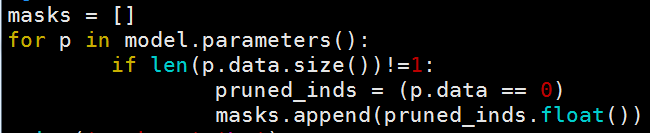
I am trying to implement weight pruning using forward hook, but somehow it is giving me invalid syntax, below is the code
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# this code implements pruning using register buffer feature to save input mask
def compute_mask(weights):
thresh = weights.std()
m1 = weights > thresh
m2 = weights < (-thresh)
mask = torch.ones(weights.size())
mask = mask-m1.float()
mask = mask-m2.float()
return mask
class PrunedSqueezenet(nn.Module):
def __init__(self, to_prune, pretrained_weight):
"""
takes a list of layers to prune, model, weights
to_prune: a list of all the layers on which pruning should be applied
model: architecture of the model
weights: pretrained weights to use for the model
"""
super(self, PrunedSqueezenet).__init__()
self.to_prune = to_prune
# get the model ready
self.base_model = model.SqueezeNet()
pretrained_weights = torch.load(pretrained_weight)
base_model.load_state_dict(pretrained_weights)
self.layers = self.base_model._modules.keys()
# compute the mask for the weights
for l in to_prune:
if "fire" in l:
curr_layer = self.base_model._modules.get(l)._modules.get('conv3')
weights = curr_layer.weight.data
# save the mask
curr_layer.register_buffer('mask', compute_mask(weights))
# change the computed output of conv3 layer in the fire
curr_layer.register_forward_hook(
lambda m, i, o: \
print("Hello this is ok")
)
elif "conv" in l:
curr_layer = self.base_model._modules.get(l)
weights = curr_layer.weight.data
# save the mask
curr_layer.register_buffer('mask', compute_mask(weights))
# change the computed output of conv3 layer in the fire
curr_layer.register_forward_hook(
lambda m, i, o: \
print("Hello this is ok"))
)
else:
print("I dont understand what you are talking about")
def forward(self, x):
return self.base_model(x)
if __name__ == '__main__':
net = PrunedSqueezenet(to_prune=['fire9'], pretrained_weight='pretrained_models/squeezedet_compatible.pth')
x = Variable(torch.randn(1, 3, 32, 32))
print(net(x))
I solved it, it was some python syntax error. Sorry for the trouble.
But I do have a logical question in “pruning”. So my line of thinking is I will compute mask for the specified layers and store it as the layer buffer and then implement a hook which will multiply the weight matrix with the mask thus essentially making the weights zero at that position.
And hence they will not contribute to the output… The question is whether this hook is applied after the forward of the layer or before, because in my before will make sense.
If this thinking is not right direction, would you please suggest me a way to achieve the desired behaviour?
I’m in a similar situation where I need to mask weights during forward(). I cannot set them to zero initially because the weight_mask gets updated every iteration based on the values of the weights and the gradients during backprop update all the weights (not just the unpruned ones).
Any suggestions on how I could do that short of creating new layers?
hello, i am interesting in your code. I have a question : how can i retrain a neural network without change some fixed weight? Hope for you reply! thanks!!!
One method is to use a method to mask the gradients after backward() call and before step(). I use that one in my code.
A second method could be doing the same with backwardhooks; where you use module.register_backward_hook() to mask the gradients. You can have a flag in your wrapper module like is_masked=True/False and then you can check that flag first thing in your hook: if module.is_masked: do masking else: pass
One tricky thing is to reinitialize your optimizer or gradient history of it after each update on your mask to prevent momentum to come into play.
hello, i am sorry to disturb you again. i have the same question:
I set a masks= to save which weight equal to zero and don’t change these weights.
second, i set them to variable which needn’t grad
Efficient way of doing this is having byte_tensor mask with same size as the original .weight tensor. So you can just remove .float() casting. Your mask would have ones for pruned weights. You don’t need a Variable of masks. You can just use the masks for indexing like below for example.
loss.backward()
for layer,mask in zip(X,Y):
layer.weight.grad.data[mask]=0
optimizer.step()
You just need to keep track which mask belongs to which weight. That’s MaskedModule wrapper is doing in the code I shared above.
I have a question about your code. whether the loss.backward() calculate zeroed weight? my purpose is when call the loss.backward(), zeroed weight don’t participate in backpropagation. sorry to disturb you again:blush:
I have a question about your code. whether the loss.backward() calculate zeroed weight? my purpose is when call the loss.backward(), zeroed weight don’t participate in backpropagation. sorry to disturb you again