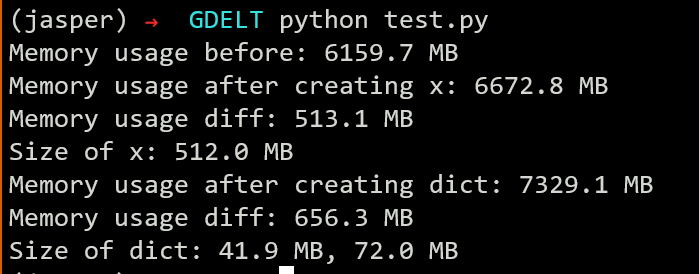
We would like to ask a question about python and pytorch. We found that putting a tensor into a container like list or dict row by row will cause a much larger memory overhead (double to quadruple the size of the tensor itself). But we confirmed by comparing data_ptr that the container contains reference of storage instead of copy of storage. And we also confirmed that the size of container itself is not too big. So we are wondering where the memory is going. Is there any method to identity?
Here is the reproducible script.
import sys
import psutil
import torch
MB = 10 ** 6
N = 10 ** 6
def get_memory_usage():
return psutil.virtual_memory().used / MB
def main():
m1 = get_memory_usage()
print("Memory usage before: {:.1f} MB".format(m1))
x = torch.randn(N, 128)
m2 = get_memory_usage()
print("Memory usage after creating x: {:.1f} MB".format(m2))
print("Memory usage diff: {:.1f} MB".format(m2 - m1))
print("Size of x: {:.1f} MB".format(x.element_size() * x.nelement() / MB))
d = {}
for i in range(len(x)):
d[i] = x[i]
for i in range(len(x)):
assert d[i].data_ptr() == x[i].data_ptr(), "Data pointer mismatch"
m3 = get_memory_usage()
print("Memory usage after creating dict: {:.1f} MB".format(m3))
print("Memory usage diff: {:.1f} MB".format(m3 - m2))
# size of dict
print("Size of dict: {:.1f} MB, {:.1f} MB".format(
sys.getsizeof(d) / MB, len(d) * sys.getsizeof(d[0]) / MB))
if __name__ == "__main__":
main()