Hello, I’m currently working on a graphical neural network project to predict results of soccer matches. I’ve trained the model with about 4000 matches, but the train loss of it only dropped by 0.05
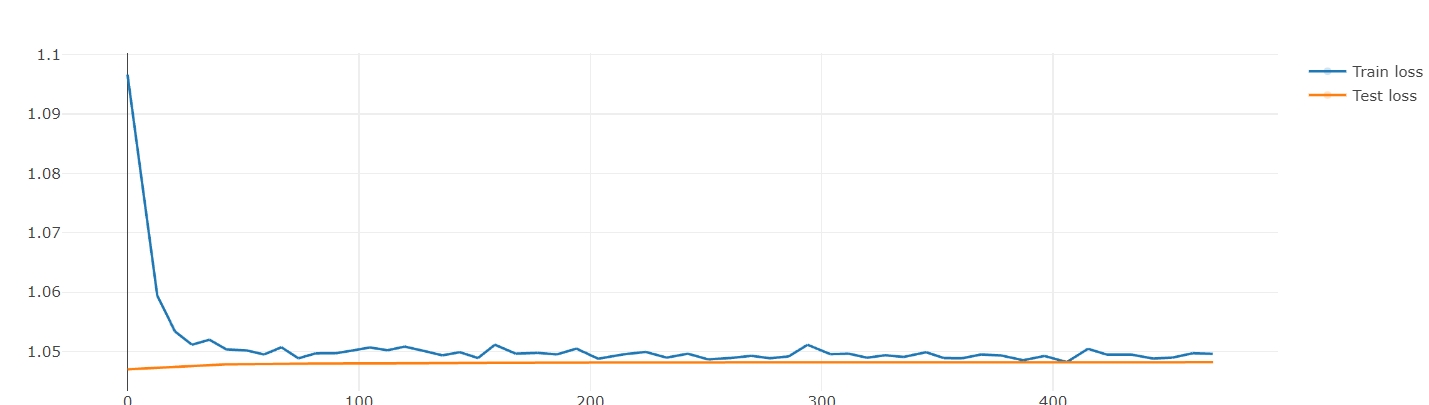
It seems like I’ve made some mistakes when building my models?
I’m new to pytorch pls spare me if there’s some stupid mistakes. Or if you need any more details on my project for further inspect.
Any help appreciated!
class GNN(torch.nn.Module):
def __init__(self, feature_size, model_params):
super(GNN, self).__init__()
embedding_size = model_params["model_embedding_size"]
n_heads = model_params["model_attention_heads"]
self.n_layers = model_params["model_layers"]
dropout_rate = model_params["model_dropout_rate"]
top_k_ratio = model_params["model_top_k_ratio"]
self.top_k_every_n = model_params["model_top_k_every_n"]
dense_neurons = model_params["model_dense_neurons"]
#edge_dim = model_params["model_edge_dim"]
self.conv_layers = ModuleList([])
self.transf_layers = ModuleList([])
self.pooling_layers = ModuleList([])
self.bn_layers = ModuleList([])
# Transformation layer: transform original node features to embedding vector(size: embedding_size(defined in config.py))
self.conv1 = TransformerConv(feature_size,
embedding_size,
heads=n_heads,
dropout=dropout_rate,
#edge_dim=edge_dim,
beta=True)
self.transf1 = Linear(embedding_size*n_heads, embedding_size)
self.bn1 = BatchNorm1d(embedding_size)
# Other layers: message passing and pooling
for i in range(self.n_layers):
self.conv_layers.append(TransformerConv(embedding_size,
embedding_size,
heads=n_heads,
dropout=dropout_rate,
#edge_dim=edge_dim,
beta=True))
# map conv_layer output size back to emgedding_size(embedding_size*n_heads -> embedding_size)
self.transf_layers.append(Linear(embedding_size*n_heads, embedding_size))
# Batch normalization
self.bn_layers.append(BatchNorm1d(embedding_size))
# Top-k pooling to reduce the size of the graph
if i % self.top_k_every_n == 0:
self.pooling_layers.append(TopKPooling(embedding_size, ratio=top_k_ratio))
# Linear output layers: feed graph representation in & reduce until single value left
self.linear1 = Linear(embedding_size*2, dense_neurons)
self.linear2 = Linear(dense_neurons, int(dense_neurons/2))
#self.linear3 = Linear(int(dense_neurons/2), 1)
self.linear3 = Linear(int(dense_neurons/2), 3) # same as the general form
def forward(self, x, edge_index, batch_index):
#def forward(self, x, edge_attr=None, edge_index, batch_index):
# Initial transformation
#x = self.conv1(x, edge_index, edge_attr)
x = self.conv1(x, edge_index)
x = torch.relu(self.transf1(x))
x = self.bn1(x)
# Holds the intermediate graph representations
global_representation = []
for i in range(self.n_layers):
#x = self.conv_layers[i](x, edge_index, edge_attr)
x = self.conv_layers[i](x, edge_index)
x = torch.relu(self.transf_layers[i](x))
x = self.bn_layers[i](x)
# Always aggregate last layer
if i % self.top_k_every_n == 0 or i == self.n_layers:
x , edge_index, edge_attr, batch_index, _, _ = self.pooling_layers[int(i/self.top_k_every_n)]( x,
edge_index,
None,
batch_index)
# Add current representation
global_representation.append(torch.cat([gmp(x, batch_index), gap(x, batch_index)], dim=1))
x = sum(global_representation) ######
# Output block
x = torch.relu(self.linear1(x))
x = F.dropout(x, p=0.8, training=self.training)
x = torch.relu(self.linear2(x))
x = F.dropout(x, p=0.8, training=self.training)
x = self.linear3(x)
return x