I had originally created this post on stackoverflow, though I should probably posed the question here first.
I’ve been struggling with understanding/implementing a pyTorch neural net model using pyro. Examples from the documentation don’t exactly paint a picture for what is going on inside the Predictive model. I’ve been able to use the examples to get a functioning model/guide however when I try to implement for my use case it’s not clear how to adjust in order to properly implement a solution.
Basic sticking points…
- How does the
Predictivemodel use both themodelandguide? - Examples using
Predictiveshow retrieving the result from theobssample (which is in the model, not the guide). - Since the
obssample is in fact apyro.sampleobject, should I simply draw N samples from theobssample? Or should I run the model N times to generate all the results since the weights/bias values for my network are alsopyro.sampleobjects?
As an example…
I have a dataset with features and targets grouped into discrete bins [0.0, 0.25, 0.5, 0.75, 1.0]
I would like to categorize the samples to accurately determine if a sample’s target value is either 0.0 or 1.0 (ignoring the other target values for the time being). Ultimately I want to use the logits from the model prediction to determine if a sample is a 0.0 or a 1.0 or use the logits as a confidence value and determine a single continuous value between the two targets.
When no longer training and performing evaluation I would like to normalize the features for the batch of samples, so I have a normalization performed if the model is not in train mode.
I would then like my final prediction to be a continuous value between 0.0-1.0. I am really only interested in accurately predicting the 0.0 and 1.0 values, however I would then like to establish the other values as a likelihood between 0.0-1.0, so I am using a OneHot encoding with 2 values per output. [1.0, 0.0] being the likelihood my sample is a 0.0 and the [0.0, 1.0] being a likelihood my sample is a 1.0. I then average all the votes from obs to determine where this sample lies between 0 and 1.
While this seems to work, I feel like I’m probably being very inefficient.
After training, why do I need to create a Predictive instance of my model? since the weights and bias of the network are also sampled parameters, could I also simply run a prediction multiple times? In the Predictive instance, what is actually being used for the weight/bias values of the network. Do the come from the model or do they come from the guide?
Here I am trying to make use of pyro.nn.PyroModule, however I had trouble getting this to work with AutoGuide so I’m attempting to create my own guide() method within my model.
import torch
import pyro
from pyro.infer import SVI, Trace_ELBO, Predictive
# Pyro Linear Layer Class
# Used to create a fully connected linear layer with Normally distributed weights
# and bias where mu/sigma become a learnable parameter
class PyroLinear(torch.nn.Linear, pyro.nn.PyroModule): # used as a mixin
def __init__(self, in_features, out_features, device='cpu', **kwargs):
super().__init__(in_features, out_features, **kwargs)
mu = torch.randn_like( self.weight, device=device)
sigma = torch.rand_like( self.weight, device=device) + 0.01
self.weight = pyro.nn.PyroSample( pyro.distributions.Normal( mu, sigma).expand([self.out_features, self.in_features]).to_event(2))
if self.bias is not None:
mu = torch.randn_like( self.bias, device=device)
sigma = torch.rand_like( self.bias, device=device) + 0.01
self.bias = pyro.nn.PyroSample( pyro.distributions.Normal( mu, sigma).expand([self.out_features]).to_event(1))
#
# helper function to return a fully connected pyro layer with ReLU activation
def layer_block( n_in, n_out, device='cpu'):
return pyro.nn.PyroModule[ torch.nn.Sequential](
PyroLinear(n_in, n_out, device=device),
torch.nn.ReLU()
)
#
# Full NNet model with guide method
class NNet_Model(pyro.nn.PyroModule):
def __init__(self, n_inputs=1, n_outputs=1, h_layers=[20], device='cpu'):
super().__init__()
self.n_outputs = n_outputs
self.layer_sizes = [n_inputs, *h_layers]
layer_blocks = [ layer_block(in_f, out_f, device=device) for in_f, out_f in zip(self.layer_sizes[:-1], self.layer_sizes[1:])]
self.feature_net = pyro.nn.PyroModule[ torch.nn.Sequential](*layer_blocks)
self.out = PyroLinear( self.layer_sizes[ -1], n_outputs, device=device)
def forward(self, x, y=None):
#
# Normalize the batch if this is being run for an eval() prediction
if not self.training:
x = (x - x.mean( axis=0)) / (x.std( axis=0) + 1e-6)
x = self.feature_net( x)
pred_logits = self.out( x)
obs = pyro.sample("obs", pyro.distributions.OneHotCategorical(logits=pred_logits).to_event(1), obs=y)
