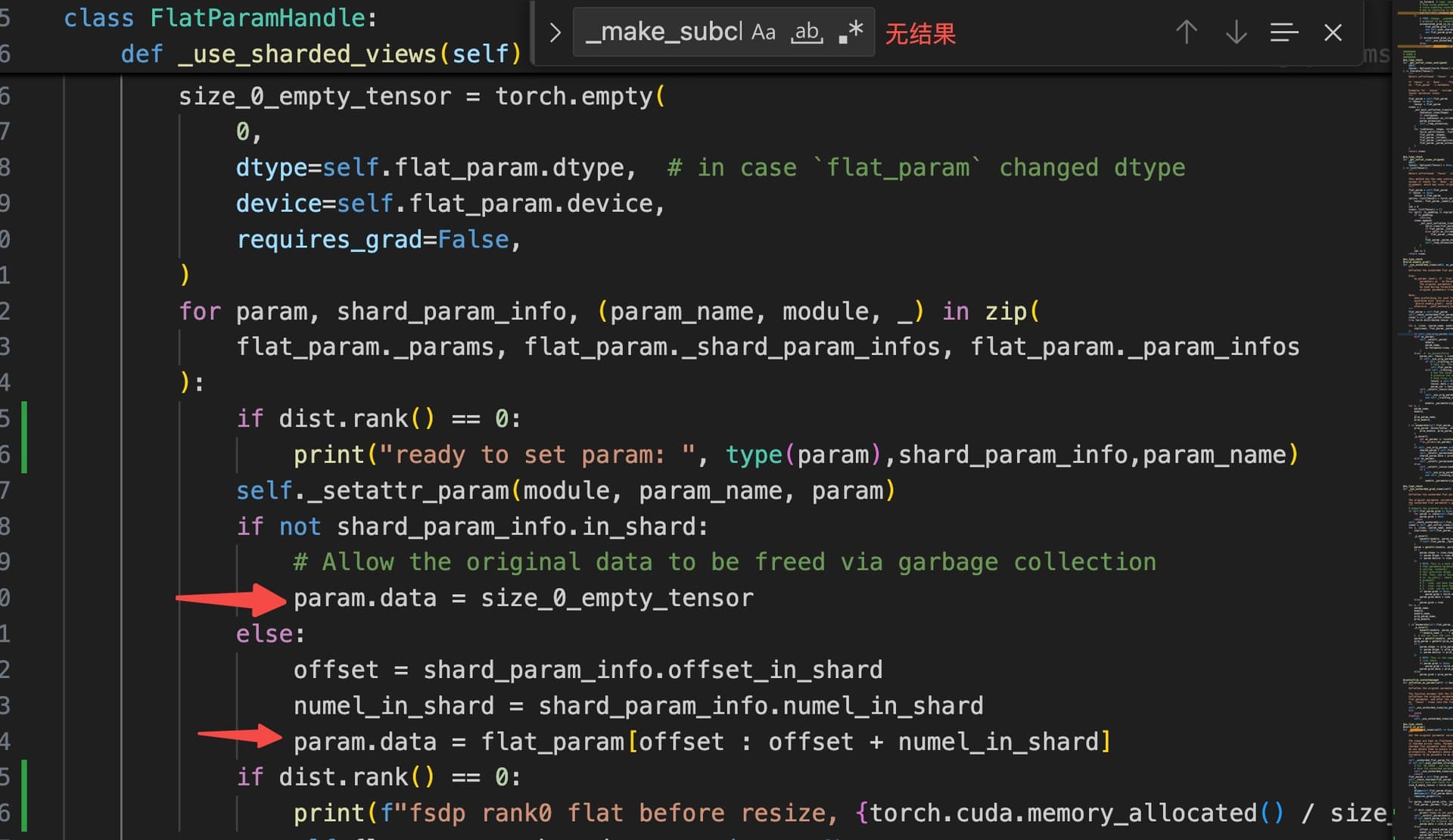
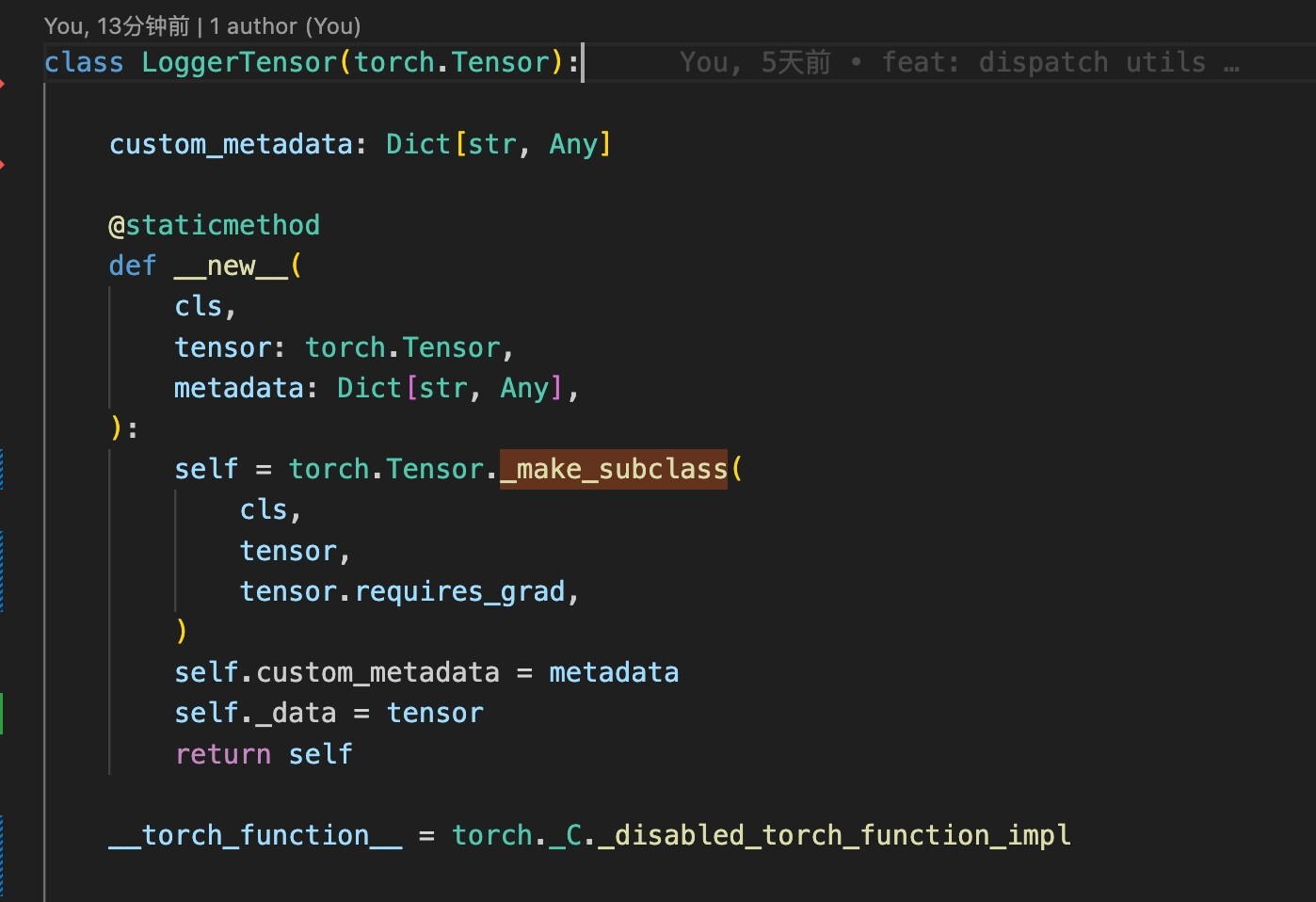
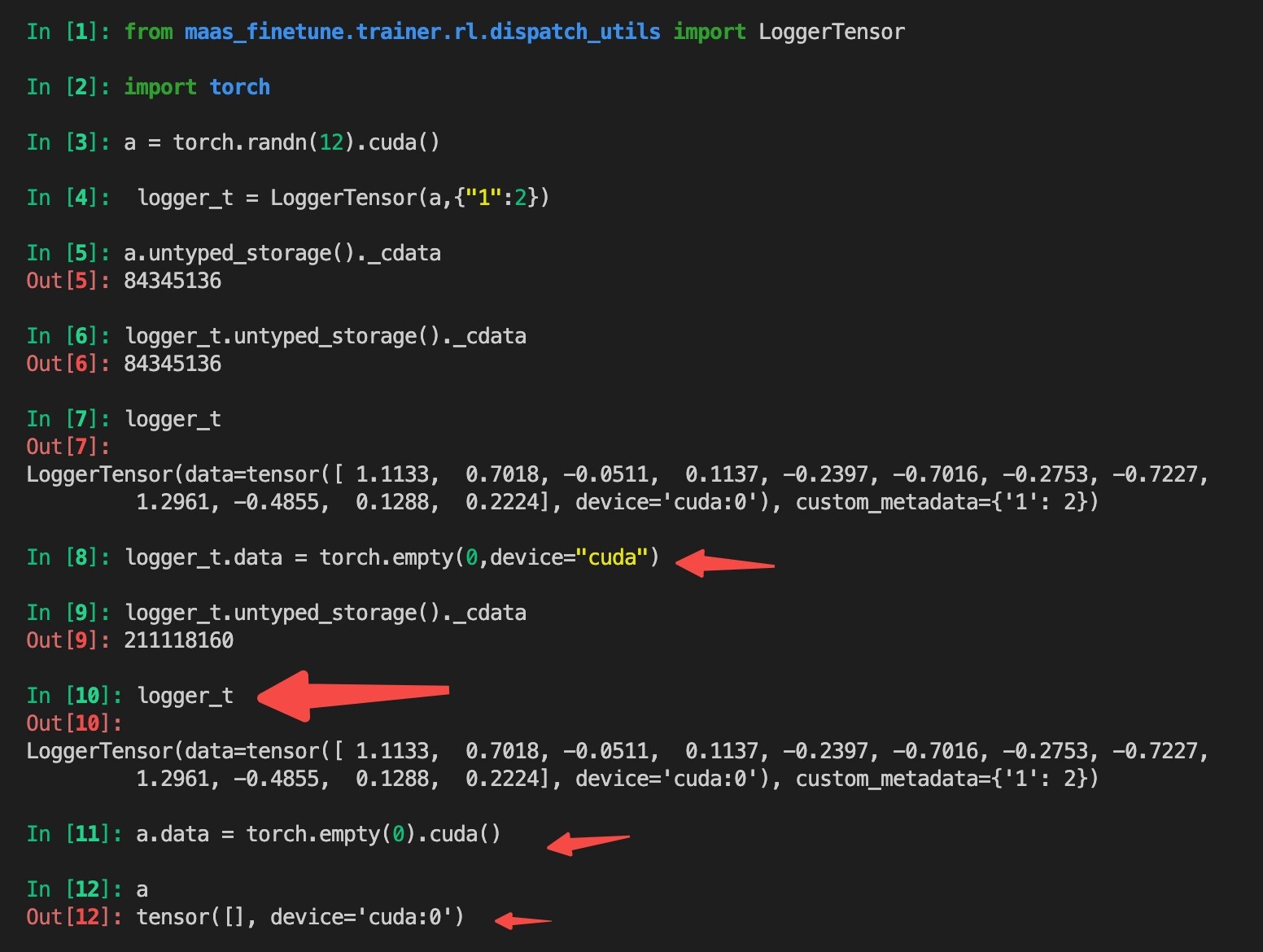
Currently FSDP replace param.data with a empty tensor to free memory.
but when the param is a tensor sub-class, like this
this way won’t work as following
what’s the best practice to integrate FSDP and tensor subclass? I saw d-tensor’s way by using FSDPExtension and unwrap the params, but that interface seems customized only for d-tensor
ptrblck
September 3, 2025, 10:41pm
2
Based on this tutorial for FSDP2 it seems one of the advantages between FSDP1 and FSDP2 is:
Offering a tensor subclass extension point to customize the all-gather, e.g. for float8 all-gather for float8 linears (doc ), and NF4 for QLoRA (doc )
so maybe this extension point might be useful for your use case as well.
1 Like
Thx for the advice!
But I’m not able to use FSDP2 right now, so I switch another way using torch_dispatch to do so, but FSDP2 should be a better way.