return pred_logits
#
# The guide. This seems to work even though it does not return anything
# - I'm not sure what it should return since the model is generating
# the pred_logits.
def guide(self, x, y=None):
#
# Create a pyro.param for each mu/sigma of the weights/bias of feature_net
for i in range(0, len( self.feature_net)):
mu = torch.randn_like( self.feature_net[i][0].weight)
sigma = torch.rand_like( self.feature_net[i][0].weight) + 0.1
mu_param = pyro.param( f"feature_net.{i}.0.w_mu", mu)
sigma_param = pyro.param( f"feature_net.{i}.0.w_sigma", sigma, constraint=pyro.distributions.constraints.positive)
_ = pyro.sample( f"feature_net.{i}.0.weight", pyro.distributions.Normal(mu_param, sigma_param).expand([self.feature_net[i][0].weight.size(0), self.feature_net[i][0].weight.size(1)]).to_event(2))
mu = torch.randn_like( self.feature_net[i][0].bias)
sigma = torch.rand_like( self.feature_net[i][0].bias) + 0.1
mu_param = pyro.param( f"feature_net.{i}.0.b_mu", mu)
sigma_param = pyro.param( f"feature_net.{i}.0.b_sigma", sigma, constraint=pyro.distributions.constraints.positive)
_ = pyro.sample( f"feature_net.{i}.0.bias", pyro.distributions.Normal(mu_param, sigma_param).expand([self.feature_net[i][0].bias.size(0)]).to_event(1))
#
# Create pyro.param for the mu/sigma of the weights/bias of the output layer
mu = torch.randn_like( self.out.weight)
sigma = torch.rand_like( self.out.weight) + 0.1
mu_param = pyro.param( f"out.w_mu", mu)
sigma_param = pyro.param( f"out.w_sigma", sigma, constraint=pyro.distributions.constraints.positive)
_ = pyro.sample( f"out.weight", pyro.distributions.Normal(mu_param, sigma_param).expand([self.out.weight.size(0), self.out.weight.size(1)]).to_event(2))
mu = torch.randn_like( self.out.bias)
sigma = torch.rand_like( self.out.bias) + 0.1
mu_param = pyro.param( f"out.b_mu", mu)
sigma_param = pyro.param( f"out.b_sigma", sigma, constraint=pyro.distributions.constraints.positive)
_ = pyro.sample( f"out.bias", pyro.distributions.Normal(mu_param, sigma_param).expand([self.out.bias.size(0)]).to_event(1))
Here I create a simple set of fake training data…
n_features = 9
n_samples = 1000
DEVICE='cpu'
feature_data = torch.tensor( np.random.choice( classes, (n_samples, n_features))).type( torch.float32)#.to( DEVICE)
f_idxs = np.arange(0, n_features)
t_build = feature_data[ :, np.random.choice( f_idxs, (1))] - feature_data[ :, np.random.choice( f_idxs, (1))] + feature_data[ :, np.random.choice( f_idxs, (1))]
target_data = torch.maximum( torch.minimum( t_build, torch.tensor( 1.0)), torch.tensor( 0.0))#.to( DEVICE)
#
# Split into train/test groups.
# - normalize the training feature data
train_feature_data = feature_data[ 0:800, :]
train_feature_data = (train_feature_data - train_feature_data.mean( axis=0)) / ( train_feature_data.mean( axis=0) + 1e-6)
train_target_data = target_data[ 0:800, :]
test_feature_data = feature_data[ 800:, :]
test_target_data = target_data[ 800:, :]
#
# Now select only the data with target values of 0.0 or 1.0
train_feature_01_data[ ((train_target_data==1.0) | (train_target_data==0.0)).view( -1), :]
train_target_01_data[ ((train_target_data==1.0) | (train_target_data==0.0)).view( -1), :]
Train model on the train_feature_01_data and train_target_01_data…
pyro.clear_param_store()
#
# I am using OneHot encoding, however I am only interested in predicting the 0,1 values so I am only outputting 2 values.
model = NNet_Model( n_inputs=n_features, n_outputs=2, h_layers=[ 10000], device=DEVICE)
adam = pyro.optim.Adam({"lr": 4e-3})
svi = SVI(model, guide=model.guide, optim=adam, loss=Trace_ELBO())
y = torch.nn.functional.one_hot( (train_target_data.view(-1)).type(torch.long), num_classes=2)
losses = []
for epoch in range(0, 200000):
loss = svi.step( train_feature_01_data, y)
losses.append( loss)
print(f'loss={loss:.4f}', end='\r')
After training, I create a Predictive instance of my model to test on the test_feature_data against the test_target_data which comprise all target values [0.0, 0.25, 0.5, 0.75, 1.0]
predictive_model = Predictive(model, guide=model.guide, num_samples=1000)
preds = predictive_model( test_feature_data)
now preds[ 'obs'] contains 1000 OneHot predictions for each sample. To boil it down to a final prediction I average the predictions per sample ( using argmax to determine whether the sample is a 0.0 label or a 1.0 label…
final_pred = preds[ 'obs'].argmax( axis=2).type( torch.float).mean(axis=0)
I then sort the values based on the test_target_data so that it is easier to identify on a line chart.
values, idxs = test_target_data.view( -1).sort()
plt.plot( test_target_data.view( -1)[ idxs].numpy(), label="target")
plt.plot( final_pred.view( -1)[ idxs].numpy(), label="Prediction")
plt.legend()
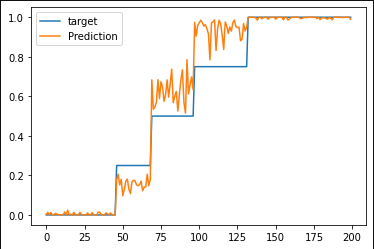
As you can see, for the most part it does seem to organize even the middle values to their proper space, though it has trouble with targets that are in the 0.75 range. But this is just my random simple test data.
I would very much appreciate any clues as to how to properly build/train/save a pyro.nn.PyroModule style model. I have found it tricky to get it to/from the GPU and, ultimately, for the final Predictive model I need to run on the CPU because my GPU cannot handle the obs tensor with 1000 samples per row of data. My workarounds for this seem to do the trick, but it feels clumsy.
Mainly I would like to know what the best method for saving and re-using a model is once it has gone through training.
is generating a Predictive model from the original model and guide essentially the same as generating predictions n-times from the original model? How does the guide factor into the final predicting process?